A Global Optimization-Based Method for the Prediction of Water Inrush Hazard from Mining Floor


1
School of Resources & Safety Engineering, Central South University, Changsha 410083, Hunan, China
2
State Key Laboratory of Coal Resources & Safe Mining, China University of Mining & Technology, Xuzhou 221116, Jiangsu, China
3
School of Energy Science & Engineering, Henan Polytechnic University, Jiaozuo 454000, Henan, China
4
State Key Laboratory for Geomechanics & Deep Underground Engineering, China University of Mining & Technology, Xuzhou 221116, Jiangsu, China
*
Authors to whom correspondence should be addressed.
Water 2018, 10(11), 1618; https://doi.org/10.3390/w10111618
Submission received: 21 September 2018
/
Revised: 1 November 2018
/
Accepted: 7 November 2018
/
Published: 9 November 2018
(This article belongs to the Special Issue Practical Strategies for Managing Water Balance and Quality at Open Pit Mines)
Abstract
:Water inrush hazards can be effectively reduced by a reasonable and accurate soft-measuring method on the water inrush quantity from the mine floor. This is quite important for safe mining. However, there is a highly nonlinear relationship between the water outburst from coal seam floors and geological structure, hydrogeology, aquifer, water pressure, water-resisting strata, mining damage, fault and other factors. Therefore, it is difficult to establish a suitable model by traditional methods to forecast the water inrush quantity from the mine floor. Modeling methods developed in other fields can provide adequate models for rock behavior on water inrush. In this study, a new forecast system, which is based on a hybrid genetic algorithm (GA) with the support vector machine (SVM) algorithm, a model structure and the related parameters are proposed simultaneously on water inrush prediction. With the advantages of powerful global optimization functions, implicit parallelism and high stability of the GA, the penalty coefficient, insensitivity coefficient and kernel function parameter of the SVM model are determined as approximately optimal automatically in the spatial dimension. All of these characteristics greatly improve the accuracy and usable range of the SVM model. Testing results show that GA has a useful ability in finding optimal parameters of a SVM model. The performance of the GA optimized SVM (GA-SVM) is superior to the SVM model. The GA-SVM enables the prediction of water inrush and provides a promising solution to the predictive problem for relevant industries.
1. Introduction
Water seepage causes constant difficulties in underground mining and creates a range of unstable operation problems. Handling, pumping, treatment and the disposal of mine water are serious problems in the observed situation [1]. The inundation in mining disasters is a sudden, violent and veritable irruption. Sudden water inrush results in hundreds of fatalities in various countries in the world [2]. In recent years, safe mining production of coal is improved with the development of science and technology. In developed countries, such as the United States, only a very few of water inrush accidents occurred with the application of the dewatering technique in mining [3]. However, more than 90% of the water inrush accidents in China occurred due to the water inflow from karst aquifers through coal seam floors [4]. According to incomplete statistics, from 2002 to 2012, there were 1110 inrush accidents involving various kinds of mines in China, and 4444 were dead and missing. Among them, the number of water damage accidents in individual coal mines in towns and villages accounted for 80% or more in terms of frequency and deaths [5].
Classifying the mine water inrush is necessary for understanding hidden causes of sudden inflows so as to provide remedial measures. A critical review of various inundations has been divided into three categories, namely: (i) event controlled inundation, (ii) accidental inundation and (iii) spontaneous inundation [3,4]. The first and second types are mining-induced inundation, while the third is a natural phenomenon. The event-controlled inundation is associated with caved mine workings below either a confined aquifer or surface bodies of water where the inflow is followed by main and periodic roof falls in the roof strata [3]. The inflow rate of the water increases suddenly from the background level to a peak rate within a short time and is then reduced exponentially to the background level over a period of time [6]. Spontaneous inrush is a natural phenomenon associated with mining in the vicinity of karst aquifers. Accidental inundation, which poses a threat to life and construction, is a major issue in the mining industry due to working surface in the vicinity of large water bodies. A lake or ocean, a large pool of water in an upper seam or water flooding the adjacent ancient workings, if suddenly released to the lower active workings, could easily flood the current working faces with possible fatalities [6].
Coal floor water inrush is one of the main water hazards, posing a serious threat to coal mine safety production [7]. When mining is conducted on the coal seam above the confined aquifer, coal floor rock deformation occurs, as well as failure by the joint action of the mining pressure and confined aquifer. This forms a water inrush pathway from stability to instability for rock strata [8]. As a result, the sudden water pressure discharge from the floor under confined aquifer along the pathway [9]. Effective and timely water inrush prediction is an important way to curb the occurrence of multiple accidents in coal mines [10]. Therefore, an effective water inrush prediction method has been investigated by mine hydrogeologists.
Coal floor water inrush occurs in a complex geoscientific system, which consists of a coal seam, floor confining bed and karst aquifer. This is an open system that continuously exchanges material, energy and information with the external environment. There is a strong nonlinear dynamic relationship between the influencing factors and the water inrush quantity [11]. Therefore, the prediction method of coal mine water inrush requires an adaptive, self-learning and dynamic nonlinear processing method [12,13].
Prediction of water inrush from the coal floor is a kind of prediction technique. As for the development of forecasting approaches, the most commonly used in early times are mainly statistical methods, such as trend analysis and extrapolation [14]. This method is quite simple to use, because the calculations are not complex. The impact degree can be more objectively reflected by the multi-information composite prediction than single information. It is widely used in mid-term and long-term prediction of sub-regions. GIS-based prediction model of coal floor water inrush is most commonly used [15,16]. Fuzzy system theory is based on fuzzy sets. Fuzzy inference is conducted through fuzzy rules, which are defined in fuzzy sets [17]. Theoretically, it can approximate any non-linear mapping. This is a theoretical basis for fuzzy technique to solve nonlinear and complex problems [18]. A neural network is an artificial network modeled on the human brain’s nervous system [19]. It can achieve impressive feats, and much more effectively compared to traditional computers in terms of pattern recognition, combinatorial optimization and decision-making [20,21]. However, a neural network itself is based on a heuristic method, which cannot control the generalization ability of the network well after training. There are still over-learning problems. Sometimes, it is difficult to obtain the optimal solution. In summary, the theory and method of a nonlinear system applied to the prediction of water inrush from coal seam floor has been a hot topic in recent years [22,23]. The application of emerging model algorithms, such as dissipation, cooperation, mutation, chaos and fractals to water inrush prediction in coal mines, has become a new breakthrough in this field [24].
In terms of coal seam floor water inrush prediction, a truly practical and effective prediction method has not yet been fully realized; there are many theoretical and practical problems that need to be further studied in comprehensive aspects; additionally, the existing water inrush prediction methods need to be further improved in terms of convenient use. Therefore, the prediction method of water inrush from the coal seam floor still needs to be continuously explored. The support vector machine (SVM) has become a research hotspot in the machine learning community, due to its excellent learning performance [25,26]. To automatically determine the optimal or approximate optimal parameters in the parameter space, a genetic algorithm (GA) is employed, as it has a powerful global optimization function [27], including implicit parallelism, high stability of the algorithm, penalty coefficient, insensitivity coefficient and a kernel function parameter for the SVM model. All of these characteristics greatly improve the accuracy and use of the SVM model.
Driven by importance of prediction of water inrush hazards, this study first analyzes influencing factors and provides corresponding data of water inrush cases in Section 2. Section 3 describes a used method of GA to estimate the SVM model and Section 4 presents the detailed calculation results. Finally, the implication of these findings is concluded in Section 5.
