The Integration of Nature-Inspired Algorithms with Least Square Support Vector Regression Models: Application to Modeling River Dissolved Oxygen Concentration

 ,
, 
 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
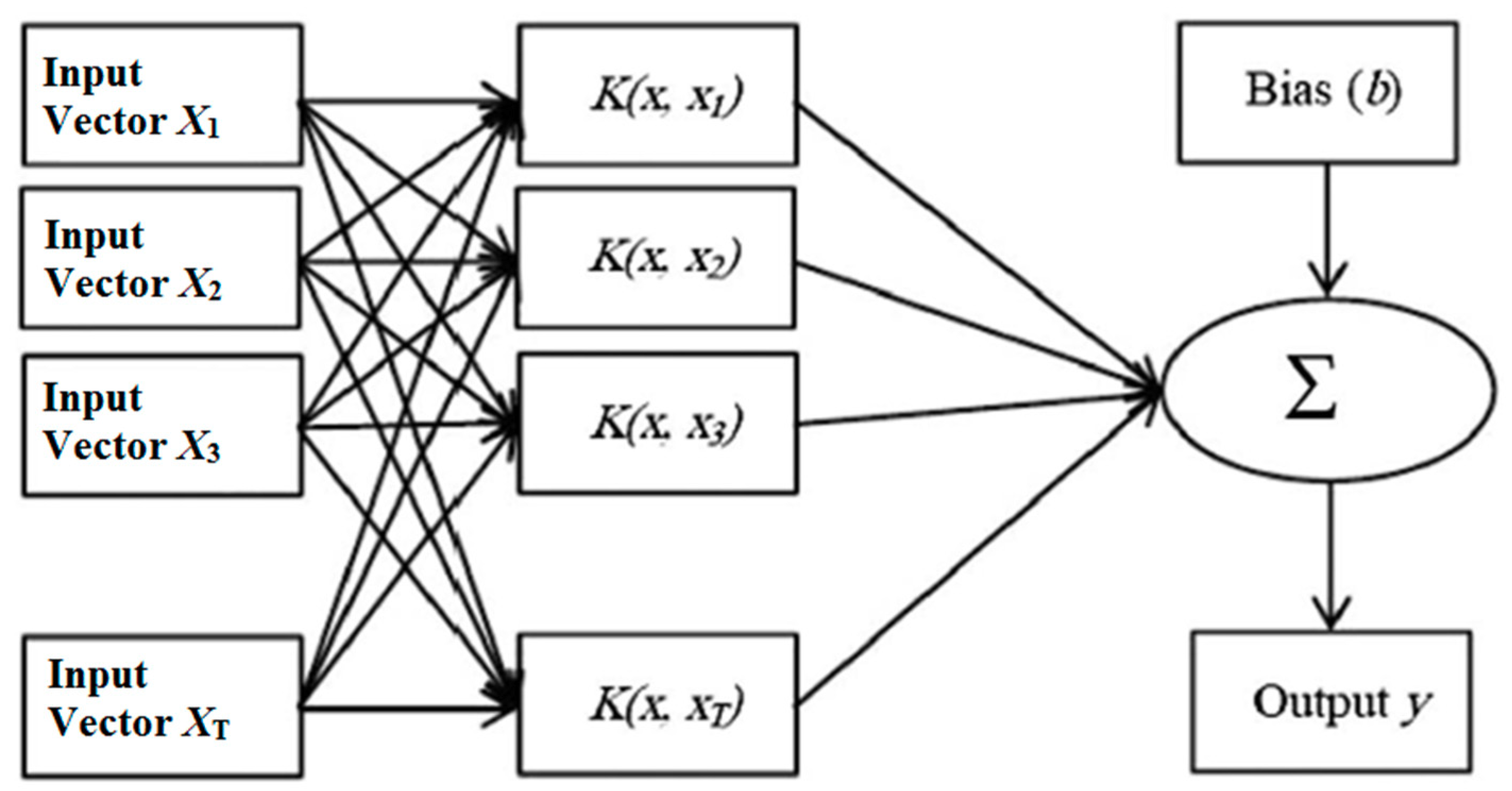
2.1. LSSVM
2.2. Bat Algorithm
- All bats use the echolocation ability for the identification of prey based on received sounds from the surroundings.
- Each bat has random velocity () at the position and the loudness, wavelength, and frequency of received sounds are , , and , respectively.
- The loudness varies from a large positive value to a minimum value.
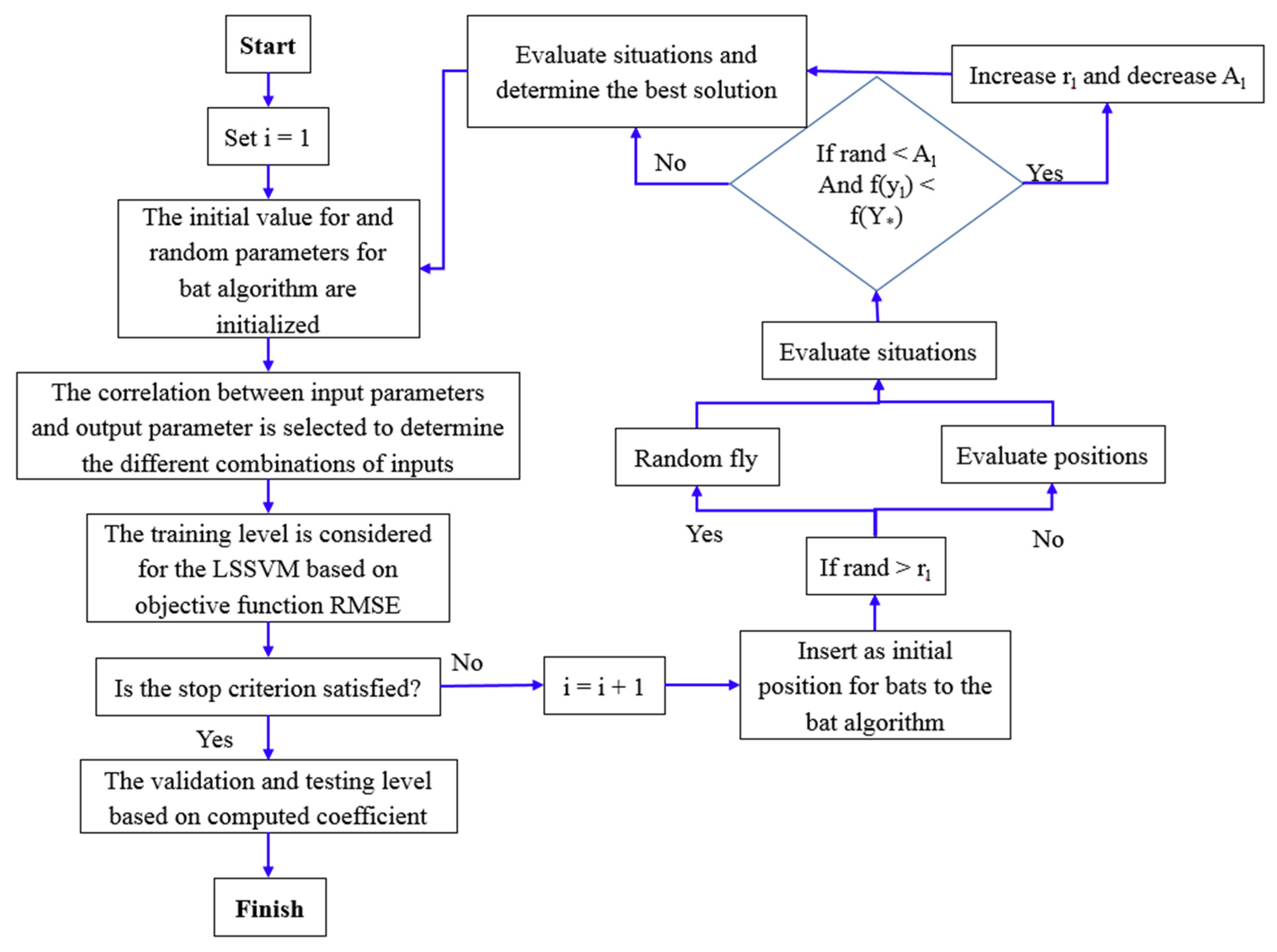
2.3. LSSVM-BA Algorithm
- The bats’ positions are considered as decision variables and the values of
- The initial values for the random parameters in the bat algorithm and and parameters are initialized in the first level.
