Adaptive Detection Method for Organic Contamination Events in Water Distribution Systems Using the UV-Vis Spectrum Based on Semi-Supervised Learning


Abstract
:1. Introduction
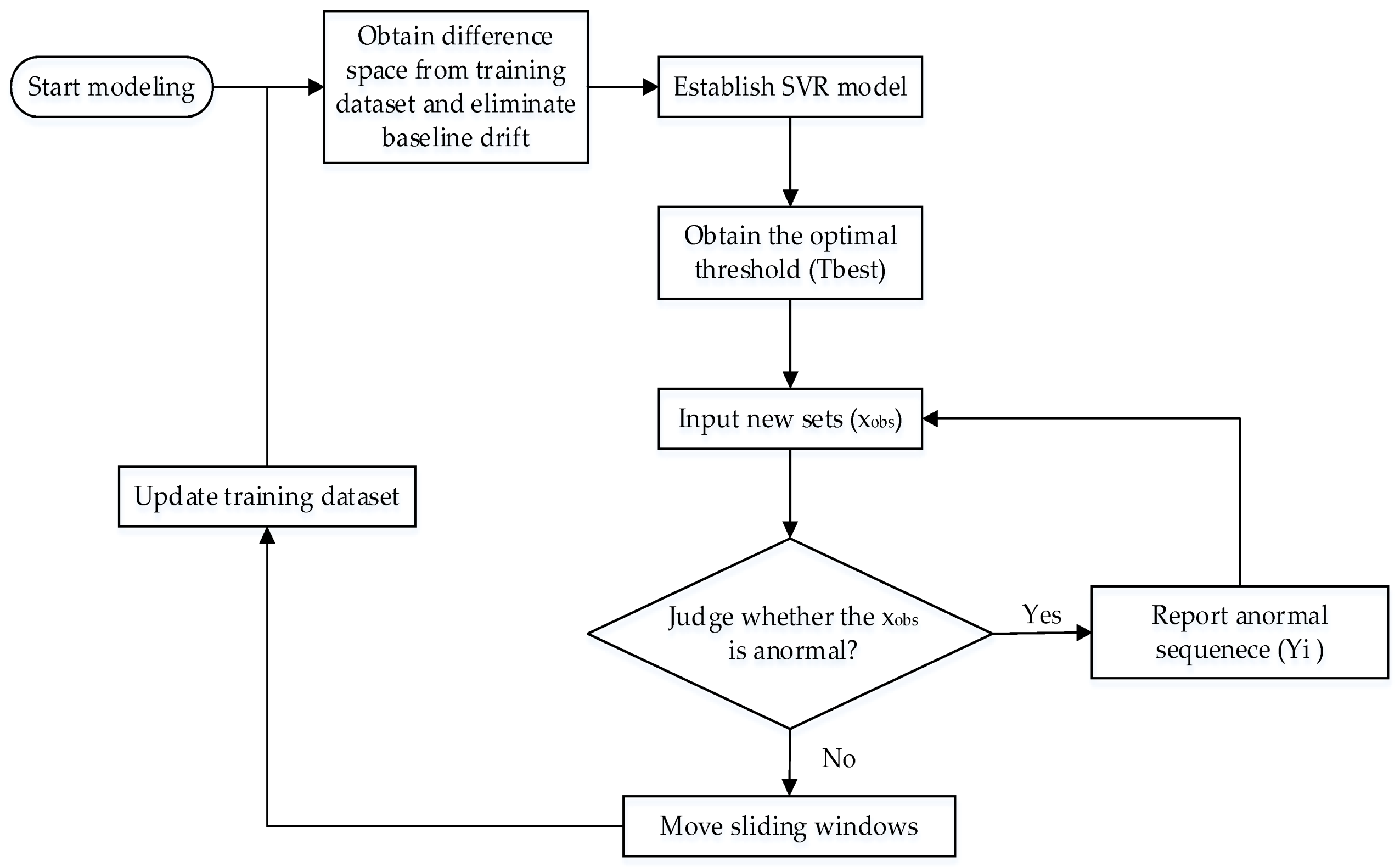
2. Methods
- The difference space is estimated from the normal sets in the training dataset and the latest normal sets in the test dataset, which has the same number of sets as the training dataset.
- The baseline drift of the training dataset is omitted by using the difference space obtained in Step 1. Then, the SVR model is established by adopting the labeled training dataset.
- The ROC curve is based on the detection rate of the ordinate and the FAR of the abscissa. The optimal threshold () is obtained according to the ROC curve.
- The test dataset is inputted with 50 UV-Vis spectral sets at each time. The baseline drift is removed from the new sets using the difference space obtained in Step 1. Then, the trained SVR method regresses the new sets and outputs the results. The outlier is obtained by comparing with the optimal threshold () determined using Step 3.
- Sequential Bayesian is used to identify outliers and determine contamination events. If no contamination event occurs, then the sliding window moves forward, and the procedure returns to Step 1. Otherwise, the program triggers the alarm signals and returns to Step 4.
2.1. Dynamic Orthogonal Projection Correction
2.2. SVR