2. Influencing Factors and Data Collection Cases of Water Inrush from Coal Floor
2.1. Analysis of Influencing Factors
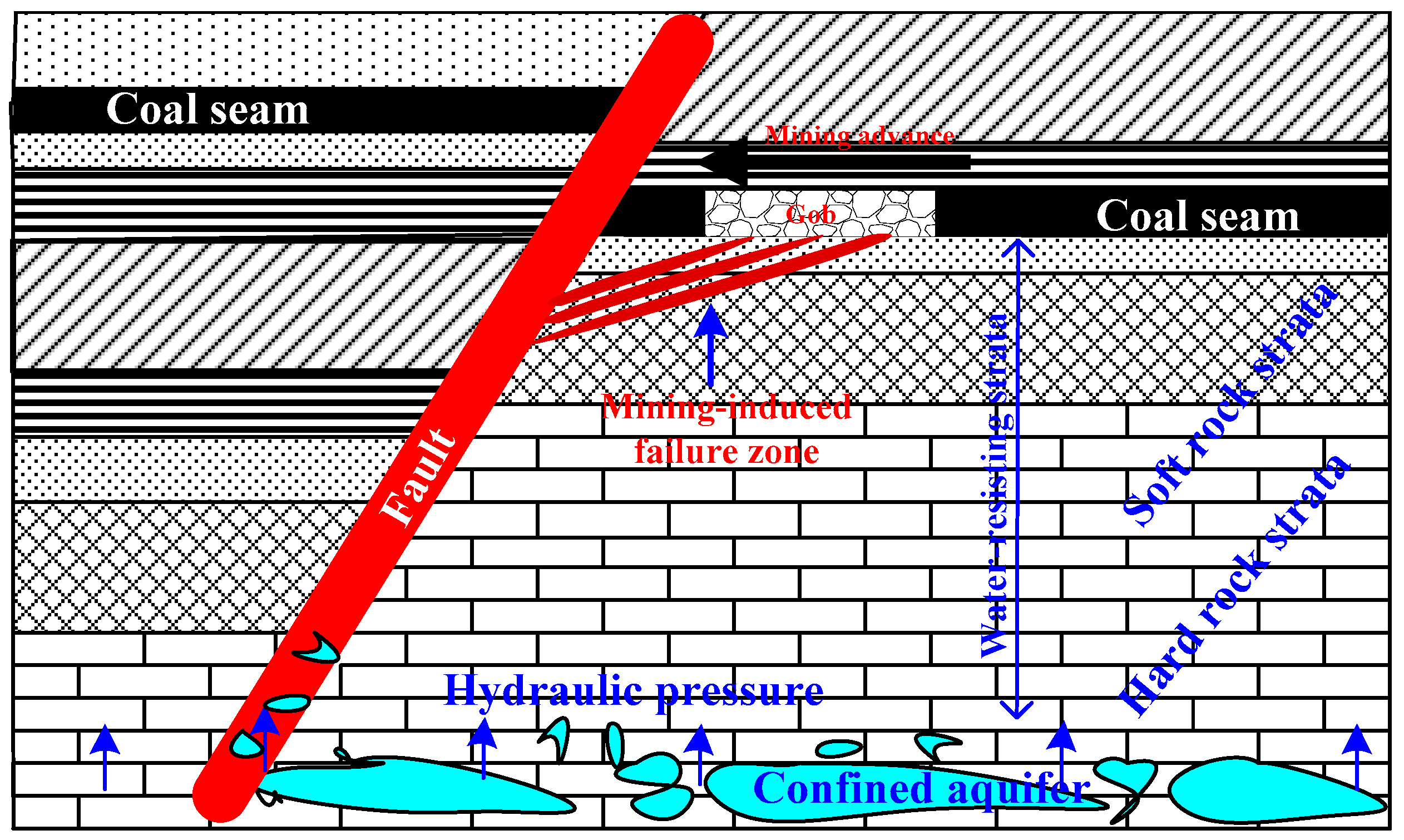
The water inrush from the coal seam floor is affected by various factors, such as geological structure, hydrogeology and mining conditions [28]. As shown in Figure 1, the existence of the confined aquifer under the coal seam is the material basis of water inrush, the hydraulic pressure and the mine pressure is the force source, and the water-resisting strata is the inhibiting condition. Its suppression ability depends on the thickness, strength and combination of the water-resisting strata [29]. When the hydraulic pressure, mine pressure and the stability of the water-resisting strata are in a relatively balanced state, the fault has the controlling effect. According to the in-situ observation of the field, combined with the comprehensive analysis of relevant data, it was concluded that there are five main factors affecting water inrush from floor [9,30,31].
- Aquifer. The aquifer’s water-richness is the material basis for the size of water inrush. It determines the scale of the water hazard and the degree of threat to the mine [31]. Therefore, the aquifer is one of the important factors for water inrush from the coal floor. Water-richness is related to the development of karst fissures, runoff conditions, structural development and burial depth.
- Hydraulic pressure. The hydraulic pressure in the aquifer is the driving force for the water out of the working face. It is the hydrostatic pressure before the effluent. The hydrostatic pressure has an expanding effect on the aquifer fissure [27]. The higher the water pressure, the more significant the effect; water energy of the aquifer after the effluent converts into kinetic energy. The effect is that the fractures are scoured and expanded, the filling material is continuously taken away, channels are more and more opened and the amount of water is getting larger.
- Thickness of the water-resisting strata. Water-resisting strata act as a barrier to the water inrush from the floor. The barrier capacity mainly depends on the thickness of water-resisting strata, mechanical strength of rocks [32,33], and the integrity of the water-resisting rock layer. Under certain conditions, when the thickness of the water-resisting strata is greater with higher strength, the probability of water inrush is lower and vice versa.
- Depth of mining-induced failure zone. The depth of mining-induced failure zone determines the degree of the failure of rock floor. Practice and theories proof that reducing the failure depth of floor mining and increasing the thickness of water-resisting strata are important methods and measures for safe compensated mining under certain premise of conditions [2]. When the failure depth of floor mining is small, the probability of water inrush becomes smaller, and vice versa.
- Fault fall. The damage of the fault to coal rock is mainly manifested in the increase of cracks and pores in the coal and rock layers near the fault [22], and the sharp decrease of strength. The different size of the fault gap can result in different contact between the coal seam and the aquifer in the two plates of the fault. The relationship analysis shows that when the fault fall is larger, the impact becomes greater on the fault, and a fault fall is more likely to occur on the floor water inrush.