- A counter number is considered for this level, such as in Figure 2.
- The kind of kernel function and the inputs and output are selected and the correlation between inputs and output is measured to determine the effective combination of inputs.
- The model is trained, and the performance of the method is evaluated based on objective function such as RMSE.
- The stop criterion is checked and if it is satisfied, the algorithm is shifted to the validation and testing phases and the results based on extracted parameters of and are considered for making a decision on the continuation of the method.
- The values of and as initial positions of bats are inserted into the bat algorithm. In fact, they are considered as decision variables.
- If rand > rl is considered, the positions based on objective functions are evaluated; otherwise, the random fly is considered and shifted to the next level.
- If rand < Al and f(yl) < f() is considered, the rl is increased and Al is decreased; otherwise, the bats’ situations are evaluated and switched to next level.
- One number is added to the counter and then switched to the third level.
2.4. M5 Tree
2.5. Multivariate Adaptive Regression Spline (MARS)
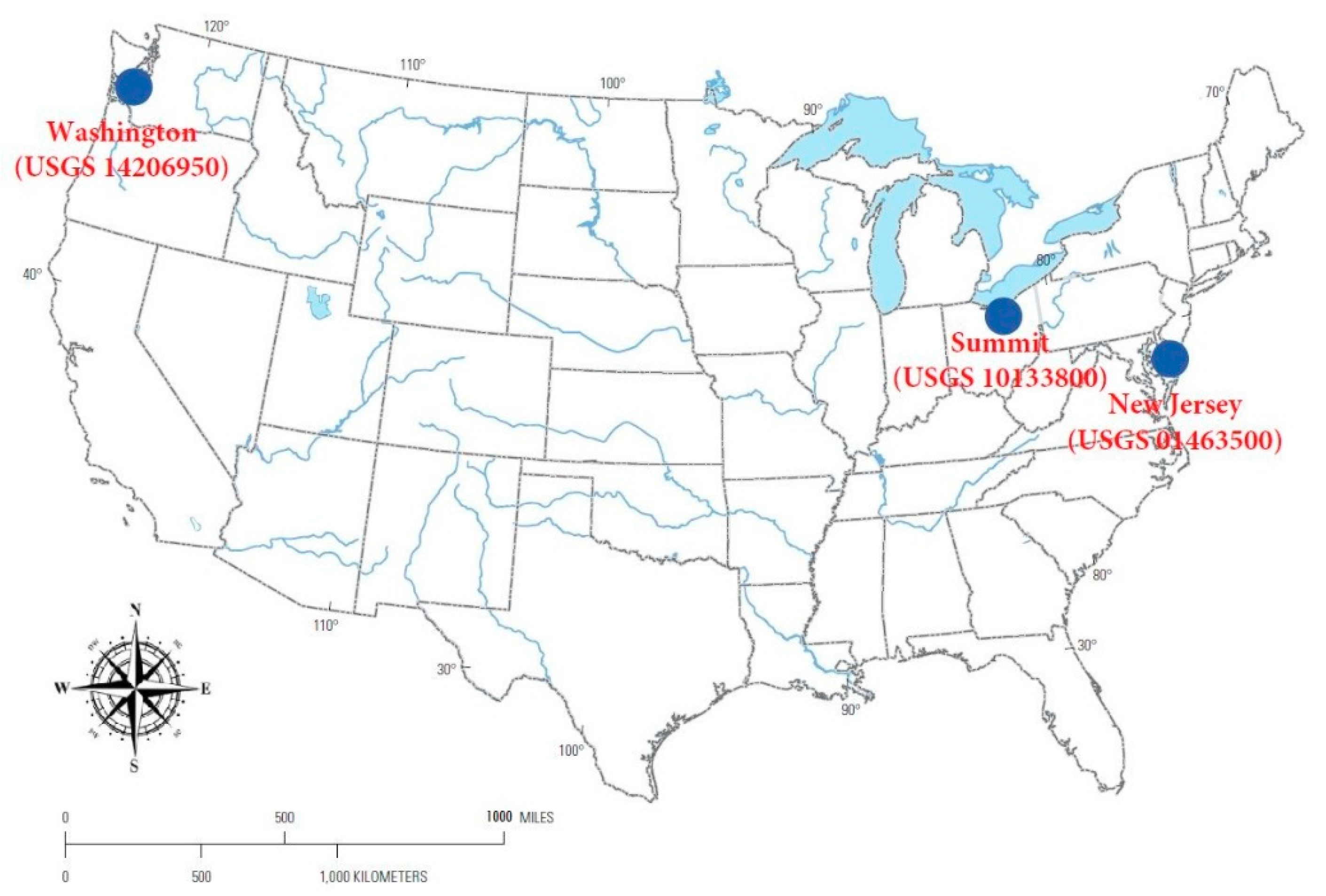
3. Case Study
4. Results and Discussion
4.1. The Correlations between DO and Other Water Quality Parameters
4.2. Sensitivity Analysis of Bat Algorithm Parameters
4.3. Modeling River Dissolved Oxygen Concentration
5. Conclusions
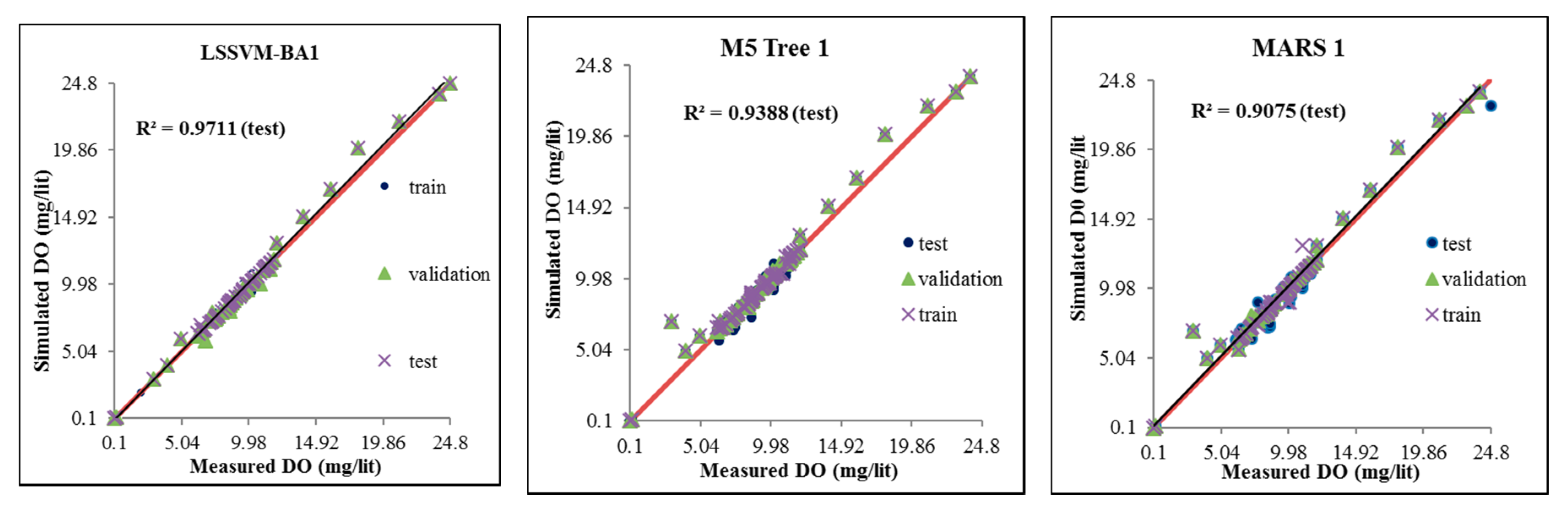
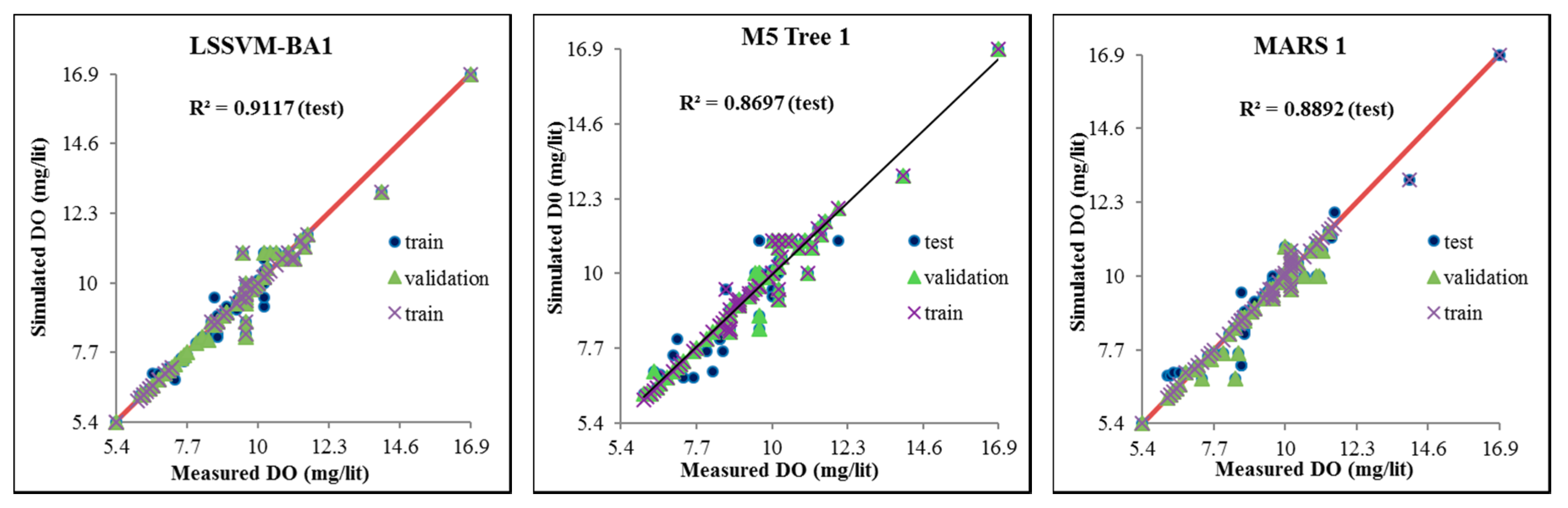
- The performance of LSSVM-BA 1 was found to be best among all the models based on higher correlation (see Figure 4) and lower RMSE and MAE compared with the other models at all three stations (see Table 6, Table 7 and Table 8). For instance, LSSVM-BA 1 for the USGS 14206950 station showed better accuracy by 3.1%, 11%, 45%, 40%, 27%, 28%, and 29% than the LSSVM-BA 2, LSSVM-BA 3, LSSVM-BA 4, LSSVM-BA 5, LSSVM-BA 6, LSSVM-BA 7, and LSSVM-BA 8 models.
- The MARS 1 and M5 Tree 1 models showed the lowest RMSE and MAE among all the MARS and M5 Tree models at all three stations during all three modeling phases (training, validation, and testing).
- The fourth and the fifth input combinations (without the WT parameter) showed the worst performance among all the input combinations at all the three stations at all the three modeling phases, which indicates the importance of WT in prediction of DO.