2.3. Sequential Bayesian Anomaly Detection
2.4. ROC Curve
2.5. Detection Accuracy
3. Experiments and Results
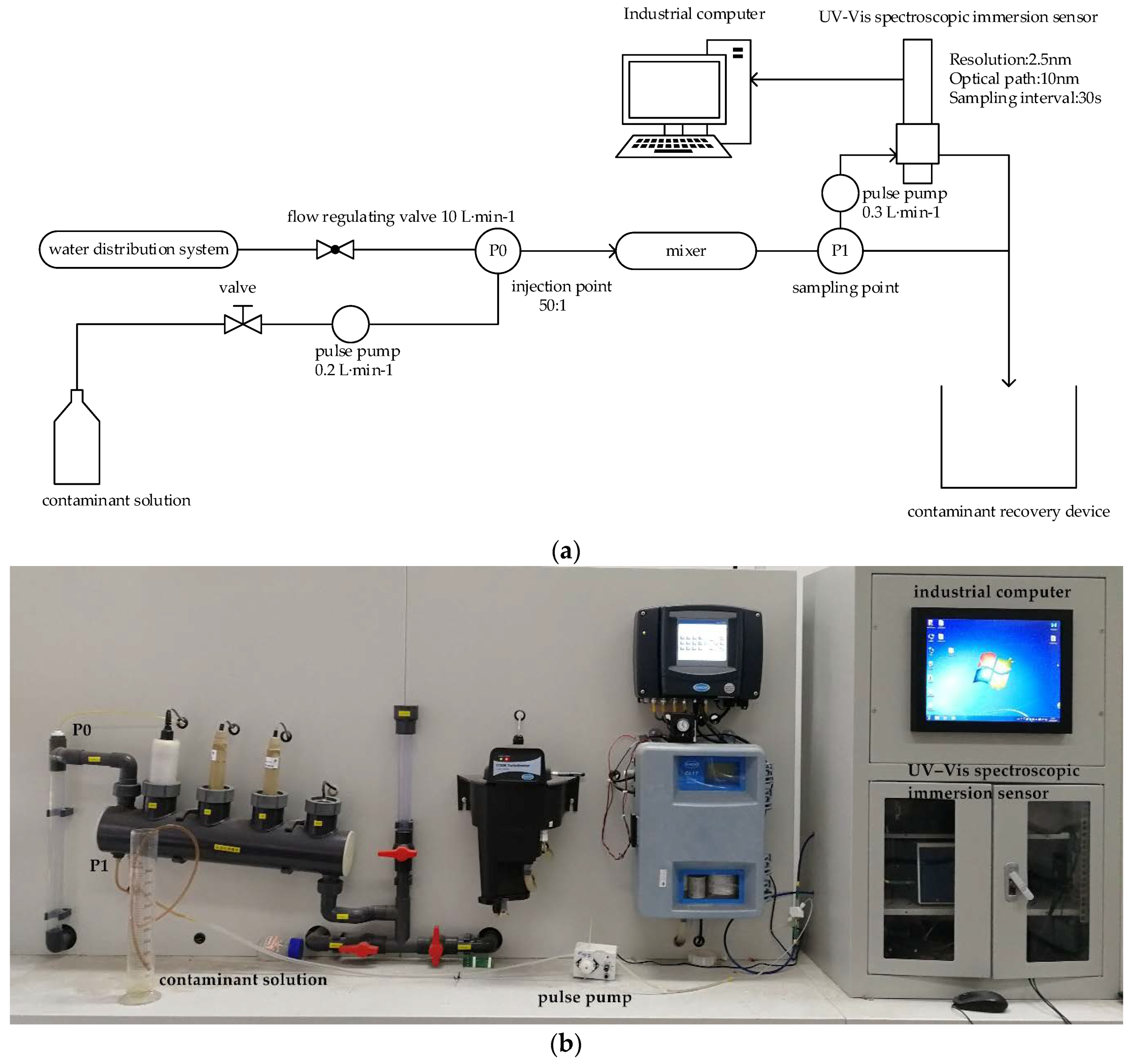
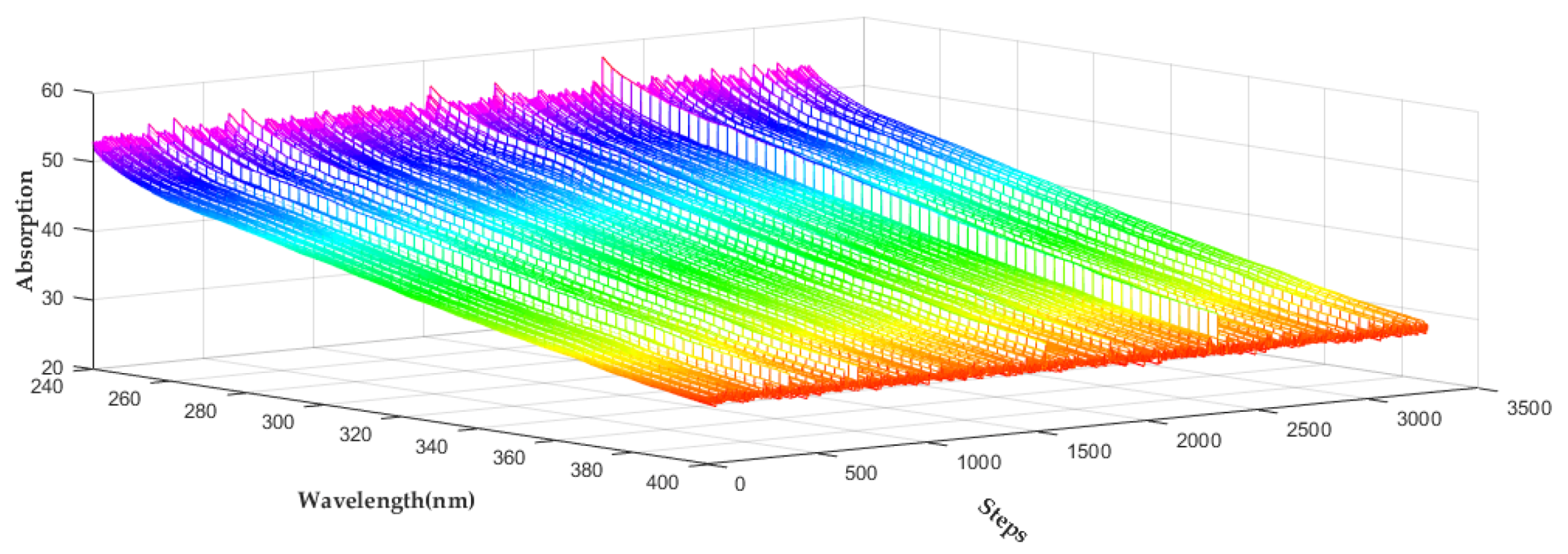
3.1. Experimental Data Acquisition
3.1.1. Experiment Device Introduction
3.1.2. Organic Contaminant Selection and Dataset Acquisition
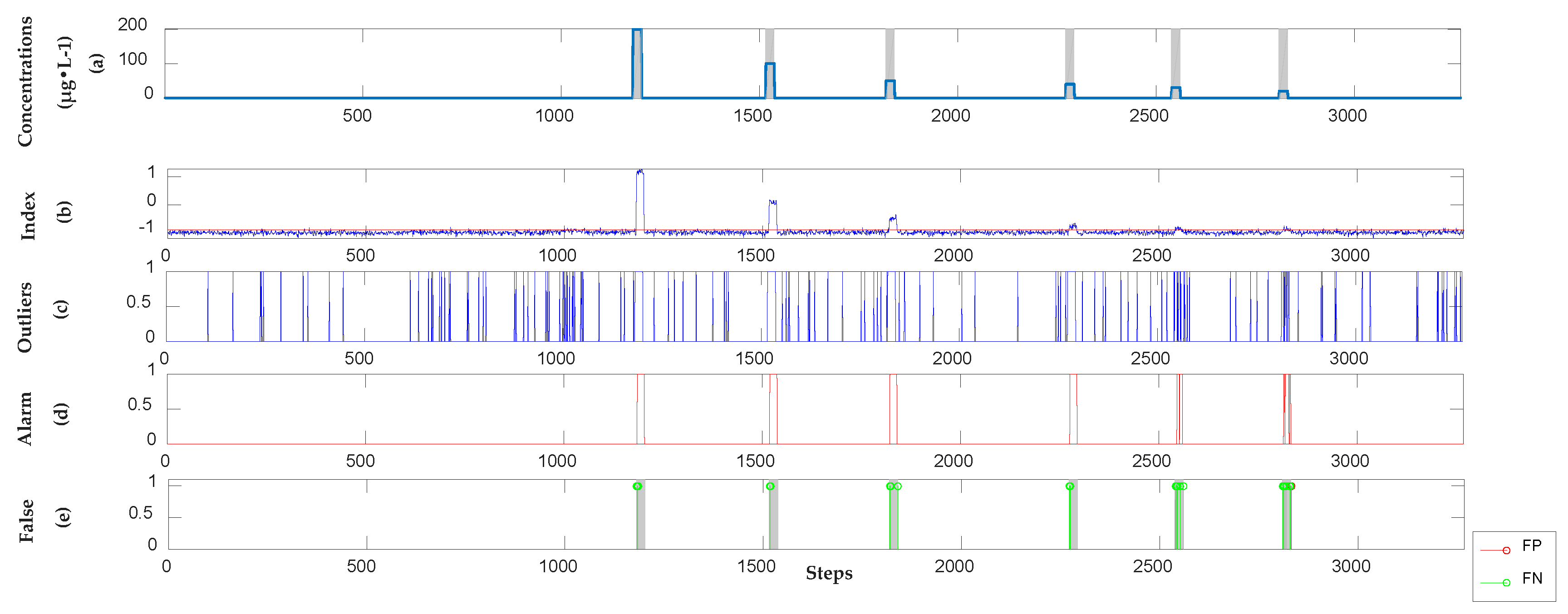
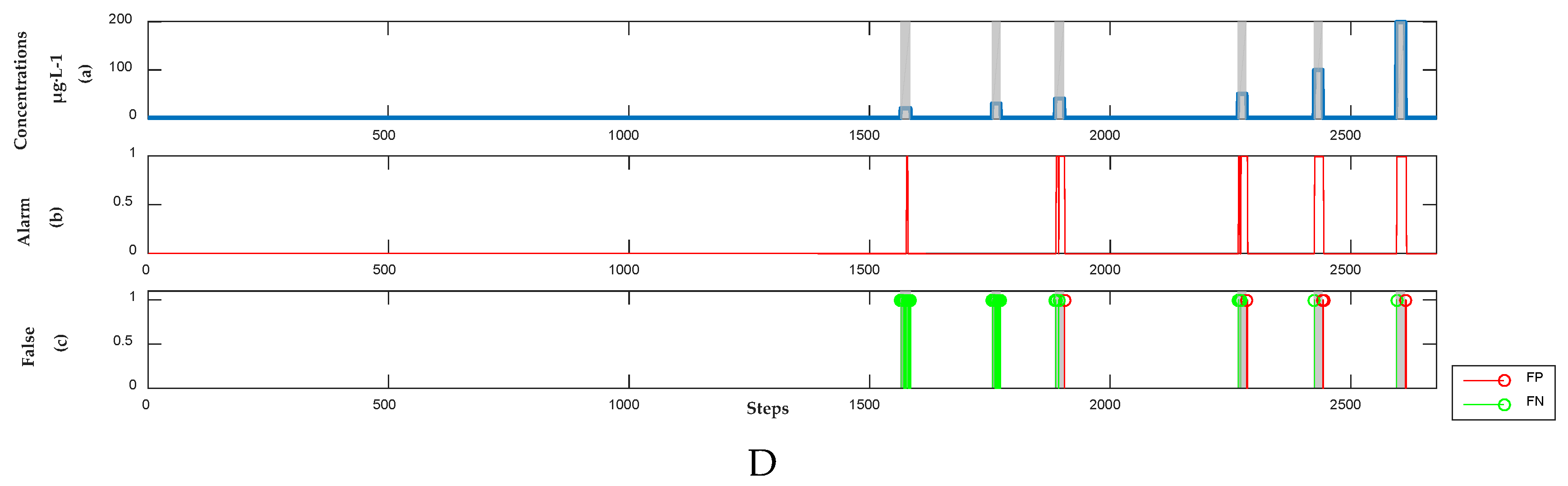
3.2. Detection Results of Organic Contamination Events
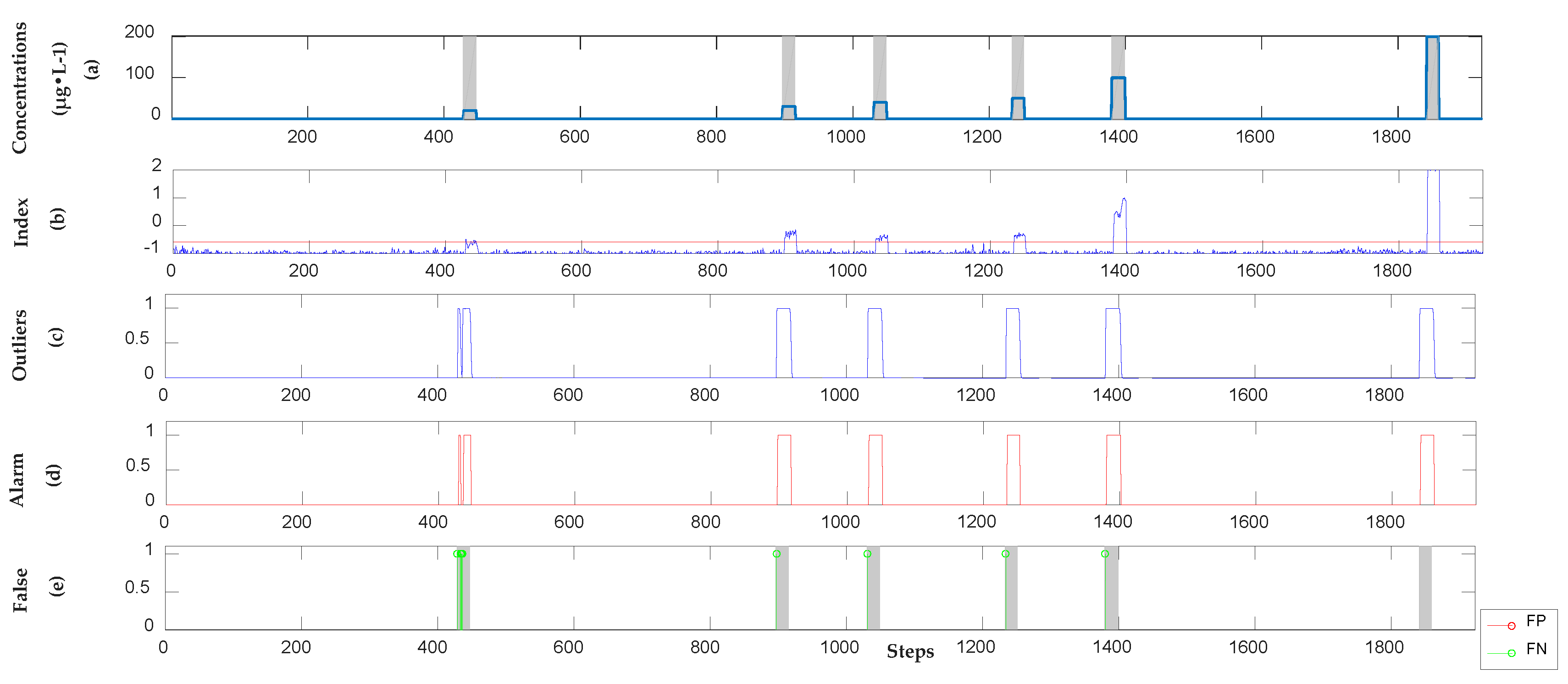
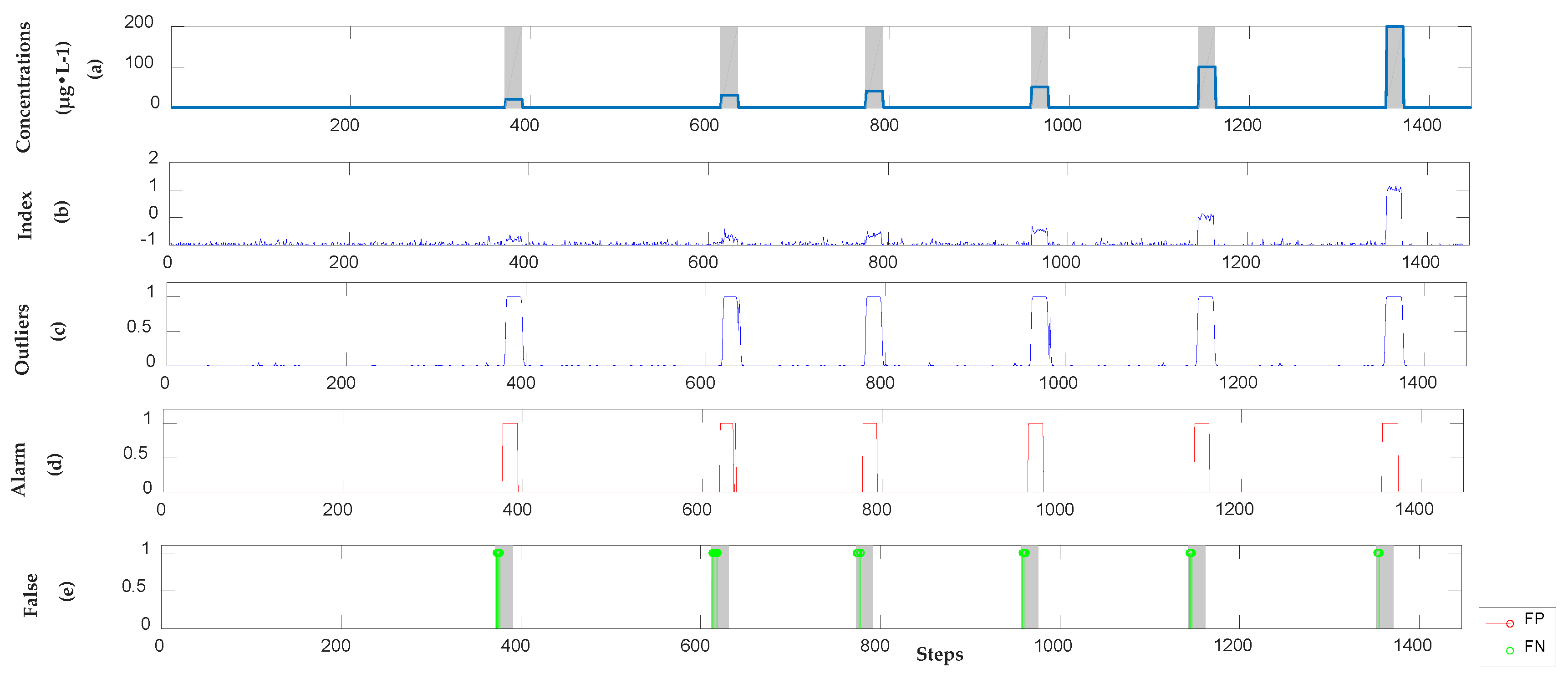
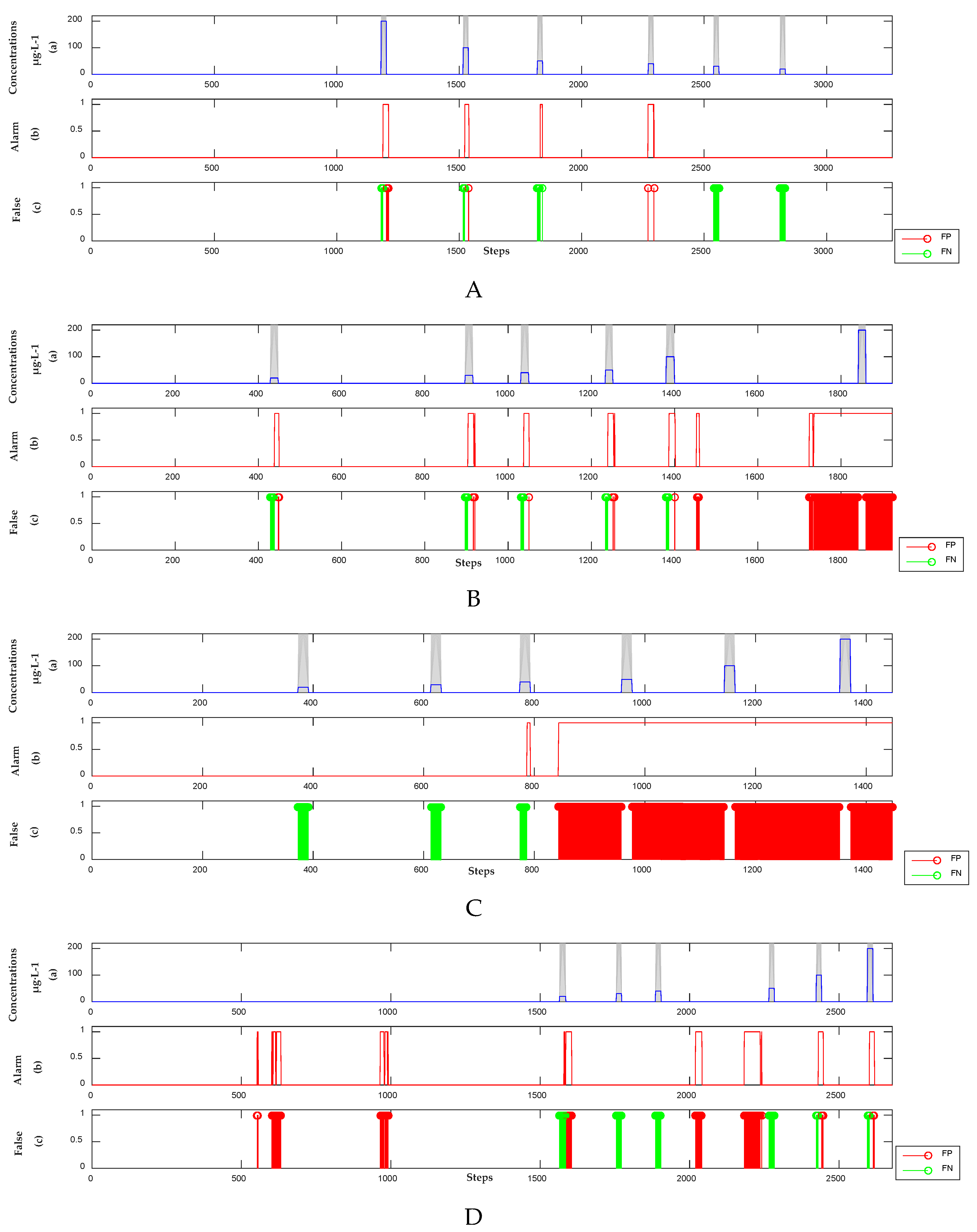
3.2.1. Detection Results of Semi-Supervised Learning Model
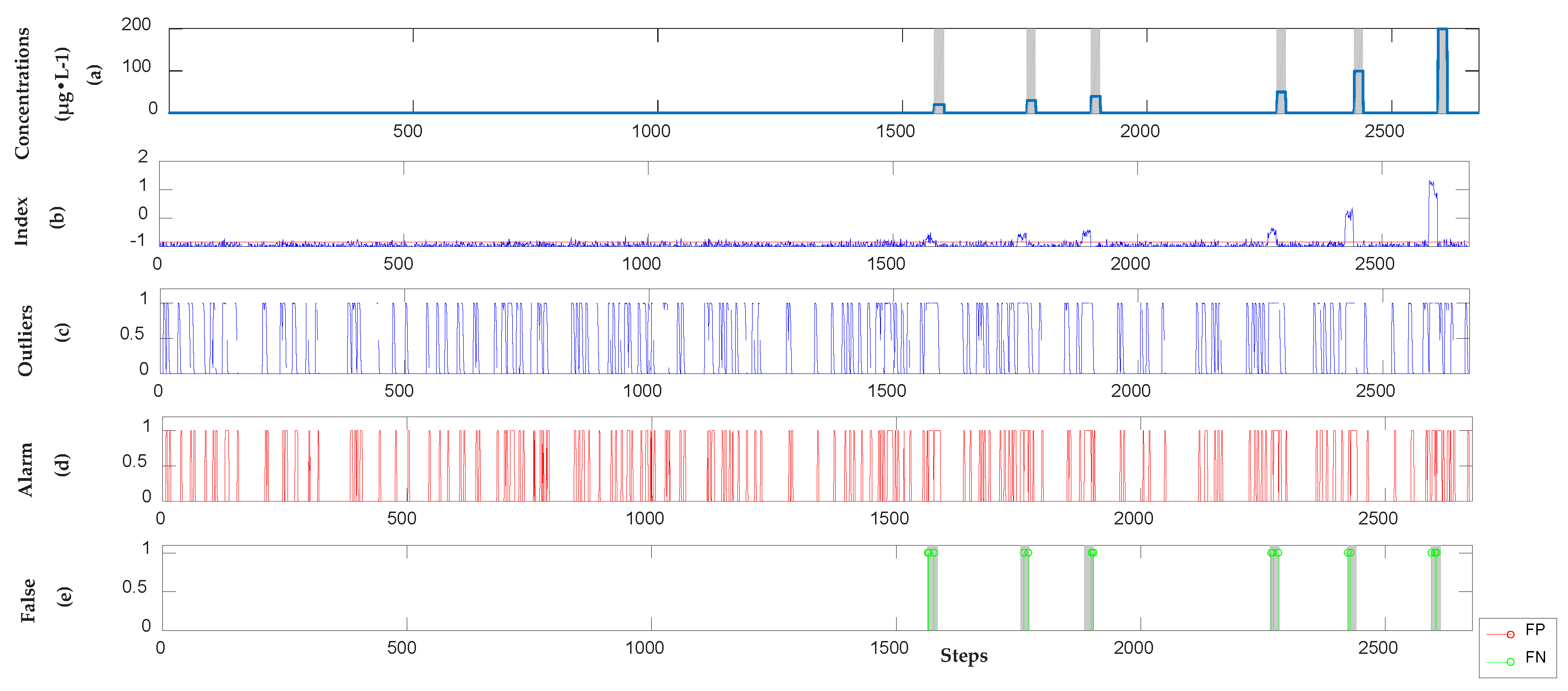
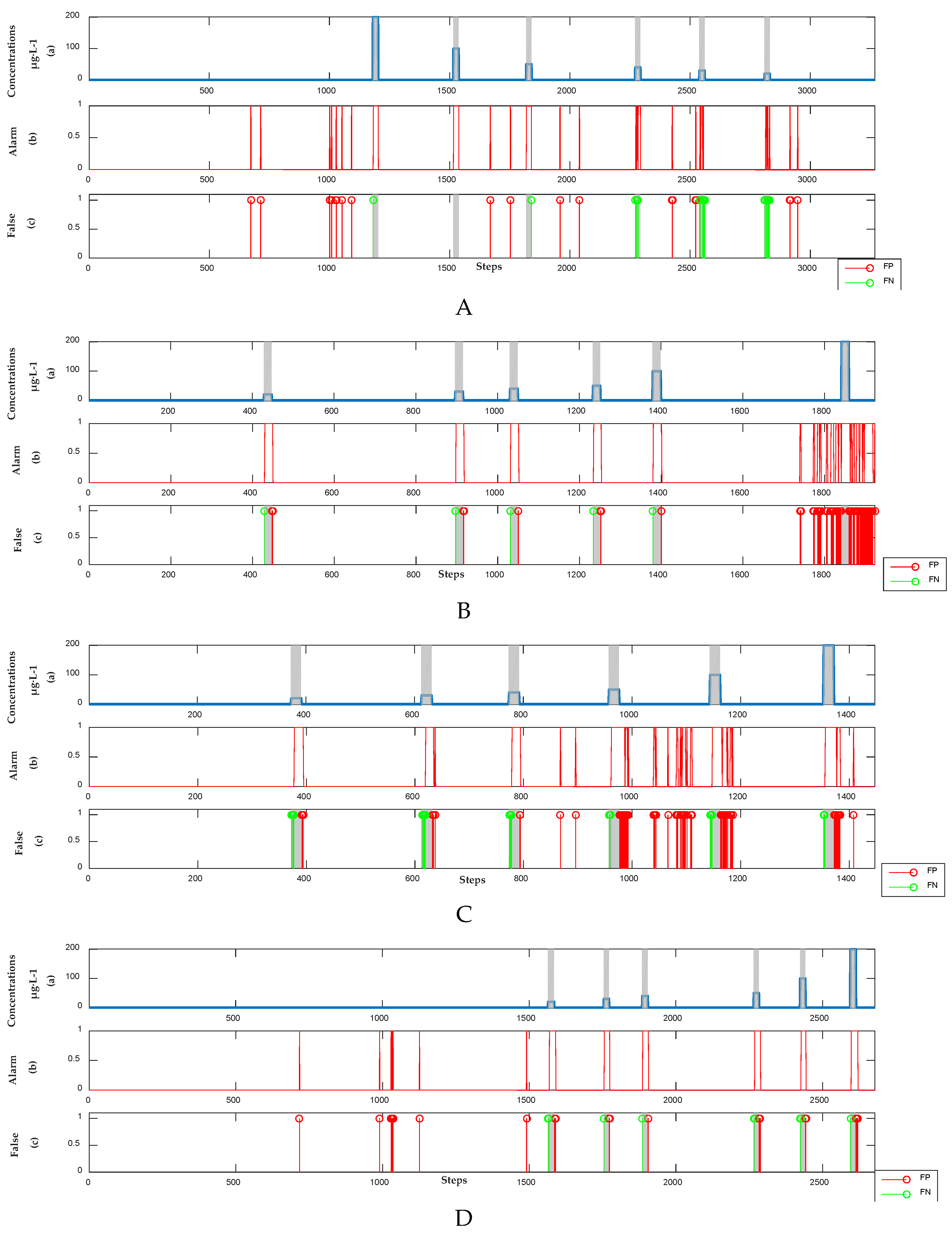
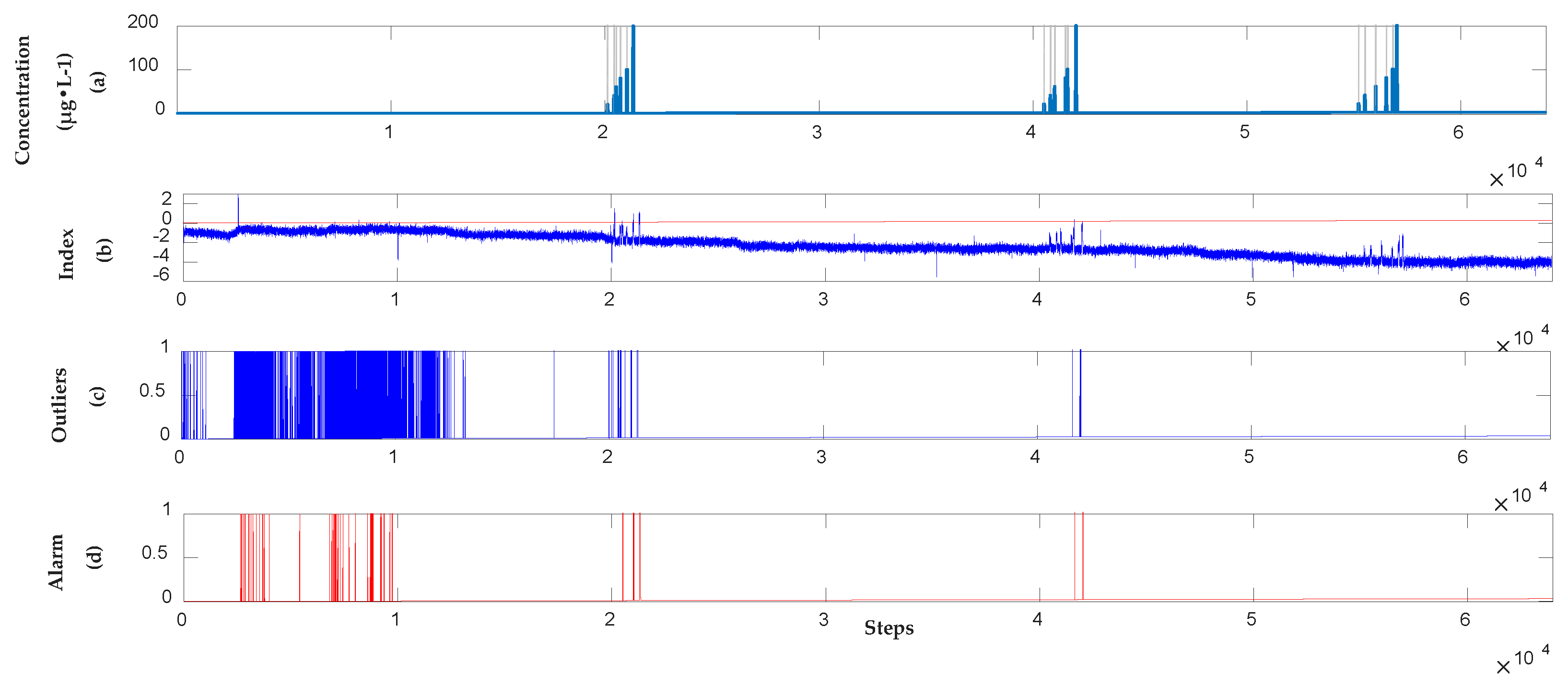
3.2.2. Detection Results of Supervised Learning Model
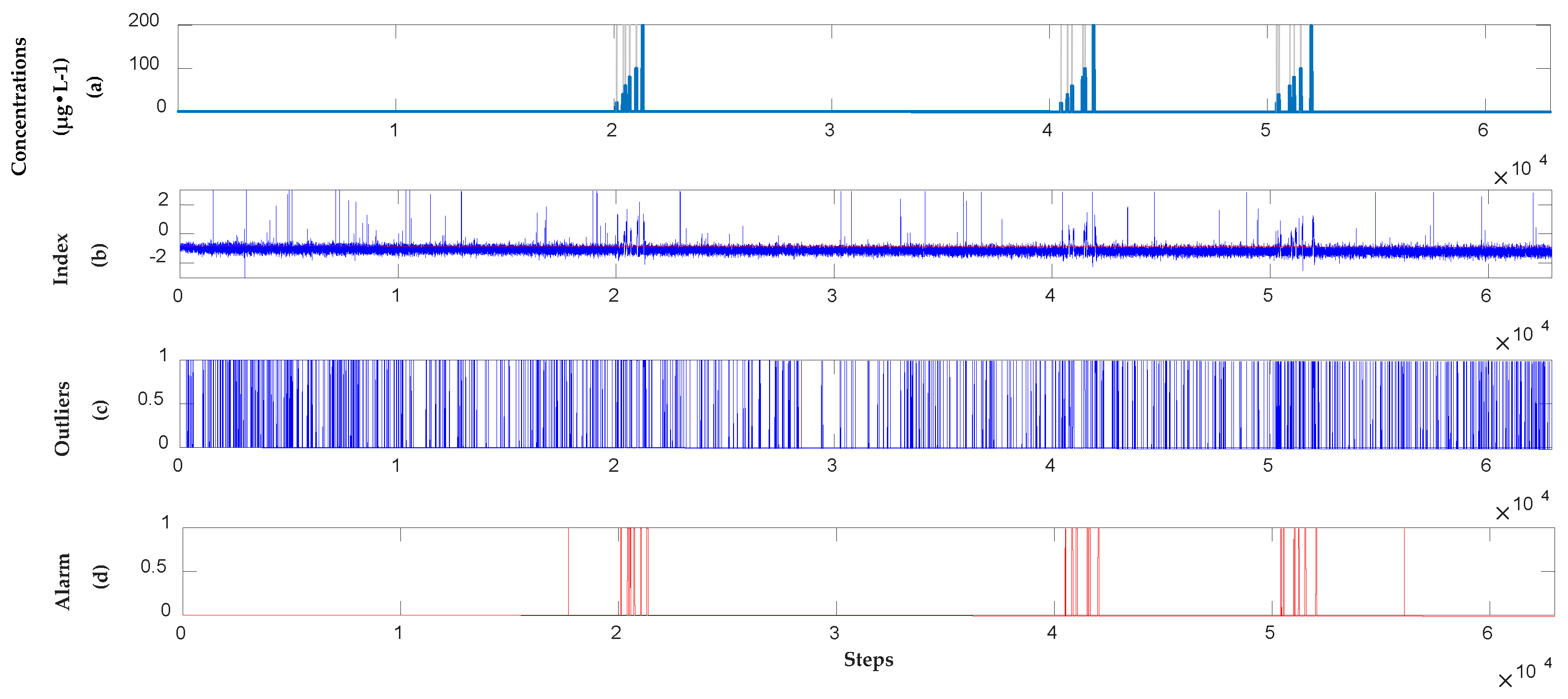
3.2.3. Detection Results of Unsupervised Model
3.2.4. Analysis Results
4. Discussion
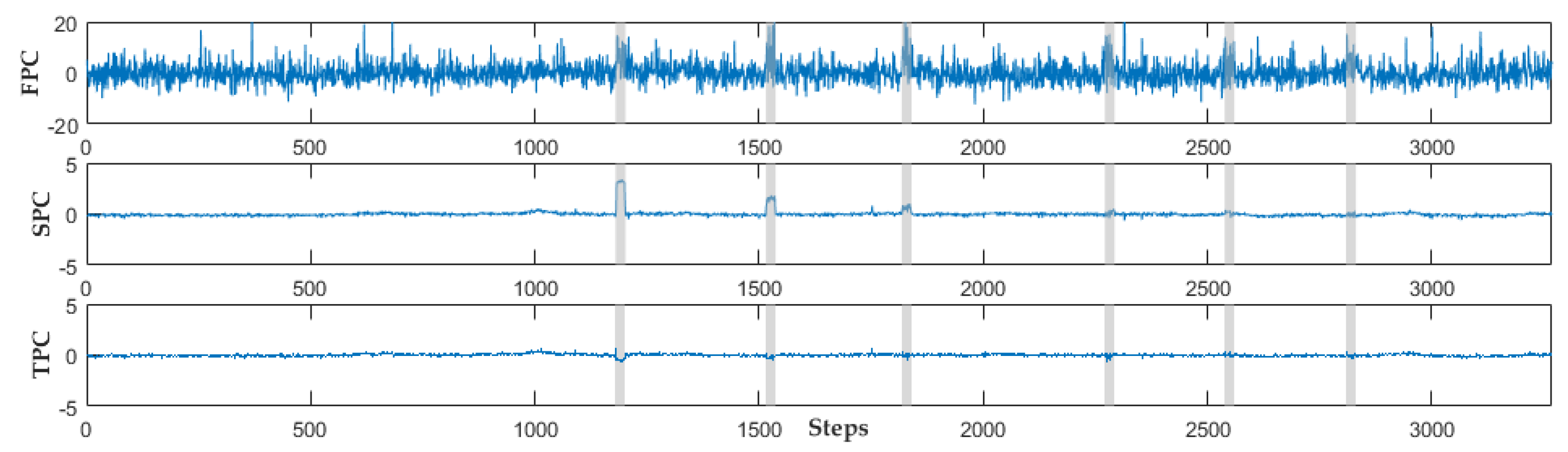
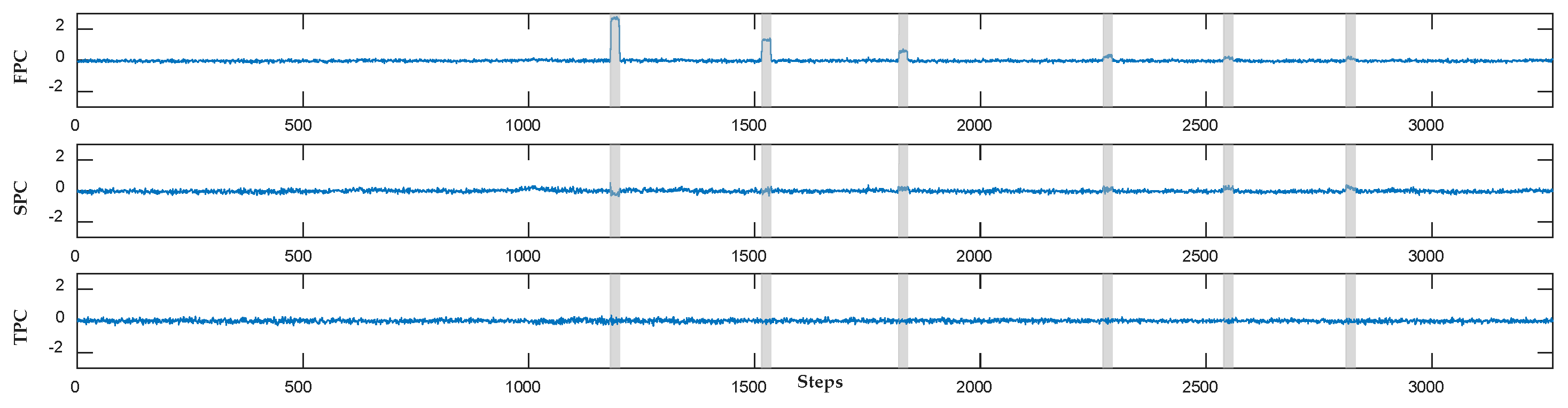
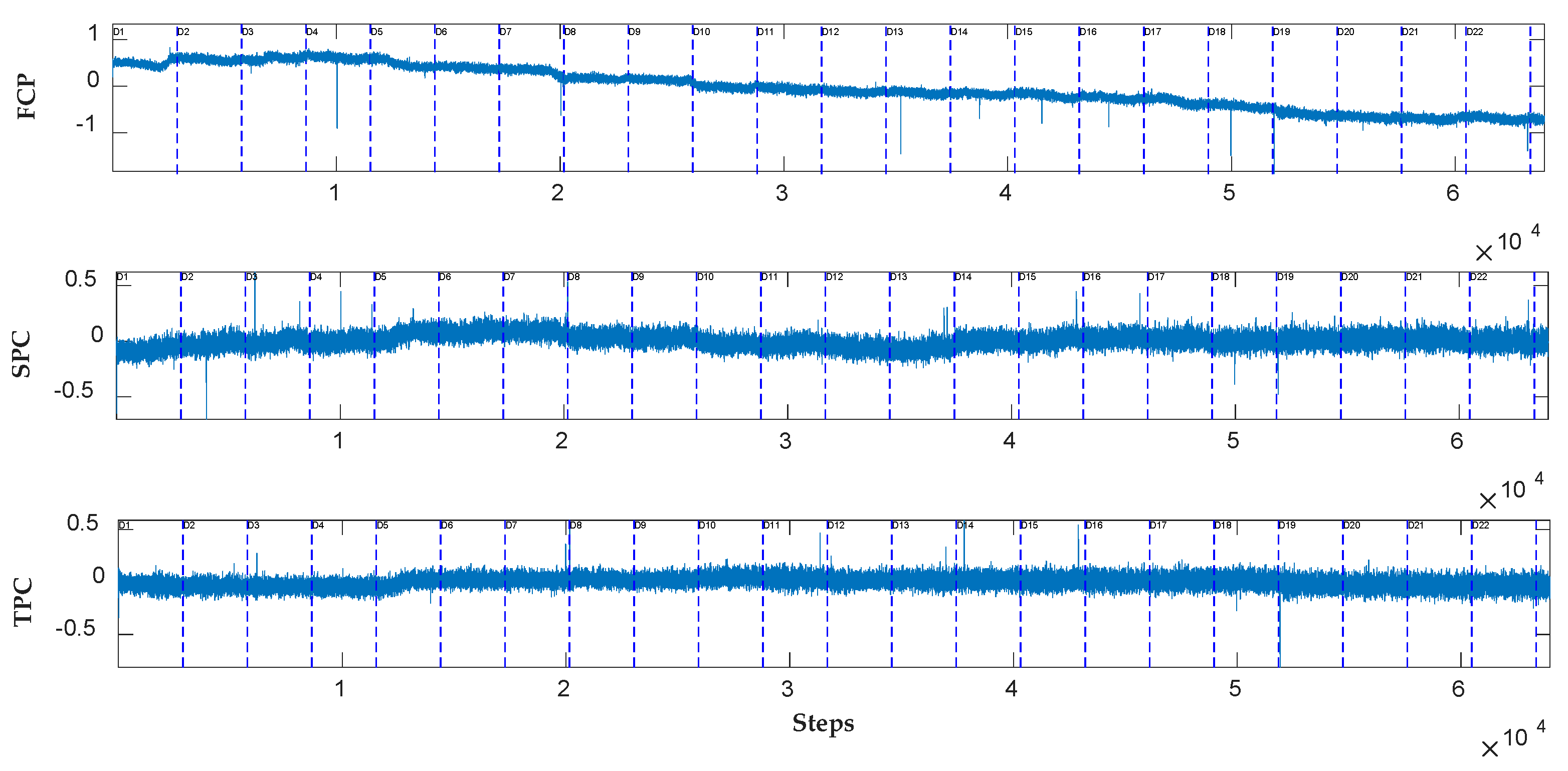
4.1. Effect of Dynamic Orthogonal Projection Correction
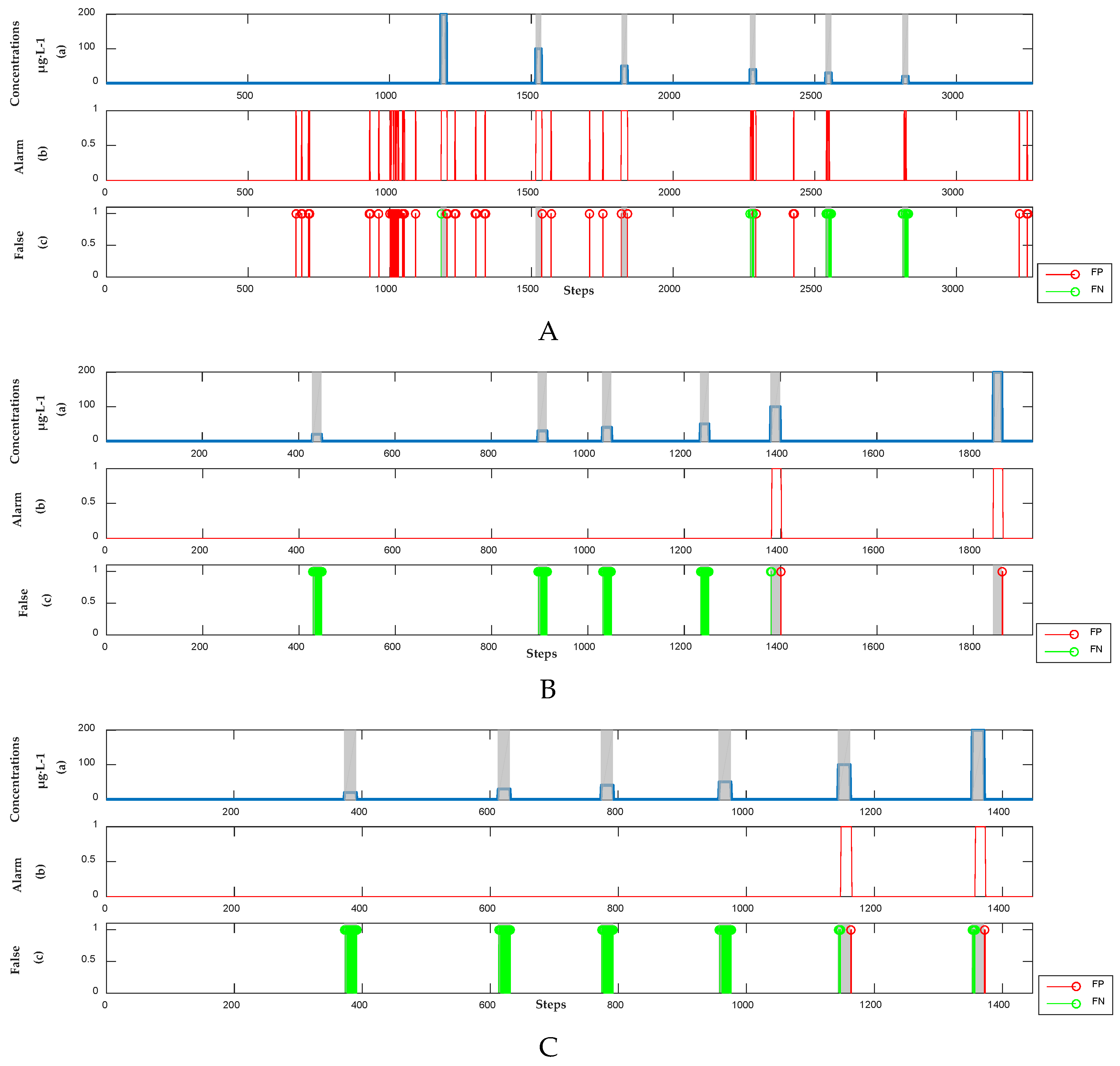
4.2. Comparison of the Adaptability between the Supervised and Semi-Supervised Models When the Baseline Gradually Drifts