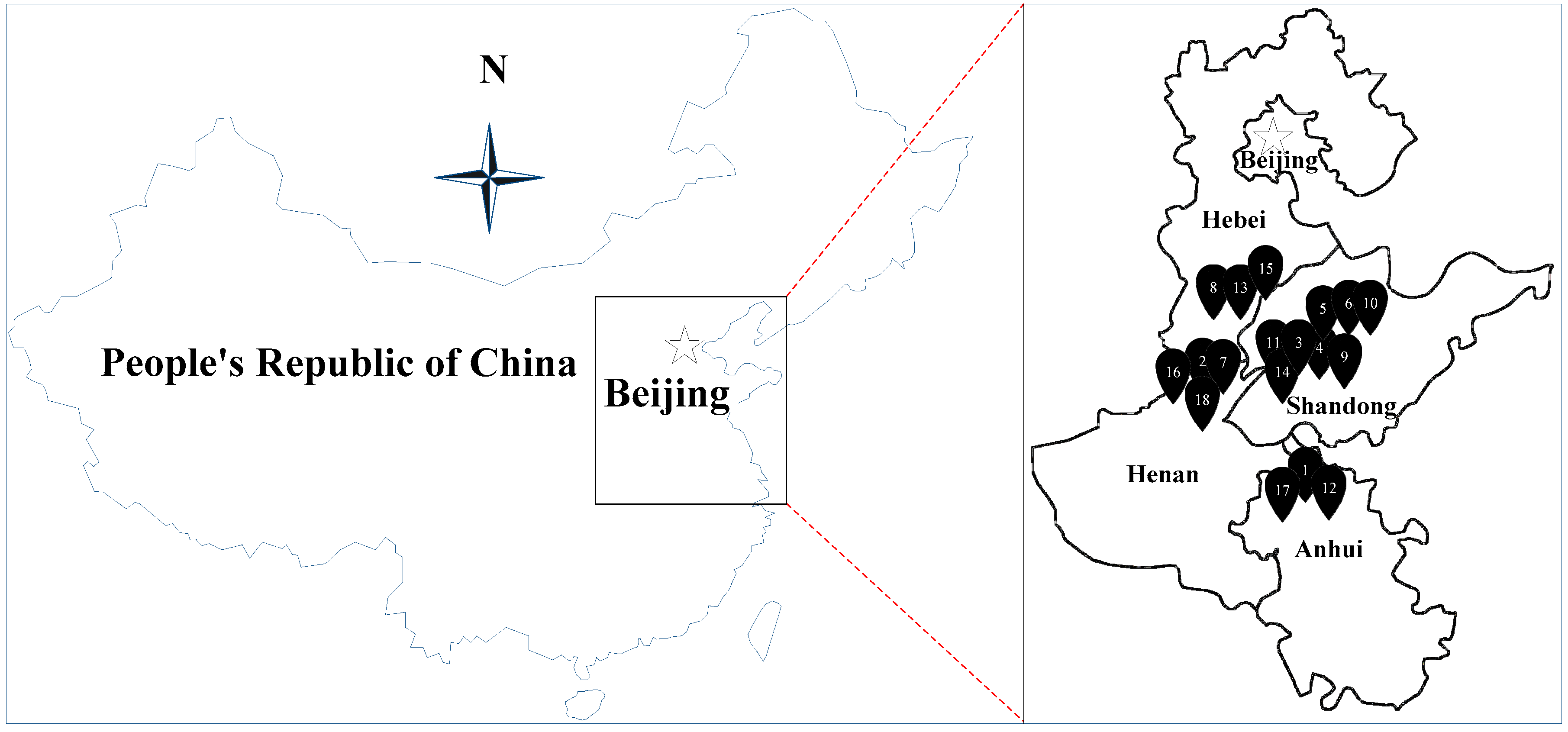
2.2. Data Collection of Water Inrush Cases
Karst water inrush is one of the major mine disasters in North China. It has many distinguishing features: The water source mainly exists in the fractures of Ordovician karst limestone aquifers, followed by that of the Carboniferous and Cambrian aquifers. The karst formation of the water inrush strata is dominated by fractures, followed by caves, pores and underground river pipes. The water inrush deposits are generally located below the local erosion reference surface; the water storage structure has a large scale, most of which have abundant water resources for storage and supply [34]. The water inrush method mainly presents as accidental inrush from coal floor, resulting in serious damage of coal mines. In particular, the five influencing factors listed above all have the obvious characteristics [35].
3. Methodology
In order to accurately predict the water inrush from the coal seam floor, this paper first initialized the raw data so that it satisfied the input requirements of SVM training samples. At present, this new theoretical method shows unique advantages and good application prospects in solving practical problems, such as small samples, nonlinearity, high dimensionality and local minimums [36]. It has a good application in pattern recognition, density estimation, data mining, two-dimensional object recognition, remote sensing image analysis, nonlinear system control, function approximation, function fitting and regression estimation. However, there are few researches on SVM prediction with strong color noise performance [37]. Next, for SVM, as in the radial basis function (RBF) network, there still exists the following problem: How to select a kernel function and the most suitable kernel function for specific problems. The prediction performance of the SVM is sensitive to the choice of parameters [38].
Figure 3 shows the established prediction system. Firstly, the original data was defined and initialized as input training data set of SVM model, namely, the data processing stage of the prediction model established in this paper. Then, by coding the training data set, initial population parameters were randomly generated to produce a group of population. Through SVM training, the fitness of each individual in the population could be calculated. According to the fitness evaluation function, optimal SVM parameters were found.
After finding the optimal parameters, if the termination conditions of the SVM training model were met, i.e., the value of the loss function was smaller than that of the learning error rate, the optimal SVM model was output. If it did not satisfy the conditions, a series of genetic operations were performed on the existing optimal parameters through the GA algorithm to carry out operations of copying, crossover and mutation. Then, new parameter populations were generated, training was continued and fitness was evaluated until the optimal SVM parameters were found and the optimal SVM model was output. This process was the GA optimization SVM platform (GA-SVM) in this article.
Finally, according to the existing SVM model, the test data set was input into the trained SVM model. The actual data were compared and analyzed on the basis of the output results. According to the error analysis results, the accuracy of the prediction was judged on whether the trained SVM reached a predetermined precision requirement. If the requirements were not satisfied, i.e., the value of the loss function was larger than that of the learning error rate, the SVM model needed to be improved. If the requirements were met (the termination conditions of the SVM training model were met), the actual coal seam floor was predicted based on the SVM model optimized by the GA algorithm and applied to practice. This was the forecast and recall stage.
3.1. Data Preprocessing
As the classification model was generated, the selection of training samples had a certain influence on the classification results [39,40,41]. If there were a small number of samples, it as easy to cause the under-learning; if there were a large number of samples, it might increase training. It was easy to cause over-learning. The key was to select representative samples for training.
Because the research data were measurement data of each coal mine, there were many unpredictable qualitative factors. Therefore, in order to meet the input data requirements of SVM, i.e., feature vectors of the classification model, the existing sample data were reprocessed in this paper. First of all, according to Jin’s research [42], the aquifer and the maximum water inrush volume is defined as shown in Table 2. It can be seen from Table 2 that through the value of the variable, the actual concept of water inrush, the aquifer can be quantified to facilitate the input of the SVM training data set. By collecting data of maximum water inrush of cases in Table 1, the input information for water inrush grade is listed in Table 3.
3.2. GA-SVM Coupling Method
3.2.1. SVM Prediction
SVM is a new generation of machine learning technology based on the statistical learning theory [43,44,45], which is better at solving practical problems, such as a small sample, nonlinearity, high dimension and local minimum point. SVM is based on optimal methods and statistical theory. It follows the principle of Structural Risk Minimization (SRM) and can handle small samples, high dimensionality and nonlinearity issues. It is widely used to solve the problem of pattern recognition and function fitting [46].
The kernel parameter and penalty factor of SVM have a great influence on the prediction effect, however, the theory itself does not give the best method to obtain the kernel parameter and the penalty factor. The main idea is: There are sample data, , in which is the sample input and is the sample output. Firstly, the input vector was mapped from the original space to a high-dimensional feature space (Hilbert space) by using the nonlinear mapping . Then, the optimal decision function was constructed by using the structural risk minimization principle in this high-order feature space, and the kernel function of the original space was used to replace the dot product operation in the high-dimensional feature space to avoid complex operations. Thus, the nonlinear function estimation problem transformed into a linear function problem in the high-dimensional feature space [47].
The form of the optimal decision function of a structure is as follows:
Therefore, the goal is to use the structural risk minimization principle to find the parameters and , making for the input outside the sample, which is equivalent to solving the following problems:
where is the complexity of the control model of confidence interval; is the Error penalty function, i.e., penalty parameter, which represents the compromise between the smoothness of the function and the allowable error greater than the value of , ; and is the experience risk, namely the insensitive loss function.
Lagrange multipliers are introduced to construct the Lagrange function, through the dual problem of the original problem is obtained. The dual form can be used to establish the Lagarangian functions according to the constraints of the objective function machine:
According to the optimization conditions:
then:
Based on this, the solution to the optimization problem can be solved by solving linear equation:
As previously mentioned, there is a complex and nonlinear mapping relationship between water inrush from a coal seam floor and its influence factors [48,49,50]. Using the latest machine learning tool based on statistical learning theory, the support vector machine can express the non-linear relationship between them, so to conduct water inrush prediction. At the same time, the problem of coal floor water inrush prediction is essentially a typical two-category classification problem, because no matter how large the number of influencing factors is, or how complex the relationship between the factors and their classification results, there are only two possibilities, namely, water inrush and no water inrush. That is to say, in theory, water inrush can be predicted completely through proper classification force. SVM is specially designed for finite samples. It has a strict theoretical basis and can solve practical problems such as small samples, nonlinearity, high dimensionality, and local minimums.