- All three predictive models (LSSVM, MARS, and M5 Tree) showed relatively better performance when only WT and SC were used as input at two stations, namely, USGS 10133800 and USGS 01463500, which indicates that WT and SC can be used for reasonable prediction of DO when other water quality data are not available.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Šiljić Tomić, A.; Antanasijević, D.; Ristić, M.; Perić-Grujić, A.; Pocajt, V. A linear and non-linear polynomial neural network modeling of dissolved oxygen content in surface water: Inter- and extrapolation performance with inputs’ significance analysis. Sci. Total Environ. 2018, 610–611, 1038–1046. [Google Scholar] [CrossRef] [PubMed]
- Post, C.J.; Cope, M.P.; Gerard, P.D.; Masto, N.M.; Vine, J.R.; Stiglitz, R.Y.; Hallstrom, J.O.; Newman, J.C.; Mikhailova, E.A. Monitoring spatial and temporal variation of dissolved oxygen and water temperature in the Savannah River using a sensor network. Environ. Monit. Assess. 2018, 190, 272. [Google Scholar] [CrossRef] [PubMed]
- Boyd, C.E.; Torrans, E.L.; Tucker, C.S. Dissolved Oxygen and Aeration in Ictalurid Catfish Aquaculture. J. World Aquac. Soc. 2018, 49, 7–70. [Google Scholar] [CrossRef]
- Reeder, W.J.; Quick, A.M.; Farrell, T.B.; Benner, S.G.; Feris, K.P.; Tonina, D. Spatial and Temporal Dynamics of Dissolved Oxygen Concentrations and Bioactivity in the Hyporheic Zone. Water Resour. Res. 2018. [Google Scholar] [CrossRef]
- Khan, U.T.; Valeo, C. Comparing a Bayesian and fuzzy number approach to uncertainty quantification in short-term dissolved oxygen prediction. J. Environ. Inform. 2017, 30, 1–16. [Google Scholar] [CrossRef]
- He, J.; Chu, A.; Ryan, M.C.; Valeo, C.; Zaitlin, B. Abiotic influences on dissolved oxygen in a riverine environment. Ecol. Eng. 2011, 37, 1804–1814. [Google Scholar] [CrossRef]
- Chapra, S.C.; Pelletier, G.J.; Tao, H. QUAL2K: A Modeling Framework for Simulating River and Stream Water Quality: Documentation and Users Manual; Civil and Environmental Engineering Dept., Tufts University: Medford, MA, USA, 2003. [Google Scholar]
- Wool, T.A.; Ambrose, R.B.; Martin, J.L.; Comer, E.A.; Tech, T. Water quality analysis simulation program (WASP). 2006. Available online: https://www.epa.gov/ceam/water-quality-analysis-simulation-program-wasp (accessed on 22 August 2018).