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Piao, S.; Ciais, P.; Huang, Y.; Shen, Z.; Peng, S.; Li, J.; Zhou, L.; Liu, H.; Ma, Y.; Ding, Y.; et al. The impacts of climate change on water resources and agriculture in China. Nature 2010, 467, 43–51. [Google Scholar] [CrossRef] [PubMed]
- Hasan, J.; States, S.; Deininger, R. Safeguarding the security of public water supplies using early warning systems: A brief review. J. Contemp. Water Res. Educ. 2004, 129, 27–33. [Google Scholar] [CrossRef]
- Conde, E.F. Environmental Sensor Anomaly Detection Using Learning Machines; Utah State University: Logan, UT, USA, 2011. [Google Scholar]
- Kühnert, C.; Baruthio, M.; Bernard, T.; Steinmetz, C.; Weber, J. Cloud-based event detection platform for water distribution networks using machine-learning algorithms. Procedia Eng. 2015, 119, 901–907. [Google Scholar] [CrossRef]
- Hou, D.; He, H.; Huang, P.; Zhang, G.; Loaiciga, H. Detection of water-quality contamination events based on multi-sensor fusion using an extented dempster-shafer method. Meas. Sci. Technol. 2013, 24, 055801. [Google Scholar] [CrossRef]
- Liu, S.; Che, H.; Smith, K.; Lei, M.; Li, R. Performance evaluation for three pollution detection methods using data from a real contamination accident. J. Environ. Manag. 2015, 161, 385–391. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Smith, K.; Che, H. A multivariate based event detection method and performance comparison with two baseline methods. Water Res. 2015, 80, 109–118. [Google Scholar] [CrossRef] [PubMed]