Specifically, the water inrush prediction of the support vector machine is to map samples of the input space to a high-dimensional feature space through some kind of non-linear function relationship. Through the classifier processing, the prediction result of the sample can be obtained, and the model can be expressed as:
where is the samples in the samples and is the kernel function. The model inputs are the actual field measurement data, and the output is the corresponding prediction result. The SVM prediction model is listed as Figure 4.
3.2.2. GA-SVM Prediction
According to the basic principle of the SVM model, the SVM model parameters mainly include the penalty parameter C, the insensitivity coefficient ε, the kernel function and the corresponding parameters. The determination of these three parameters will greatly affect the accuracy of the SVM model. Parameters of SVM have great influence on the efficiency of the algorithm and the ability of generalization and prediction. Their choice is an important content of building a SVM model. The emergence of genetic algorithms makes it possible.
The principle of the genetic algorithm (GA) is derived from Darin’s evolution theory and Mendel’s genetic theory [51,52]. Genetic algorithm expresses the solution of the problem as “chromosomes” (using code to represent strings). The algorithm starts with a bunch of “chromosomal” strings. According to the principle of survivability of the fittest, a highly-adapted “chromosome” is selected for replication, and a new generation of more adaptable environmental “chromosomal” populations is generated through cross and mutational genetic manipulations. The algorithm is carried out from generation to generation. Those models with high fitness will grow exponentially in the later generations, and finally get the chromosome with the highest degree of fitness, that is, the optimal solution to the optimization problem.
Genetic algorithms imitate the evolutionary process of living organisms, use the modern heuristic algorithm [53] of Darwin’s theory of evolutionary “survival of the fittest” to search in the solution space by means of simulated genetic operations (crossover and mutation operations), and to search the optimal in the solution space by selecting operations. On the basis of the SPL method, the genetic algorithm is used to obtain the best or satisfactory layout.
The basic principles of genetic algorithm are as follows:
Assuming that the global optimization problem is considered as (P): , then an invariant scale of the solution problem (P), which is assumed to be N, is described as follows:
Step 1: Initialize the population and set ;
Step 2: Calculate the fitness value () of each individual of the current population;
Step 3: Specify the replication probability of its corresponding individual according to adaptability;
Step 4: According to the specified replication probability, a suitable population of the new generation population is produced by the genetic mechanism of crossing and variation.
Step 5: According to some selection rules, a new generation of population is determined from the candidate population.
Step 6: Test whether the current population has a satisfactory solution or has reached a preset evolutionary time limit. If it has been satisfied, stop it. Otherwise, let and go to Step 2.
Given that GA has global optimization capabilities, SVM seeks the best compromise between model complexity and learning ability based on limited sample information in order to obtain the best generalization capability. Compared with the traditional neural network, an SVM algorithm can be transformed into a quadratic optimization. Theoretically speaking, the obtained global optimization will solve the problem of local extremum that cannot be avoided in the neural network. SVM topology is determined by support vectors, which avoids the need for empirical trial and error of traditional neural network topology. SVM can also approximate any function with arbitrary accuracy.
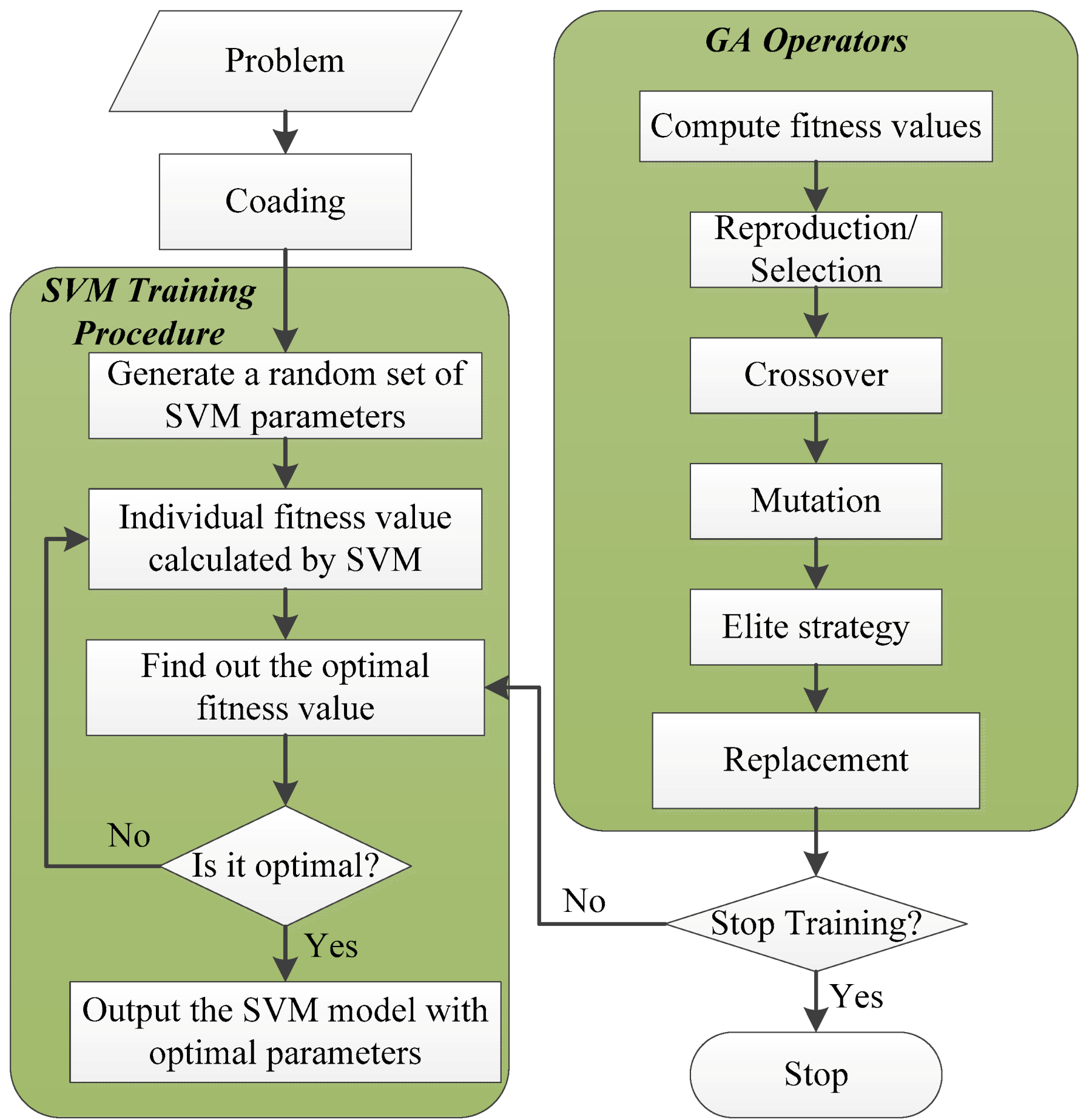
This paper combines the two and proposes a genetic algorithm-based support vector machine (GA-SVM). The basic idea is: Before SVM algorithm, we first used GA to optimize in the random point set, quickly determine the approximate range of the global optimal solution, calculate the initial weight of SVM, and to use the improved SVM algorithm to train the network. The specific algorithms are as follows:
- Initialize the population P, including the determination of cross-scale, crossover probability , mutation probability and initialization of any connection weight. In the coding, the real number code is used.
- Calculate each individual evaluation function, sort them, and select individuals according to their probability values. The probability value is , where is the adaptation value of the individual .
- New individuals and are generated by probability crossing the individual and , and no cross individuals are directly copied.
- Generate and new individual by using probability mutation.
- The new individual is inserted into population P and the evaluation function of the new individual is calculated.