- Ahmed, A.A.M. Prediction of dissolved oxygen in Surma River by biochemical oxygen demand and chemical oxygen demand using the artificial neural networks (ANNs). J. King Saud Univ.—Eng. Sci. 2017, 29, 151–158. [Google Scholar] [CrossRef]
- Cox, B.A. A review of dissolved oxygen modelling techniques for lowland rivers. Sci. Total Environ. 2003, 314, 303–334. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Scholz, M. Modeling of Dissolved Oxygen Applying Stepwise Regression and a Template-Based Fuzzy Logic System. J. Environ. Eng. 2014. [Google Scholar] [CrossRef]
- Li, X.; Sha, J.; Wang, Z. A comparative study of multiple linear regression, artificial neural network and support vector machine for the prediction of dissolved oxygen. Hydrol. Res. 2017, 48, 1214–1225. [Google Scholar] [CrossRef]
- Kuok, K.K.; Kueh, S.M.; Chiu, P.C. Bat optimisation neural networks for rainfall forecasting: Case study for Kuching city. J. Water Clim. Chang. 2018. [Google Scholar] [CrossRef]
- Sulaiman, J.; Wahab, S.H. Heavy Rainfall Forecasting Model Using Artificial Neural Network for Flood Prone Area. In IT Convergence and Security 2017; Springer: Singapore, 2018; pp. 68–76. [Google Scholar]
- Shank, D.B.; Hoogenboom, G.; McClendon, R.W. Dewpoint temperature prediction using artificial neural networks. J. Appl. Meteorol. Climatol. 2008, 47, 1757–1769. [Google Scholar] [CrossRef]
- Radhika, Y.; Shashi, M. Atmospheric temperature prediction using support vector machines. Int. J. Comput. Theory Eng. 2009, 1, 55. [Google Scholar] [CrossRef]
- Pal, M.; Deswal, S. M5 model tree based modelling of reference evapotranspiration. Hydrol. Process. 2009, 23, 1437–1443. [Google Scholar] [CrossRef]
- Granata, F.; Gargano, R.; De Marinis, G. Support Vector Regression for Rainfall-Runoff Modeling in Urban Drainage: A Comparison with the EPA’s Storm Water Management Model. Water 2016, 8, 69. [Google Scholar] [CrossRef]
- Granata, F.; Papirio, S.; Esposito, G.; Gargano, R.; De Marinis, G. Machine learning algorithms for the forecasting of wastewater quality indicators. Water 2017, 9, 2. [Google Scholar] [CrossRef]
- Liu, Y.; Sang, Y.-F.; Li, X.; Hu, J.; Liang, K. Long-Term Streamflow Forecasting Based on Relevance Vector Machine Model. Water 2016, 9, 9. [Google Scholar] [CrossRef]
- Candelieri, A. Clustering and support vector regression for water demand forecasting and anomaly detection. Water 2017, 9, 224. [Google Scholar] [CrossRef]
- Ji, X.; Shang, X.; Dahlgren, R.A.; Zhang, M. Prediction of dissolved oxygen concentration in hypoxic river systems using support vector machine: A case study of Wen-Rui Tang River, China. Environ. Sci. Pollut. Res. 2017, 24, 16062–16076. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Yin, H.; Chapra, S.C.; Zhou, Q. Modelling dissolved oxygen depression in an urban river in China. Water 2017, 9, 520. [Google Scholar] [CrossRef]
- Heddam, S.; Kisi, O. Extreme learning machines: A new approach for modeling dissolved oxygen (DO) concentration with and without water quality variables as predictors. Environ. Sci. Pollut. Res. 2017, 24, 16702–16724. [Google Scholar] [CrossRef] [PubMed]
- Keshtegar, B.; Heddam, S. Modeling daily dissolved oxygen concentration using modified response surface method and artificial neural network: A comparative study. Neural Comput. Appl. 2017, 1–12. [Google Scholar] [CrossRef]
- Liu, S.; Yan, M.; Tai, H.; Xu, L.; Li, D. Prediction of dissolved oxygen content in aquaculture of Hyriopsis Cumingii using Elman neural network. 2011. Available online: https://link.springer.com/chapter/10.1007/978-3-642-27275-2_57 (accessed on 22 August 2018).
- Akkoyunlu, A.; Altun, H.; Cigizoglu, H.K. Depth-integrated estimation of dissolved oxygen in a lake. J. Environ. Eng. 2011, 137, 961–967. [Google Scholar] [CrossRef]
- Ay, M.; Kisi, O. Modeling of dissolved oxygen concentration using different neural network techniques in Foundation Creek, El Paso County, Colorado. J. Environ. Eng. 2011, 138, 654–662. [Google Scholar] [CrossRef]
- Bayram, A.; Uzlu, E.; Kankal, M.; Dede, T. Modeling stream dissolved oxygen concentration using teaching–learning based optimization algorithm. Environ. Earth Sci. 2015, 73, 6565–6576. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, J.; Yu, H.; Zhen, Z.; Li, D. Three-dimensional short-term prediction model of dissolved oxygen content based on pso-bpann algorithm coupled with kriging interpolation. Math. Probl. Eng. 2016, 2016. [Google Scholar] [CrossRef]
- Diamantopoulou, M.J.; Antonopoulos, V.Z.; Papamichail, D.M. Cascade correlation artificial neural networks for estimating missing monthly values of water quality parameters in rivers. Water Resour. Manag. 2007, 21, 649–662. [Google Scholar] [CrossRef]
- Heddam, S. Use of optimally pruned extreme learning machine (OP-ELM) in forecasting dissolved oxygen concentration (DO) several hours in advance: A case study from the Klamath River, Oregon, USA. Environ. Process. 2016, 3, 909–937. [Google Scholar] [CrossRef]
- Heddam, S. Generalized regression neural network (GRNN)-based approach for colored dissolved organic matter (CDOM) retrieval: Case study of Connecticut River at Middle Haddam Station, USA. Environ. Monit. Assess. 2014, 186, 7837–7848. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Xu, L.; Li, D.; Li, Q.; Jiang, Y.; Tai, H.; Zeng, L. Prediction of dissolved oxygen content in river crab culture based on least squares support vector regression optimized by improved particle swarm optimization. Comput. Electron. Agric. 2013, 95, 82–91. [Google Scholar] [CrossRef]