- Huang, P.; Yu, J.; Hou, D.; Yu, J.; Tu, D.; Cao, Y.; Zhang, G. Online classification of contaminants based on multi-classification support vector machine using conventional water quality sensors. Sensors 2017, 17, 581. [Google Scholar] [CrossRef] [PubMed]
- Langergraber, G.; Weingartner, A.; Fleischmann, N. Time-resolved delta spectrometry: A method to define alarm parameters from spectral data. Water Sci. Technol. 2004, 50, 13–20. [Google Scholar] [PubMed]
- Langergraber, G.; Fleischmann, N.; Hofstaedter, F. A multivariate calibration procedure for uv/vis spectrometric quantification of organic matter and nitrate in wastewater. Water Sci. Technol. 2003, 47, 63–71. [Google Scholar] [CrossRef] [PubMed]
- Guercio, R.; Di Ruzza, E. An early warning monitoring system for quality control in a water distribution network. WIT Trans. Ecol. Environ. 2007, 103, 143–152. [Google Scholar]
- Dürrenmatt, D.J.; Gujer, W. Identification of industrial wastewater by clustering wastewater treatment plant influent ultraviolet visible spectra. Water Sci. Technol. 2011, 63, 1153–1159. [Google Scholar] [CrossRef] [PubMed]
- Hou, D.; Zhang, J.; Yang, Z.; Liu, S.; Huang, P.; Zhang, G. Distribution water quality anomaly detection from UV optical sensor monitoring data by integrating principal component analysis with chi-square distribution. Opt. Express 2015, 23, 17487–17510. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Hou, D.; Wang, K.; Huang, P.; Zhang, G.; Loaiciga, H. Real-time detection of organic contamination events in water distribution systems by principal components analysis of ultraviolet spectral data. Environ. Sci. Pollut. Res. 2017, 24, 12882–12898. [Google Scholar] [CrossRef] [PubMed]
- Guo, B.; Hou, D.; Jin, Y.; Yin, H.; Huang, P.; Zhang, G.; Zhang, H. Online detecting water quality anomaly from UV/Vis spectra using baseline correction and principal component analysis method. Spectrosc. Spectr. Anal. 2017, 37, 1460–1465. [Google Scholar]
- Yin, H.; Yu, Q.; Dong, H.; Hou, D.; Huang, P.; Zhang, G. Detection of specific contamination events in water distribution system using ultraviolet spectra. In Proceedings of the 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018. [Google Scholar] [CrossRef]
- Huang, G.; Song, S.; Gupta, J.N.; Wu, C. Semi-supervised and unsupervised extreme learning machines. IEEE Trans. Cybern. 2017, 44, 2405–2417. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.H.; Li, M. Semi-supervised learning by disagreement. Knowl. Inf. Syst. 2010, 24, 415–439. [Google Scholar] [CrossRef]
- Blanchard, G.; Lee, G.; Scott, C. Semi-supervised novelty detection. J. Mach. Learn. Res. 2010, 11, 2973–3009. [Google Scholar]
- Boulet, J.C.; Roger, J.M. Pretreatments by means of orthogonal projections. Chemom. Intell. Lab. Syst. 2012, 117, 61–69. [Google Scholar] [CrossRef]