- If a satisfied individual is found, it ends. Otherwise, after achieving the required performance index, the optimal individual in the final group can be decoded to obtain the optimized network connection weight coefficient.
The connection weight coefficient optimized by GA is used as the initial weight; the Least Squares-Support Vector Machine (LS-SVM) algorithm is used to train the network, and the sum of square error is calculated until the specified precision is satisfied. The specific framework of GA-SVM model is shown in Figure 5.
4. Testing Designs and Results
Based on the SVM, the key problems of coal seam floor water inrush prediction model was the determination of input mode, selection of training samples and selection of model structure parameters. One aspect of GA applied to SVM optimization was to optimize the structure of SVM. Moreover, it was also used to optimize the weights of SVM kernel functions. The prediction steps of SVM water inrush from coal seam floor, which were optimized by GA, are as follows:
4.1. Selection of Kernel Function and Parameters
The common kernel functions were the linear kernel function, polynomial kernel function, radial basis function (RBF) kernel function and Sigmoid kernel function. Through statistical analysis of a large number of floor water inrush cases, the five main factors affecting water inrush were: hydraulic pressure, aquifer, thickness of water-resisting strata (floor thickness), depth of water flowing fractured zone on the floor and fault fall (the fault depth is zero in the case of floor failure water inrush).
4.2. Determination of SVM Structure
The SVM prediction model with optimized parameters was trained by training samples to obtain the support vector, and the structure of the SVM was determined.
In this study, 18 typical data of water inrush from coal face floor were selected as samples from a large number of water inrush cases (Table 1). The first 15 samples were selected as the training samples of the network, and the network was optimized and trained with the help of the GA toolbox of the MATLAB software (version: R2014a) and the SVM toolbox. The significance of the selection and parameter determination of the kernel function can be explained by the principle of structural risk minimization (SRM). The SRM principle seeks the minimum empirical risk in every subset. It refers to the subset of functions that determine the VC dimension, where each specific function has different empirical risks due to different parameters and forms. SVM can find the minimum experience risk function. Furthermore, for a given empirical error, the decision function obtained by the SVM is the simplest function that can achieve this empirical error. In the SRM principle, “compromise the empirical risk and confidence range among subsets” is to select the SVM with the smallest actual risk among the SVM in different VC dimensions by adjusting the parameters. The SRM principle is made for the determined data subspace. The data distribution in different data subspaces is different. The empirical risk changes with the VC dimension. Optimizing the SVM kernel parameter (kp) and penalty parameter (C) at the same time is significant: in addition to optimizing C in the same data subspace to obtain the optimal SVM, kp is also optimized to obtain the optimal SVM. The initial values of some parameters through random SVM generation and the range of parameters produced are shown in Table 4.
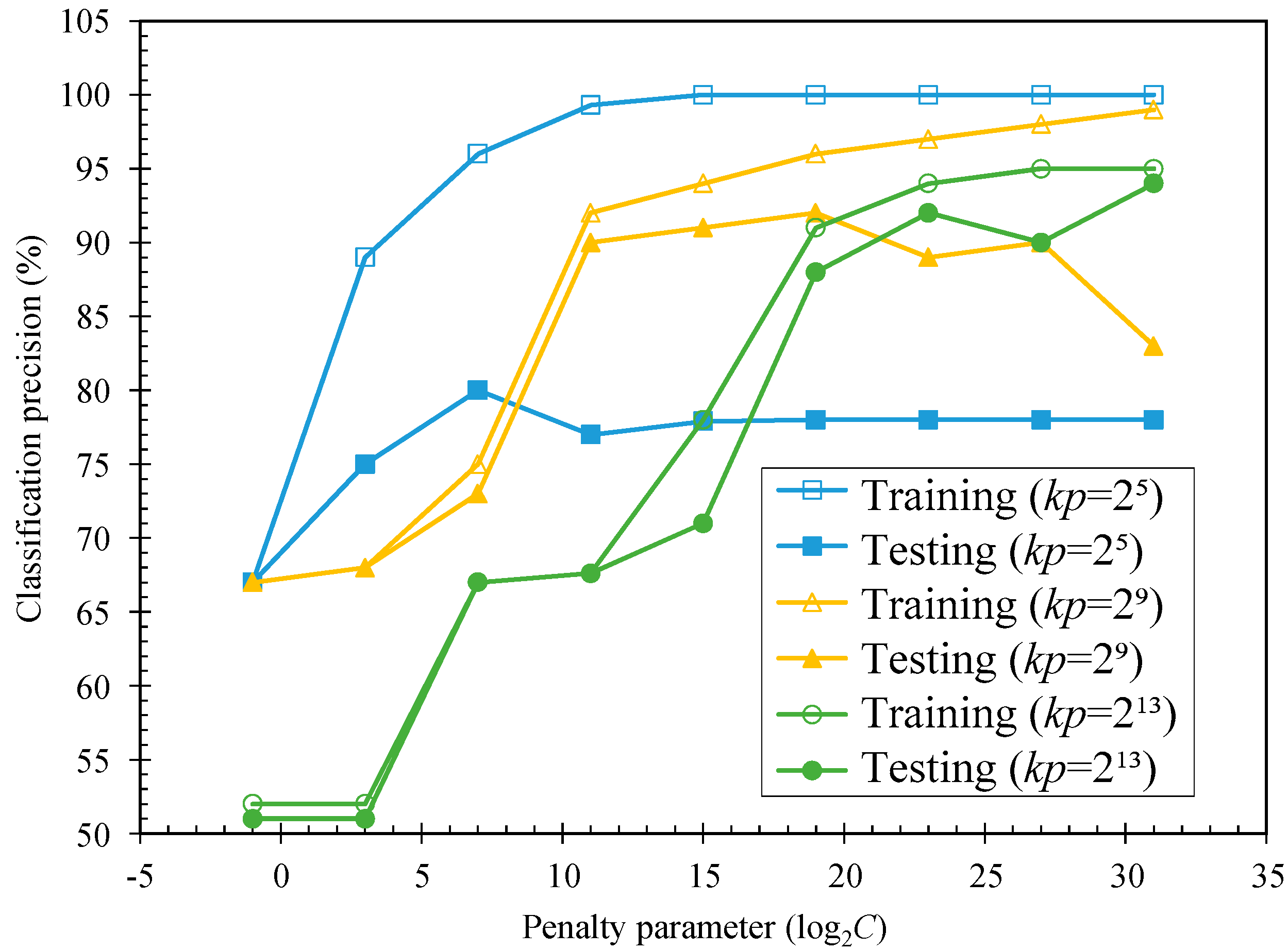
In the training process, the relation curve of the classification precision and the penalty parameter C can be obtained, which is listed in Figure 6. It can be seen from the above that the maximum value of test accuracy and training accuracy did not coincide, further indicating that the traditional principle of minimizing the empirical risk cannot guarantee good promotion. When kp reached a certain value, the number of support vectors started to increase again. At the same time, the corresponding training accuracy and test accuracy began to decrease, indicating that the discriminative ability and promotion performance of the training samples all deteriorated. That is to say, when the kernel parameter increased from zero gradually, the learning and promotion ability of the optimal support vector machine underwent a process from low–high–low. Table 5 shows the statistics of the SVM classifier parameter comparison.
Test results show that SVM had a high prediction accuracy for training samples and test samples; additionally, it had good generalization ability. For the prediction of water inrush on the floor of the working face, SVM was able to achieve more than 90% of the classification results in the case of 20 learning samples. Through the SVM parameters optimized by GA, the final SVM parameters and the trained SVM model were obtained.
4.3. Prediction of the Test Data
After the network passed the training, the test data were input for simulation; after the output, the anti-normalization procedure was run, and the trained support vector predictor was used to predict the test sample. The predicted values of the last three samples in Table 1 were obtained, and the results are shown in Table 6. The prediction error (PE) can be calculated as:
where, is the actual water inrush value; is the predictive value.