- Liu, S.; Xu, L.; Jiang, Y.; Li, D.; Chen, Y.; Li, Z. A hybrid WA–CPSO-LSSVR model for dissolved oxygen content prediction in crab culture. Eng. Appl. Artif. Intell. 2014, 29, 114–124. [Google Scholar] [CrossRef]
- Mohammadpour, R.; Shaharuddin, S.; Chang, C.K.; Zakaria, N.A.; Ghani, A.A.; Chan, N.W. Prediction of water quality index in constructed wetlands using support vector machine. Environ. Sci. Pollut. Res. 2014, 6208–6219. [Google Scholar] [CrossRef] [PubMed]
- Jadhav, M.S.; Khare, K.C.; Warke, A.S. Water Quality Prediction of Gangapur Reservoir (India) Using LS-SVM and Genetic Programming. Lakes Reserv. Res. Manag. 2015, 20, 275–284. [Google Scholar] [CrossRef]
- Ranković, V.; Radulović, J.; Radojević, I.; Ostojić, A.; Čomić, L. Prediction of dissolved oxygen in reservoirs using adaptive network-based fuzzy inference system. J. Hydroinform. 2012, 14, 167–179. [Google Scholar] [CrossRef] [Green Version]
- Heddam, S. Modeling hourly dissolved oxygen concentration (DO) using two different adaptive neuro-fuzzy inference systems (ANFIS): A comparative study. Environ. Monit. Assess. 2014, 186, 597–619. [Google Scholar] [CrossRef] [PubMed]
- Heddam, S. Modelling hourly dissolved oxygen concentration (DO) using dynamic evolving neural-fuzzy inference system (DENFIS)-based approach: Case study of Klamath River at Miller Island Boat Ramp, OR, USA. Environ. Sci. Pollut. Res. 2014, 21, 9212–9227. [Google Scholar] [CrossRef] [PubMed]
- Ay, M.; Kişi, Ö. Estimation of dissolved oxygen by using neural networks and neuro fuzzy computing techniques. KSCE J. Civ. Eng. 2017, 21, 1631–1639. [Google Scholar] [CrossRef]
- Kisi, O.; Akbari, N.; Sanatipour, M.; Hashemi, A.; Teimourzadeh, K.; Shiri, J. Modeling of dissolved oxygen in river water using artificial intelligence techniques. J. Environ. Inform. 2013, 22, 92–101. [Google Scholar] [CrossRef]
- Nemati, S.; Fazelifard, M.H.; Terzi, Ö.; Ghorbani, M.A. Estimation of dissolved oxygen using data-driven techniques in the Tai Po River, Hong Kong. Environ. Earth Sci. 2015, 74, 4065–4073. [Google Scholar] [CrossRef]
- Khani, S.; Rajaee, T. Modeling of Dissolved Oxygen Concentration and Its Hysteresis Behavior in Rivers Using Wavelet Transform-Based Hybrid Models. CLEAN—Soil Air Water 2017, 45. [Google Scholar] [CrossRef]
- Mehdipour, V.; Memarianfard, M.; Homayounfar, F. Application of gene expression programming to water dissolved oxygen concentration prediction. Int. J. Hum. Cap. Urban. Manag. 2017, 2, 39–48. [Google Scholar] [CrossRef]
- Singh, K.P.; Basant, N.; Gupta, S. Support vector machines in water quality management. Anal. Chim. Acta 2011, 703, 152–162. [Google Scholar] [CrossRef] [PubMed]
- Tan, G.; Yan, J.; Gao, C.; Yang, S. Prediction of water quality time series data based on least squares support vector machine. Procedia Eng. 2012, 31, 1194–1199. [Google Scholar] [CrossRef]
- Granata, F.; De Marinis, G. Machine learning methods for wastewater hydraulics. Flow Meas. Instrum. 2017, 57, 1–9. [Google Scholar] [CrossRef]
- Malek, S.; Mosleh, M.; Syed, S.M. Dissolved oxygen prediction using support vector machine. Int. J. Bioeng. Life Sci. 2014, 8, 46–50. [Google Scholar]
- Yu, H.; Chen, Y.; Hassan, S.; Li, D. Dissolved oxygen content prediction in crab culture using a hybrid intelligent method. Sci. Rep. 2016. [Google Scholar] [CrossRef] [PubMed]
- Heddam, S.; Kisi, O. Modelling daily dissolved oxygen concentration using least square support vector machine, multivariate adaptive regression splines and M5 model tree. J. Hydrol. 2018. [Google Scholar] [CrossRef]
- Zhu, X.; Ma, S.; Xu, Q. A WD-GA-LSSVM model for rainfall-triggered landslide displacement prediction. J. Mt. Sci. 2018, 15, 156–166. [Google Scholar] [CrossRef]
- Rostami, A.; Baghban, A. Application of a supervised learning machine for accurate prognostication of higher heating values of solid wastes. Energy Sources Part. A Recov. Util. Environ. Eff. 2018, 40, 558–564. [Google Scholar] [CrossRef]
- Ahmadi, M.H.; Ahmadi, M.A.; Nazari, M.A.; Mahian, O.; Ghasempour, R. A proposed model to predict thermal conductivity ratio of Al2O3/EG nanofluid by applying least squares support vector machine (LSSVM) and genetic algorithm as a connectionist approach. J. Therm. Anal. Calorim. 2018, 1–11. [Google Scholar] [CrossRef]
- Huan, J.; Cao, W.; Qin, Y. Prediction of dissolved oxygen in aquaculture based on EEMD and LSSVM optimized by the Bayesian evidence framework. Comput. Electron. Agric. 2018, 150, 257–265. [Google Scholar] [CrossRef]
- Wang, P.; Liu, C.; Li, Y. Estimation method for ET0 with PSO-LSSVM based on the HHT in cold and arid data-sparse area. Clust. Comput. 2018, 1–10. [Google Scholar] [CrossRef]
- Wu, Y.-H.; Shen, H. Grey-related least squares support vector machine optimization model and its application in predicting natural gas consumption demand. J. Comput. Appl. Math. 2018, 338, 212–220. [Google Scholar] [CrossRef]
- Zhao, H.; Huang, G.; Yan, N. Forecasting Energy-Related CO2 Emissions Employing a Novel SSA-LSSVM Model: Considering Structural Factors in China. Energies 2018, 11, 781. [Google Scholar] [CrossRef]
- Zheng, H.; Zhang, Y.; Liu, J.; Wei, H.; Zhao, J.; Liao, R. A novel model based on wavelet LS-SVM integrated improved PSO algorithm for forecasting of dissolved gas contents in power transformers. Electr. Power Syst. Res. 2018, 155, 196–205. [Google Scholar] [CrossRef]