- Poerio, D.V.; Brown, S.D. Dual-domain calibration transfer using orthogonal projection. Appl. Spectrosc. 2017, 72, 378–391. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.W.; Lin, C.J. A simple decomposition method for support vector machines. Mach. Learn. 2002, 46, 291–314. [Google Scholar] [CrossRef]
- Rivas-Perea, P.; Cota-Ruiz, J. An algorithm for training a large scale support vector machine for regression based on linear programming and decomposition methods. Pattern Recognit. Lett. 2013, 34, 439–451. [Google Scholar] [CrossRef]
- Oliker, N.; Ostfeld, A. Comparison of multivariate classification methods for contamination event detection in water distribution systems. Procedia Eng. 2014, 70, 1271–1279. [Google Scholar] [CrossRef]
- Aktekin, T.; Polson, N.; Soyer, R. Sequential bayesian analysis of multivariate count data. Bayesian Anal. 2018, 13, 385–409. [Google Scholar] [CrossRef]
- Perelman, L.; Arad, J.; Housh, M.; Ostfeld, A. Event detection in water distribution systems from multivariate water quality time series. Environ. Sci. Technol. 2012, 46, 8212. [Google Scholar] [CrossRef] [PubMed]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Metz, C.E. Basic principles of roc analysis. Semin. Nuclear Med. 1978, 8, 283–298. [Google Scholar] [CrossRef]
- Hand, D.J.; Till, R.J. A simple generalisation of the area under the ROC curve for multiple class classification problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]