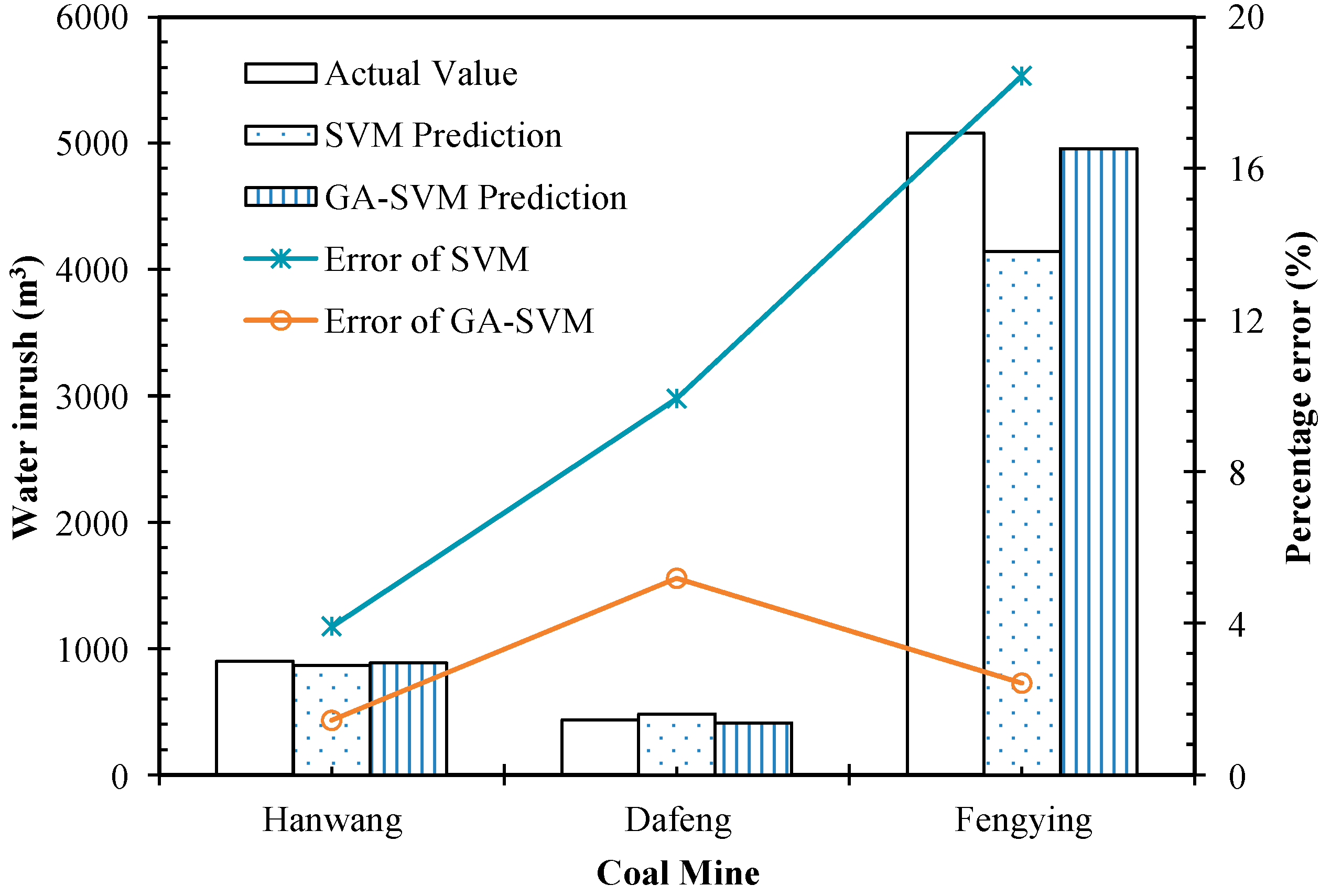
It can be seen from Table 6 that the SVM model has a certain ability to predict; however, the prediction error remained large: The average error of the three test samples was 10.76%, which cannot guarantee the prediction accuracy, or meet the actual water inrush prediction and control. After optimizing the parameters of the GA-optimized SVM model, the average error of the prediction was 3.01%, and the prediction accuracy was high. Meanwhile, the error was very small in predicting the inrush level, and the actual situation of water inrush was well predicted. Therefore, the SVM model optimized by GA can be used to predict the water inrush of the coal seam floor with a high accuracy.
4.4. Comparison and Analysis of Predictive Results
The SVM prediction model optimized by GA had small error and good stability. The execution time of the program (0.0154 s) was shorter than that of the standard SVM algorithm (0.0358 s). It showed that GA was applied to the SVM network to reduce the network oscillation, and the number of iterations was significantly reduced. GA can also use the support vector machine to find the best compromise between the complexity of the model and the learning ability based on the limited sample information, so as to obtain the optimization of the best generalization ability. Combining GA with improved SVM, the prediction of water inrush of coal seam floor was able to be carried out accurately and quickly.
Figure 7 is the comparison of the predicted values of the SVM and the SVM model after the GA optimization. As can be seen from Figure 7, the SVM model can be used to predict water inrush cases. However, the average error of the three test samples was 10.76%, which cannot guarantee the prediction accuracy, or meet the actual water inrush prediction and control. After optimization of the optimal parameters in the training, the GA-optimized SVM model had a higher prediction accuracy. At the same time, the prediction of the inrush had a small error, which is a good predictor of the actual situation of water inrush. Therefore, the SVM model optimized by GA can be used to predict the water inrush of the coal seam floor, and the prediction accuracy is high.
5. Conclusions
There is a highly nonlinear relationship between the water outburst from coal seam floor and geological structure, hydrogeology, aquifer, water pressure, water-resisting strata, mining damage, fault and other factors. Therefore, it is difficult to establish a suitable model by traditional methods to forecast the water inrush quantity from mine floor. Modeling methods developed in other fields can provide adequate models for rock behavior on water inrush.
The prediction model of water inrush from a coal seam floor established in this paper can quickly and accurately predict coal seam floor water inrush under different environments when fitting nonlinear multi variables. The prediction of water inrush from coal seam floor had a high accuracy, and the prediction result was more reliable. Since the SVM has a self-learning function, it can continuously improve the prediction accuracy in the application; thus, this method made a breakthrough in the prediction of coal mine water inrush.
To automatically determine the optimal or approximate optimal parameters in the parameter space, this paper used the powerful global optimization function in genetic algorithm, implicit parallelism, and high stability of the algorithm, penalty coefficient, insensitivity coefficient and kernel function parameter for the SVM mode. All of these characteristics greatly improved the accuracy and usable range of the SVM model.
The coal seam floor water inrush prediction model established in this paper has significant advantages in the fitting of non-linear multivariable, and was able to quickly and accurately predict coal floor water inrush in different environments. The prediction of water inrush from coal seam floor had high accuracy, and the prediction result was more reliable. Since the support vector machine had a self-learning function, it can continuously improve the prediction accuracy in application. Therefore, this method has a broad application prospect in coal mine water inrush.
Author Contributions
D.M. and H.D. conceived and designed the numerical model; D.M. and Q.L. performed the numerical simulation; X.C. and Q.Z. analyzed the data; D.M. and L.Z. wrote and revised the paper.
Funding
This work was supported by the National Natural Science Foundation of China (51804339 and 51774110). The first author would like to thank the financial supported by the Research Fund of State Key Laboratory of Coal Resources and Safe Mining, CUMT (SKLCRSM18KF024).