- Li, Y.; Yang, P.; Wang, H. Short-term wind speed forecasting based on improved ant colony algorithm for LSSVM. Clust. Comput. 2018, 1–7. [Google Scholar] [CrossRef]
- Niu, D.; Li, S.; Dai, S. Comprehensive Evaluation for Operating Efficiency of Electricity Retail Companies Based on the Improved TOPSIS Method and LSSVM Optimized by Modified Ant Colony Algorithm from the View of Sustainable Development. Sustainability 2018, 10, 860. [Google Scholar] [CrossRef]
- Li, W.K.; Wang, W.L.; Li, L. Optimization of water resources utilization by multi-objective moth-flame algorithm. Water Resour. Manag. 2018, 1–14. [Google Scholar] [CrossRef]
- Lotfinejad, M.M.; Hafezi, R.; Khanali, M.; Hosseini, S.S.; Mehrpooya, M.; Shamshirband, S. A comparative assessment of predicting daily solar radiation using bat neural network (BNN), generalized regression neural network (GRNN), and neuro-fuzzy (NF) system: A case study. Energies 2018, 11, 1188. [Google Scholar] [CrossRef]
- Ehteram, M.; Karami, H.; Farzin, S. Reservoir optimization for energy production using a new evolutionary algorithm based on multi-criteria decision-making models. Water Resour. Manag. 2018, 32, 2539–2560. [Google Scholar] [CrossRef]
- Ehteram, M.; Mousavi, S.F.; Karami, H.; Farzin, S.; Singh, V.P.; Chau, K.; El-Shafie, A. Reservoir operation based on evolutionary algorithms and multi-criteria decision-making under climate change and uncertainty. J. Hydroinform. 2018. [Google Scholar] [CrossRef]
- Kisi, O. Pan evaporation modeling using least square support vector machine, multivariate adaptive regression splines and M5 model tree. J. Hydrol. 2015, 528, 312–320. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Dibike, Y.B.; Velickov, S.; Solomatine, D.; Abbott, M.B. Model induction with support vector machines: Introduction and applications. J. Comput. Civ. Eng. 2001, 15, 208–216. [Google Scholar] [CrossRef]
- Yaseen, Z.; Kisi, O.; Demir, V. Enhancing long-term streamflow forecasting and predicting using periodicity data component: Application of artificial intelligence. Water Resour. Manag. 2016. [Google Scholar] [CrossRef]
- Bolouri-Yazdeli, Y.; Bozorg Haddad, O.; Fallah-Mehdipour, E.; Mariño, M.A. Evaluation of real-time operation rules in reservoir systems operation. Water Resour. Manag. 2014, 28, 715–729. [Google Scholar] [CrossRef]
- Keshtegar, B.; Piri, J.; Kisi, O. A nonlinear mathematical modeling of daily pan evaporation based on conjugate gradient method. Comput. Electron. Agric. 2016, 127, 120–130. [Google Scholar] [CrossRef]
- Breiman, L. Classification and Regression Trees; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Sharda, V.N.; Prasher, S.O.; Patel, R.M.; Ojasvi, P.R.; Prakash, C. Performance of Multivariate Adaptive Regression Splines (MARS) in predicting runoff in mid-Himalayan micro-watersheds with limited data. Hydrol. Sci. J.—J. Des. Sci. Hydrol. 2008, 53, 1165–1175. [Google Scholar] [CrossRef]
- Kisi, O. Modeling reference evapotranspiration using three different heuristic regression approaches. Agric. Water Manag. 2016, 169, 162–172. [Google Scholar] [CrossRef]
- Olden, J.D.; Jackson, D.A. Illuminating the “black box”: A randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 2002. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Ghareb, M.I.; Ebtehaj, I.; Bonakdari, H.; Ravinesh, D.; Siddique, R.; Heddam, S.; Yusif, A. Rainfall pattern forecasting using novel hybrid intelligent model based ANFIS-FFA. Water Resour. Manag. 2018, 32, 105–122. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Ebtehaj, I.; Bonakdari, H.; Deo, R.C.; Mehr, A.D.; Hanna, W.; Wan, M.; Diop, L.; El-shafie, A.; Singh, V.P. Novel approach for streamflow forecasting using a hybrid ANFIS-FFA model. J. Hydrol. 2017, 554, 263–276. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Fu, M.; Wang, C.; Hanna, W.; Wan, M.; Deo, R.C.; El-shafie, A. Application of the Hybrid Artificial Neural Network Coupled with Rolling Mechanism and Grey Model Algorithms for Streamflow Forecasting over Multiple Time Horizons. Water Resour. Manag. 2018, 32, 1883–1899. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Deo, R.C.; Yaseen, Z.M.; Kashani, M.H. Pan evaporation prediction using a hybrid multilayer perceptron-firefly algorithm (MLP-FFA) model: Case study in North Iran. Theor. Appl. Climatol. 2018, 133, 1119–1131. [Google Scholar] [CrossRef]
- Fahimi, F.; Yaseen, Z.M.; El-shafie, A. Application of soft computing based hybrid models in hydrological variables modeling: A comprehensive review. Theor. Appl. Climatol. 2016, 1–29. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | USGS 14206950 | USGS 10133800 | USGS 01463500 |
|---|---|---|---|
| Latitude | 45°24′13′′ | 40°45′35′′ | 40°13′18′′ |
| Longitude | 122°45′13′′ | 111°33′48′′ | 74°46′41′′ |
| Begin Date | 01/01/2003 | 01/01/2002 | 01/01/2002 |
| End Date | 31/12/2016 | 31/12/2016 | 31/12/2016 |
| Training period | 2003–2010 | 2002–2010 | 2002–2010 |
| Validation period | 2011–2013 | 2011–2013 | 2011–2013 |
| Test period | 2014–2016 | 2014–2016 | 2014–2016 |
| Station | Data | Unit | Xmean | Xmax | Xmin | Sx | Cv |
|---|---|---|---|---|---|---|---|
| USGS 14206950 | WT | °C | 12.619 | 24.800 | 0.100 | 5.190 | 0.411 |
| pH | - | 7.281 | 7.900 | 6.500 | 0.177 | 0.024 | |