- Arad, J.; Housh, M.; Perelman, L.; Ostfeld, A. A dynamic thresholds scheme for contaminant event detection in water distribution systems. Water Res. 2013, 47, 1899–1908. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z. Multi-instance learning from supervised view. J. Comput. Sci. Technol. 2006, 21, 800–809. [Google Scholar] [CrossRef]
- Ye, X.; Wu, G.; Fan, F.; Peng, X.; Wang, K. Overhead ground wire detection by fusion global and local features and supervised learning method for a cable inspection robot. Sens. Rev. 2018, 38, 376–386. [Google Scholar] [CrossRef]
- Zhou, Z. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real Class | Normal | Abnormal | |
|---|---|---|---|
| Predict Class | |||
| Normal | True Negative (TN) | False Negative (FN) | |
| Abnormal | False Positive (FP) | True Positive (TP) | |
| Organic Contaminant | AUROC | |
|---|---|---|
| phenol | 0.97440 | −0.8131 |
| m-phenylenediamine | 0.96517 | −0.5785 |
| hydroquinone | 0.96957 | −0.8806 |
| resorcinol | 0.95730 | −0.8310 |
| Unsupervised | Supervised | Semi-Supervised | ||||
|---|---|---|---|---|---|---|
| Organic Contaminants | TPR | FAR | TPR | FAR | TPR | FAR |
| phenol | 0.4545 | 0.0041 | 0.7652 | 0.0096 | 0.7576 | 0.0001 |
| m-phenylenediamine | 0.6726 | 0.1094 | 0.9558 | 0.0514 | 0.9204 | 0 |
| hydroquinone | 0.5526 | 0.4144 | 0.7544 | 0.0555 | 0.7368 | 0 |