Acknowledgments
The authors would like to thank the numerical assistance from the research team of Jida Huang in China University of Mining and Technology.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wu, Q.; Guo, X.; Shen, J.; Xu, S.; Liu, S.; Zeng, Y. Risk assessment of water inrush from aquifers underlying the Gushuyuan coal mine, China. Mine Water Environ. 2017, 36, 96–103. [Google Scholar] [CrossRef]
- Yin, S.; Han, Y.; Zhang, Y.; Zhang, J. Depletion control and analysis for groundwater protection and sustainability in the Xingtai region of China. Environ. Earth Sci. 2016, 75, 1246. [Google Scholar] [CrossRef]
- Singh, R.N. Mine inundations. Int. J. Mine Water 1986, 5, 1–28. [Google Scholar] [CrossRef]
- Sammarco, O. Spontaneous inrushes of water in underground mines. Int. J. Mine Water 1986, 5, 29–41. [Google Scholar] [CrossRef]
- Sun, W.J.; Zhou, W.F.; Jiao, J. Hydrogeological classification and water inrush accidents in China’s coal mines. Mine Water Environ. 2016, 35, 214–220. [Google Scholar] [CrossRef]
- Vutukuri, V.S.; Singh, R.N. Mine inundation-case histories. Mine Water Environ. 1995, 14, 107–130. [Google Scholar]
- Li, G.Y.; Zhou, W.F. Impact of karst water on coal mining in north China. Environ. Geol. 2006, 49, 449–457. [Google Scholar] [CrossRef]
- Ma, D.; Miao, X.X.; Bai, H.B.; Huang, J.H.; Pu, H.; Wu, Y.; Zhang, G.M.; Li, J.W. Effect of mining on shear sidewall groundwater inrush hazard caused by seepage instability of the penetrated karst collapse pillar. Nat. Hazards 2016, 82, 73–93. [Google Scholar] [CrossRef]
- Wu, Q.; Zhao, D.; Wang, Y.; Shen, J.; Mu, W.; Liu, H. Method for assessing coal-floor water-inrush risk based on the variable-weight model and unascertained measure theory. Hydrogeol. J. 2017, 25, 2089–2103. [Google Scholar] [CrossRef]
- Hiroyuki, M.; Takayuki, K. Hybrid continuation power flow with linear-nonlinear predictor. Power Syst. Technol. 2004, 1, 969–974. [Google Scholar]
- John, C.P. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Technical Report MSR-TR-98-14; Microsoft Research: Redmond, WA, USA, 1998. [Google Scholar]
- Fairhurst, C. Geo materials and recent development in micro-mechanical numerical models. News J. 1997, 4, 11–14. [Google Scholar]
- Bai, M.; Meng, F.; Elsworth, D.; Abousleiman, Y. Numerical modeling of coupled flow and deformation in fractured rock specimens. Int. J. Numer. Anal. Methods Geomech. 1999, 2, 141–160. [Google Scholar] [CrossRef]
- Hingley, P.; Nicolas, M. Methods for forecasting numbers of patent applications at the European patent office. World Pat. Inf. 2004, 26, 191–204. [Google Scholar] [CrossRef]
- Marquinez, T. Predictive GIS-based model of rock fall activity in Mountain Cliffs. Nat. Hazards 2003, 30, 341–360. [Google Scholar] [CrossRef]
- Wu, Q.; Liu, Y.; Liu, D.; Zhou, W. Prediction of floor water inrush: The application of GIS-based AHP vulnerable index method to Donghuantuo coal mine, China. Rock Mech. Rock Eng. 2011, 44, 591–600. [Google Scholar] [CrossRef]
- Abonyi, J.; Nagy, L.; Szeifert, F. Fuzzy model-based predictive control by instantaneous linearization. Fuzzy Sets Syst. 2001, 120, 109–122. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Yang, W.; Li, M.; Liu, X. Risk assessment of floor water inrush in coal mines based on secondary fuzzy comprehensive evaluation. Int. J. Rock Mech. Min. Sci. 2012, 52, 50–55. [Google Scholar] [CrossRef]
- Tawfiq, A.S.; Ibrahim, E.A. Artificial neural networks as applied to long-term demand forecasting. Artif. Intell. Eng. 1999, 13, 189–197. [Google Scholar]
- Taherdangkoo, R.; Taherdangkoo, M. Modified stem cells algorithm-based neural network applied to bottom hole circulating pressure in underbalanced drilling. Int. J. Pet. Eng. 2015, 1, 178–188. [Google Scholar] [CrossRef]
- Taherdangkoo, R.; Taherdangkoo, M. Application of hybrid neural particle swarm optimization algorithm to predict solubility of carbon dioxide in blended aqueous amine-based solvents. Int. J. Softw. Eng. Technol. Appl. 2015, 1, 290–307. [Google Scholar]
- Zhou, Q.; Herrera-Herbert, J.; Hidalgo, A. Predicting the Risk of Fault-Induced Water Inrush Using the Adaptive Neuro-Fuzzy Inference System. Minerals 2017, 7, 55. [Google Scholar] [CrossRef]
- Wu, Q.; Liu, Y.; Luo, L.; Liu, S.; Sun, W.; Zeng, Y. Quantitative evaluation and prediction of water inrush vulnerability from aquifers overlying coal seams in Donghuantuo Coal Mine, China. Environ. Earth Sci. 2015, 74, 1429–1437. [Google Scholar] [CrossRef]
- Taherdangkoo, M.; Taherdangkoo, R. Modified BNMR algorithm applied to Loney’s solenoid benchmark problem. Int. J. Appl. Electromagn. Mech. 2014, 46, 683–692. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Comes, C.; Vapnik, V. Support vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Ma, D.; Bai, H. Groundwater inflow prediction model of karst collapse pillar: A case study for mining-induced groundwater inrush risk. Nat. Hazards 2015, 76, 1319–1334. [Google Scholar] [CrossRef]
- Wang, Y.; Jin, D.; Zeng, Y. Primary analysis on nonlinear characteristics of water in rush system through the seam floor in kaprst mines. Carsol. Sin. 1998, 17, 331–341. [Google Scholar]
- Ma, D.; Cai, X.; Li, Q.; Duan, H. In-Situ and Numerical Investigation of Groundwater Inrush Hazard from Grouted Karst Collapse Pillar in Longwall Mining. Water 2018, 10, 1187. [Google Scholar] [CrossRef]
- Reibiec, M.S.; Kocevar, M.; Hoblaj, R. Hydrofracturing of rock as a method of water, mud, and gas inrush hazards in underground coal mining. In Proceedings of the 4th IMWA, Ljubljana, Slovenia, 25–30 September 1991; pp. 291–303. [Google Scholar]
- Ma, D.; Zhou, Z.L.; Wu, J.Y.; Li, Q.; Bai, H.B. Grain size distribution effect on the hydraulic properties of disintegrated coal mixtures. Energies 2017, 10, 612. [Google Scholar] [CrossRef]
- Zhou, Z.L.; Cai, X.; Ma, D.; Cao, W.Z.; Chen, L.; Zhou, J. Effects of water content on fracture and mechanical behavior of sandstone with a low clay mineral content. Eng. Fract. Mech. 2018, 193, 47–65. [Google Scholar] [CrossRef]
- Zhou, Z.L.; Cai, X.; Ma, D.; Chen, L.; Wang, S.F.; Tan, L.H. Dynamic tensile properties of sandstone subjected to wetting and drying cycles. Constr. Build. Mater. 2018, 182, 215–232. [Google Scholar] [CrossRef]
- Ma, D.; Bai, H.B.; Miao, X.X.; Pu, H.; Jiang, B.Y.; Chen, Z.Q. Compaction and seepage properties of crushed limestone particle mixture: An experimental investigation for Ordovician karst collapse pillar groundwater inrush. Environ. Earth Sci. 2016, 75, 11. [Google Scholar] [CrossRef]
- Bai, H.B.; Ma, D.; Chen, Z.Q. Mechanical behavior of groundwater seepage in karst collapse pillars. Eng. Geol. 2013, 164, 101–106. [Google Scholar] [CrossRef]