| SC | µS/cm | 200.769 | 461.00 | 61.000 | 54.889 | 0.273 | |
| Q | cfs | 47.368 | 1410.000 | 0.990 | 87.995 | 1.858 | |
| DO | mg/lit | 12.619 | 24.800 | 0.100 | 5.190 | 0.411 | |
| USGS 10133800 | WT | °C | 9.179 | 22.00 | 0.300 | 6.148 | 0.670 |
| pH | - | 7.961 | 8.600 | 6.800 | 0.233 | 0.029 | |
| SC | µS/cm | 1224.585 | 3530.00 | 453.000 | 313.211 | 0.256 | |
| Q | cfs | 32.927 | 371.000 | 2.20 | 40.722 | 1.238 | |
| DO | mg/lit | 9.076 | 12.80 | 4.70 | 1.369 | 0.151 | |
| USGS 01463500 | WT | °C | 13.344 | 30.300 | −0.200 | 8.984 | 0.673 |
| pH | 7.893 | 9.800 | 6.300 | 0.492 | 0.062 | ||
| SC | µS/cm | 193.572 | 448.00 | 74.00 | 43.264 | 0.223 | |
| Q | cfs | 13940.65 | 230000 | 2370. | 14626.481 | 1.049 | |
| DO | mg/lit | 11.056 | 16.900 | 5.40 | 2.263 | 0.205 |
| Parameter | DO | Q | SC | pH | WT |
|---|---|---|---|---|---|
| USGS 14206950 | |||||
| DO (mg/lit) | 1 | - | - | - | - |
| Q (cfs) | 0.196 | 1 | - | - | - |
| SC (µS/cm) | −0.678 | −0.612 | 1 | - | - |
| pH | 0.112 | −0.561 | 0.378 | 1 | - |
| WT (°C) | −0.981 | −0.224 | 0.614 | −0.024 | 1 |
| USGS 10133800 | |||||
| DO (mg/lit) | 1 | - | - | - | - |
| Q (cfs) | 0.187 | 1 | - | - | - |
| SC (µS/cm) | 0.312 | −0.525 | 1 | - | - |
| pH | 0.111 | 0.311 | −0.374 | 1 | - |
| WT (°C) | −0.944 | −0.054 | −0.444 | −0.212 | 1 |
| USGS 01463500 | |||||
| DO (mg/lit) | 1 | - | - | - | - |
| Q (cfs) | 0.223 | 1 | - | - | - |
| SC (µS/cm) | −0.281 | −0.565 | 1 | - | - |
| pH | 0.109 | −0.320 | −0.606 | 1 | - |
| WT (°C) | −0.912 | −0.264 | 0.238 | 0.194 | 1 |
| Models | Input Combinations | |||||
|---|---|---|---|---|---|---|
| LSSVM-BA 1 | M5 Tree 1 | MARS 1 | WT | SC | pH | Q |
| LSSVM-BA 2 | M5 Tree 2 | MARS 2 | WT | SC | Q | - |
| LSSVM-BA 3 | M5 Tree 3 | MARS 3 | WT | SC | pH | - |
| LSSVM-BA 4 | M5 Tree 4 | MARS 4 | SC | pH | - | - |
| LSSVM-BA 5 | M5 Tree 5 | MARS 5 | SC | Q | - | - |
| LSSVM-BA 6 | M5 Tree 6 | MARS 6 | WT | pH | - | - |
| LSSVM-BA 7 | M5 Tree 7 | MARS 7 | WT | Q | - | - |
| LSSVM-BA 8 | M5 Tree 8 | MARS 8 | WT | SC | - | - |
| Population Size | Objective Function (mg/lit) | Maximum Frequency | Objective Function (mg/lit) | Minimum Frequency | Objective Function (mg/lit) | Maximum Loudness | Objective Function (mg/lit) |
|---|---|---|---|---|---|---|---|
| USGS 4206950 | |||||||
| 20 | 0.944 | 0.30 | 0.934 | 0.10 | 0.921 | 3 | 0.910 |
| 40 | 0.921 | 0.50 | 0.921 | 0.20 | 0.882 | 5 | 0.882 |
| 60 | 0.882 | 0.70 | 0.882 | 0.30 | 0.914 | 7 | 0.889 |
| 80 | 0.912 | 0.90 | 0.914 | 0.40 | 0.955 | 9 | 0.901 |
| USGS 0133800 | |||||||
| 20 | 0.956 | 0.30 | 0.921 | 0.10 | 0.931 | 3 | 0.954 |
| 40 | 0.916 | 0.50 | 0.899 | 0.20 | 0.916 | 5 | 0.892 |
| 60 | 0.892 | 0.70 | 0.892 | 0.30 | 0.892 | 7 | 0.912 |
| 80 | 0.901 | 0.90 | 0.912 | 0.40 | 0.912 | 9 | 0.916 |
| USGS01463500 | |||||||
| 20 | 0.935 | 0.30 | 0.925 | 0.10 | 0.929 | 3 | 0.934 |
| 40 | 0.919 | 0.50 | 0.911 | 0.20 | 0.912 | 5 | 0.895 |
| 60 | 0.895 | 0.70 | 0.895 | 0.30 | 0.895 | 7 | 0.912 |
| 80 | 0.901 | 0.90 | 0.902 | 0.40 | 0.910 | 9 | 0.921 |
| Models | Training | Validation | Testing | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | R | RMSE | MAE | R | RMSE | MAE | R | RMSE | |
| LSSVM-BA 1 | 0.9822 | 0.672 | 0.425 | 0.9755 | 0.689 | 0.587 | 0.9711 | 0.882 | 0.588 |
| LSSVM-BA 2 | 0.9799 | 0.878 | 0.565 | 0.9743 | 0.894 | 0.812 | 0.9645 | 0.911 | 0.912 |
| LSSVM-BA 3 | 0.9754 | 0.974 | 0.672 | 0.9658 | 0.999 | 0.878 | 0.9612 | 1.002 | 1.021 |
| LSSVM-BA 4 | 0.9512 | 1.224 | 0.724 | 0.9549 | 1.512 | 1.312 | 0.9423 | 1.614 | 1.314 |
| LSSVM-BA 5 | 0.9505 | 1.445 | 1.112 | 0.9582 | 1.572 | 1.472 | 0.9345 | 1.494 | 1.552 |
| LSSVM-BA 6 | 0.9612 | 1.122 | 0.715 | 0.9554 | 1.212 | 1.211 | 0.9554 | 1.214 | 1.304 |
| LSSVM-BA 7 | 0.9549 | 1.222 | 0.689 | 0.9449 | 1.225 | 1.212 | 0.9497 | 1.232 | 1.215 |
| LSSVM-BA 8 | 0.9801 | 0.772 | 0.439 | 0.9712 | 0.694 | 0.589 | 0.9692 | 0.892 | 0.618 |
| M5 Tree 1 | 0.9392 | 0.892 | 0.785 | 0.9391 | 0.912 | 0.918 | 0.9388 | 1.112 | 1.021 |
| M5 Tree 2 | 0.9091 | 0.912 | 0.854 | 0.9024 | 1.024 | 0.945 | 0.9012 | 1.124 | 1.026 |
| M5 Tree 3 | 0.8754 | 0.923 | 0.855 | 0.8665 | 1.112 | 0.924 | 0.8654 | 1.126 | 1.114 |
| M5 Tree 4 | 0.8112 | 1.144 | 0.932 | 0.79112 | 1.524 | 0.987 | 0.8012 | 1.567 | 1.524 |
| M5 Tree 5 | 0.8523 | 1.256 | 0.914 | 0.82231 | 1.544 | 0.989 | 0.8211 | 1.569 | 1.555 |
| M5 Tree 6 | 0.8546 | 0.911 | 0.879 | 0.8423 | 1.212 | 0.944 | 0.8432 | 1.324 | 1.311 |
| M5 Tree 7 | 0.8647 | 0.910 | 0.899 | 0.8541 | 0.999 | 0.924 | 0.8534 | 1.001 | 0.914 |
| M5 Tree 8 | 0.9301 | 0.899 | 0.790 | 0.9301 | 0.925 | 0.914 | 0.9289 | 1.119 | 1.025 |
| MARS 1 | 0.9191 | 0.945 | 0.939 | 0.9118 | 1.011 | 1.002 | 0.9075 | 1.021 | 1.041 |
| MARS 2 | 0.8867 | 0.955 | 0.944 | 0.8765 | 1.112 | 1.108 | 0.8712 | 1.112 | 1.207 |
| MARS 3 | 0.8654 | 1.012 | 1.002 | 0.8543 | 1.224 | 0.999 | 0.8423 | 1.226 | 1.112 |
| MARS 4 | 0.8312 | 1.234 | 1.212 | 0.8124 | 1.244 | 1.112 | 0.8012 | 1.254 | 1.224 |
| MARS 5 | 0.8224 | 1.245 | 1.234 | 0.8112 | 1.256 | 1.145 | 0.8011 | 1.259 | 1.155 |
| MARS 6 | 0.8732 | 1.112 | 1.110 | 0.8643 | 1.145 | 1.008 | 0.8512 | 1.147 | 1.128 |
| MARS 7 | 0.8701 | 1.102 | 0.998 | 0.8602 | 1.232 | 1.102 | 0.8545 | 1.234 | 1.222 |
| MARS 8 | 0.9089 | 0.955 | 0.949 | 0.9121 | 1.102 | 1.106 | 0.9054 | 1.045 | 1.110 |
| Models | Training | Validation | Testing | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | R | RMSE | MAE | R | RMSE | MAE | R | RMSE | |