| resorcinol | 0.2212 | 0.0624 | 0.8673 | 0.0129 | 0.8584 | 0 |
| Unsupervised | Supervised | Semi-Supervised | ||||
|---|---|---|---|---|---|---|
| Organic Contaminants | TP | FP | TP | FP | TP | FP |
| phenol | 4 | 0 | 6 | 14 | 6 | 0 |
| m-phenylenediamine | 6 | 4 | 6 | 8 | 6 | 0 |
| hydroquinone | 1 | 1 | 6 | 11 | 6 | 0 |
| resorcinol | 3 | 7 | 6 | 4 | 6 | 0 |
| Baseline Correction | No Baseline Correction | |||
|---|---|---|---|---|
| Organic Contaminants | TP | FP | TP | FP |
| phenol | 6 | 0 | 6 | 17 |
| m-phenylenediamine | 6 | 0 | 2 | 0 |
| hydroquinone | 6 | 0 | 2 | 0 |
| resorcinol | 6 | 0 | 6 | 0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Q.; Yin, H.; Wang, K.; Dong, H.; Hou, D. Adaptive Detection Method for Organic Contamination Events in Water Distribution Systems Using the UV-Vis Spectrum Based on Semi-Supervised Learning. Water 2018, 10, 1566. https://doi.org/10.3390/w10111566
Yu Q, Yin H, Wang K, Dong H, Hou D. Adaptive Detection Method for Organic Contamination Events in Water Distribution Systems Using the UV-Vis Spectrum Based on Semi-Supervised Learning. Water. 2018; 10(11):1566. https://doi.org/10.3390/w10111566
Chicago/Turabian StyleYu, Qiaojun, Hang Yin, Ke Wang, Hui Dong, and Dibo Hou. 2018. "Adaptive Detection Method for Organic Contamination Events in Water Distribution Systems Using the UV-Vis Spectrum Based on Semi-Supervised Learning" Water 10, no. 11: 1566. https://doi.org/10.3390/w10111566