| LSSVM-BA 1 | 0.9512 | 0.712 | 0.525 | 0.9296 | 0.745 | 0.597 | 0.9285 | 0.892 | 0.888 |
| LSSVM-BA 2 | 0.9499 | 0.898 | 0.575 | 0.9143 | 0.911 | 0.814 | 0.8954 | 0.921 | 0.931 |
| LSSVM-BA 3 | 0.9324 | 0.994 | 0.672 | 0.9131 | 1.002 | 0.898 | 0.8812 | 1.112 | 1.111 |
| LSSVM-BA 4 | 0.9314 | 1.315 | 0.724 | 0.9041 | 1.626 | 1.314 | 0.8523 | 1.715 | 1.712 |
| LSSVM-BA 5 | 0.9205 | 1.457 | 1.112 | 0.8812 | 1.672 | 1.475 | 0.8645 | 1.594 | 1.552 |
| LSSVM-BA 6 | 0.9412 | 1.131 | 0.715 | 0.9154 | 1.532 | 1.312 | 0.8712 | 1.314 | 1.234 |
| LSSVM-BA 7 | 0.9449 | 1.122 | 0.689 | 0.9041 | 1.443 | 1.435 | 0.8891 | 1.332 | 1.255 |
| LSSVM-BA 8 | 0.9501 | 0.767 | 0.555 | 0.9209 | 0.898 | 0.675 | 0.8999 | 0.911 | 0.910 |
| M5 Tree 1 | 0.9374 | 0.892 | 0.789 | 0.9024 | 0.954 | 0.928 | 0.8982 | 1.224 | 1.221 |
| M5 Tree 2 | 0.9081 | 0.925 | 0.855 | 0.8912 | 1.025 | 0.955 | 0.8756 | 1.344 | 1.229 |
| M5 Tree 3 | 0.8554 | 0.924 | 0.835 | 0.8465 | 1.222 | 0.964 | 0.8654 | 1.359 | 1.234 |
| M5 Tree 4 | 0.8212 | 1.114 | 0.925 | 0.83112 | 1.529 | 1.116 | 0.8543 | 1.587 | 1.512 |
| M5 Tree 5 | 0.8323 | 1.256 | 0.924 | 0.8214 | 1.578 | 1.257 | 0.8435 | 1.589 | 1.565 |
| M5 Tree 6 | 0.8746 | 0.922 | 0.899 | 0.8712 | 1.342 | 0.946 | 0.8614 | 1.414 | 1.411 |
| M5 Tree 7 | 0.8647 | 0.921 | 0.888 | 0.8841 | 1.021 | 0.936 | 0.8634 | 1.321 | 1.110 |
| M5 Tree 8 | 0.8955 | 0.912 | 0.791 | 0.9012 | 1.020 | 0.930 | 0.8829 | 1.229 | 1.223 |
| MARS 1 | 0.9292 | 0.975 | 0.949 | 0.8928 | 1.024 | 1.002 | 0.8795 | 1.321 | 1.225 |
| MARS 2 | 0.8769 | 0.984 | 0.974 | 0.8765 | 1.114 | 1.112 | 0.8611 | 1.314 | 1.297 |
| MARS 3 | 0.8524 | 1.010 | 1.012 | 0.8433 | 1.229 | 1.212 | 0.8323 | 1.336 | 1.295 |
| MARS 4 | 0.8322 | 1.232 | 1.222 | 0.8111 | 1.254 | 1.220 | 0.8011 | 1.354 | 1.353 |
| MARS 5 | 0.8214 | 1.241 | 1.244 | 0.8012 | 1.266 | 1.219 | 0.8002 | 1.356 | 1.311 |
| MARS 6 | 0.8732 | 1.112 | 1.111 | 0.8542 | 1.143 | 1.116 | 0.8412 | 1.337 | 1.254 |
| MARS 7 | 0.8721 | 1.102 | 0.998 | 0.8502 | 1.231 | 1.099 | 0.8245 | 1.339 | 1.229 |
| MARS 8 | 0.9144 | 0.979 | 0.954 | 0.8934 | 1.102 | 1.001 | 0.8754 | 1.318 | 1.227 |
| Models | Training | Validation | Testing | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | R | RMSE | MAE | R | RMSE | MAE | R | RMSE | |
| LSSVM-BA 1 | 0.9112 | 0.814 | 0.545 | 0.9297 | 0.823 | 0.697 | 0.9117 | 0.895 | 0.889 |
| LSSVM-BA 2 | 0.9099 | 0.878 | 0.595 | 0.8944 | 0.912 | 0.844 | 0.8923 | 0.935 | 1.232 |
| LSSVM-BA 3 | 0.8968 | 0.934 | 0.683 | 0.8831 | 1.121 | 0.899 | 0.8712 | 1.116 | 1.224 |
| LSSVM-BA 4 | 0.8799 | 1.317 | 0.715 | 0.8541 | 1.534 | 1.325 | 0.8432 | 1.727 | 1.816 |
| LSSVM-BA 5 | 0.8756 | 1.467 | 0.914 | 0.8612 | 1.772 | 1.495 | 0.8545 | 1.693 | 1.759 |
| LSSVM-BA 6 | 0.8912 | 1.231 | 0.711 | 0.8911 | 1.521 | 1.314 | 0.8602 | 1.316 | 1.734 |
| LSSVM-BA 7 | 0.8987 | 1.132 | 0.689 | 0.8894 | 1.453 | 1.278 | 0.8891 | 1.342 | 1.755 |
| LSSVM-BA 8 | 0.9102 | 0.822 | 0.555 | 0.9054 | 0.814 | 0.712 | 0.8998 | 0.914 | 0.912 |
| M5 Tree 1 | 0.9074 | 0.911 | 0.799 | 0.9024 | 0.974 | 0.948 | 0.8892 | 1.233 | 1.230 |
| M5 Tree 2 | 0.8881 | 0.949 | 0.867 | 0.8912 | 1.036 | 0.963 | 0.8656 | 1.319 | 1.314 |
| M5 Tree 3 | 0.8754 | 0.953 | 0.854 | 0.8465 | 1.242 | 0.972 | 0.8455 | 1.379 | 1.375 |
| M5 Tree 4 | 0.8622 | 1.124 | 0.915 | 0.83112 | 1.519 | 1.126 | 0.8343 | 1.592 | 1.587 |
| M5 Tree 5 | 0.8223 | 1.266 | 0.945 | 0.8214 | 1.588 | 1.359 | 0.8235 | 1.599 | 1.594 |
| M5 Tree 6 | 0.8735 | 0.951 | 0.889 | 0.8712 | 1.246 | 0.999 | 0.8514 | 1.410 | 1.399 |
| M5 Tree 7 | 0.8749 | 0.943 | 0.878 | 0.8841 | 1.025 | 0.976 | 0.8734 | 1.321 | 1.302 |
| M5 Tree 8 | 0.9071 | 0.912 | 0.801 | 0.9012 | 0.916 | 0.954 | 0.8890 | 1.237 | 1.233 |
| MARS 1 | 0.9079 | 0.981 | 0.959 | 0.8925 | 1.037 | 1.102 | 0.8697 | 1.311 | 1.239 |
| MARS 2 | 0.8859 | 0.994 | 0.994 | 0.8564 | 1.116 | 1.114 | 0.8543 | 1.324 | 1.299 |
| MARS 3 | 0.8614 | 1.110 | 1.111 | 0.8231 | 1.231 | 1.102 | 0.8123 | 1.346 | 1.285 |
| MARS 4 | 0.8222 | 1.332 | 1.312 | 0.8011 | 1.259 | 1.220 | 0.8010 | 1.363 | 1.361 |
| MARS 5 | 0.8114 | 1.352 | 1.344 | 0.8014 | 1.289 | 1.212 | 0.8002 | 1.379 | 1.310 |
| MARS 6 | 0.8632 | 1.212 | 1.211 | 0.8544 | 1.141 | 1.017 | 0.8312 | 1.327 | 1.269 |
| MARS 7 | 0.8321 | 1.112 | 0.999 | 0.8512 | 1.229 | 1.014 | 0.8241 | 1.349 | 1.259 |
| MARS 8 | 0.9044 | 0.989 | 0.979 | 0.8920 | 1.041 | 1.106 | 0.8612 | 1.314 | 1.242 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yaseen, Z.M.; Ehteram, M.; Sharafati, A.; Shahid, S.; Al-Ansari, N.; El-Shafie, A. The Integration of Nature-Inspired Algorithms with Least Square Support Vector Regression Models: Application to Modeling River Dissolved Oxygen Concentration. Water 2018, 10, 1124. https://doi.org/10.3390/w10091124
Yaseen ZM, Ehteram M, Sharafati A, Shahid S, Al-Ansari N, El-Shafie A. The Integration of Nature-Inspired Algorithms with Least Square Support Vector Regression Models: Application to Modeling River Dissolved Oxygen Concentration. Water. 2018; 10(9):1124. https://doi.org/10.3390/w10091124
Chicago/Turabian StyleYaseen, Zaher Mundher, Mohammad Ehteram, Ahmad Sharafati, Shamsuddin Shahid, Nadhir Al-Ansari, and Ahmed El-Shafie. 2018. "The Integration of Nature-Inspired Algorithms with Least Square Support Vector Regression Models: Application to Modeling River Dissolved Oxygen Concentration" Water 10, no. 9: 1124. https://doi.org/10.3390/w10091124