- Nello, C.; John, S.T. An Introduction to Support Vector Machine and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Vapnik, V.N.; Golowich, S.E.; Smola, A. Support vector method for function approximation, regression estimation, and signal processing. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1996. [Google Scholar]
- Widodo, A.; Yang, B.S.; Han, T. Combination of Independent Component Analysis and Support Vector Machines for Intelligent Faults Diagnosis of Induction Motors. Expert Syst. Appl. 2007, 32, 299–312. [Google Scholar] [CrossRef]
- Navia-Vazquez, A.; Parrado-Hernandez, E. Support vector machine interpretation. Neurocomputing 2006, 69, 1754–1759. [Google Scholar] [CrossRef]
- Canu, S.; Smola, A. Kernel methods and the exponential family. Neurocomputing 2006, 69, 714–720. [Google Scholar] [CrossRef] [Green Version]
- Lee, L.; Lin, Y.; Wahba, G. Multi Category Support Vector Machines; Technical Report 1040; Department of Statistics, University of Madison: Madison, WI, USA, 2001. [Google Scholar]
- Jin, D. Research status and outlook of water outburst from seam floor in China coalmines. Coal Sci. Technol. 2002, 30, 1–4. [Google Scholar]
- Barges, C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Lin, H.T.; Lin, C.J. A Study on Sigmoid Kernels for SVM and the Training of Non-PSD Kernels by SMO-Type Methods; Technical Report; Department of Computer Science and Information Engineering, National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Shylu, J.; Sikdar, S.; Swamy, P.K. Hybrid neural GA model to predict and minimize flatness value of hot rolled strips. J. Mater. Process. Technol. 2008, 195, 314–320. [Google Scholar]
- Taeshik, S.; Yongdae, K.; Cheolwon, L.; Jongsub, M. A machine learning framework for network anomaly detection using SVM and GA. In Proceedings of the Sixth Annual IEEE Systems, Man and Cybernetics (SMC) Information Assurance Workshop, West Point, NY, USA, 15–17 June 2005. [Google Scholar]
- Odintsev, V.N.; Miletenko, N.A. Water Inrush in Mines as a Consequence of Spontaneous Hydrofracture. J. Min. Sci. 2015, 51, 423–434. [Google Scholar] [CrossRef]
- Ma, D.; Cai, X.; Zhou, Z.L.; Li, X.B. Experimental investigation on hydraulic properties of granular sandstone and mudstone mixtures. Geofluids 2018. [Google Scholar] [CrossRef]
- Huang, Z.; Jiang, Z.; Tang, X.; Wu, X.; Guo, D.; Yue, Z. In-situ measurement of hydraulic properties of the fractured zone of coal mines. Rock Mech. Rock Eng. 2016, 49, 603–609. [Google Scholar] [CrossRef]
- Ma, D.; Rezania, M.; Yu, H.-S.; Bai, H.-B. Variations of hydraulic properties of granular sandstones during water inrush: Effect of small particle migration. Eng. Geol. 2017, 217, 61–70. [Google Scholar] [CrossRef] [Green Version]
- Chakraborti, N.; Kumar, B.S.; Babu, V.S.; Moitra, S.; Mukhopadhyay, A. Optimizing surface profiles during hot rolling: A genetic algorithms based multi-objective optimization. Comput. Mater. Sci. 2006, 37, 159–165. [Google Scholar] [CrossRef] [Green Version]
- Min, S.H.; Lee, J.; Han, I. Hybrid genetic algorithms and support vector machines for bankruptcy prediction. Expert Syst. Appl. 2006, 31, 652–660. [Google Scholar] [CrossRef]
- Yu, E.; Cho, S. GA-SVM wrapper approach for feature subset selection in keystroke dynamics identity verification. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; pp. 2253–2257. [Google Scholar]
Figure 1.
Influencing factors of water inrush from coal floor.

Figure 2.
Location of the selected water inrush cases in North China.

Figure 3.
Genetic algorithm (GA)-support vector machine (SVM) based prediction system.

Figure 4.
SVM prediction model.

Figure 5.
Framework of GA-SVM model.

Figure 6.
Classification precision–penalty parameter C relation.

Figure 7.
Predictive performance comparisons of the SVM and GA-SVM.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Influencing factors of water inrush cases.
| Case No. | Name of Working Face | Location | Limestone Aquifer Type | Hydraulic Pressure (MPa) | Thickness of Water-Resisting Strata (m) | Depth of Mining-Induced Failure Zone (m) | Fault Fall (m) |
|---|---|---|---|---|---|---|---|
| 1 | Mining area floor 33, Shiyi Mine | Huainan, Anhui | Thin | 2.00 | 30.0 | 12.9 | 1.5 |
| 2 | Working face 12031, Jiulishan Mine | Jiaozuo, Henan | Thin | 1.80 | 23.0 | 12.3 | 0.0 |
| 3 | Working face 9901, Taoyang Mine | Feicheng, Shandong | Thin | 0.60 | 17.0 | 8.6 | 8.0 |
| 4 | Working face 9204, Dafeng Mine | Feicheng, Shandong | Thin | 1.08 | 16.5 | 16.5 | 3.2 |
| 5 | Working face 9906, Taoyang Mine | Feicheng, Shandong | Thin | 1.42 | 25.7 | 15.2 | 0.0 |
| 6 | Working face 1007, Xia Zhuang Mine II | Zibo, Shandong | Thick | 5.19 | 55.9 | 17.0 | 7.0 |
| 7 | Working face 1441, Wangfeng Mine | Jiaozuo, Henan | Thin | 1.10 | 20.0 | 8.5 | 15.0 |
| 8 | Working face 2682, Fengfenger Mine | Handan, Hebei | Thin | 2.90 | 40.0 | 20.9 | 0.0 |
| 9 | Working face 31104, Xiezhuang Mine | Xinwen, Shandong | Thin | 1.30 | 30.0 | 18.3 | 4.9 |
| 10 | Working face 149, Longquan Mine | Zibo, Shandong | Thick | 4.06 | 65.9 | 16.0 | 10.0 |
| 11 | Working face 9903, Taoyang Mine | Feicheng, Shandong | Thin | 0.85 | 23.1 | 13.9 | 0.4 |
| 12 | Working face 617, Yang Zhuang Mine II | Huaibei, Anhui | Thin | 3.11 | 44.3 | 14.4 | 3.5 |
| 13 | Working face 1532, Fengfeng Mine I | Handan, Hebei | Thick | 2.30 | 7.3 | 7.3 | 0.0 |
| 14 | Working face 7505, Chuzhuang Mine | Feicheng, Shandong | Thin | 1.01 | 18.0 | 11.7 | 0.0 |
| 15 | Working face 2671, Fengfeng Mine II | Handan, Hebei | Thin | 2.80 | 40.0 | 15.0 | 6 |
| 16 | Working face 2131, Hanwang Mine | Jiaozuo, Henan | Thin | 1.10 | 16.0 | 8.0 | 0 |
| 17 | Working face 9206, Dafeng Mine | Huangbei, Anhui | Thin | 1.26 | 23.5 | 8.5 | 0 |
| 18 | Working faces 1301, Fengying Mine | Jiaozuo, Henan | Thin | 1.90 | 15.0 | 13.0 | 65 |
Table 2.
Definition of the aquifer and the maximum water inrush volume.
| Variable Name | Variable Type | Variable Value |
|---|---|---|
| Aquifer | Thin layer limestone | 1 |
| Thick layer limestone | 0 | |
| Maximum water inrush | (small water inrush) | 1000 |
| (medium water inrush) | 0100 | |
| (large water inrush) | 0010 | |
| (super-large water inrush) | 0001 |
Table 3.
Input information for water inrush cases.
| Case No. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Limestone aquifer type | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| Maximum water inrush (m3) | 1085 | 1620 | 1083 | 1628 | 420 | 4006 | 3060 | 865 | 1960 |
| Water inrush grade | 0100 | 0010 | 0100 | 0010 | 1000 | 0001 | 0001 | 0100 | 0010 |
| Case No. | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| Limestone aquifer type | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| Maximum water inrush (m3) | 1512 | 310 | 3153 | 4212 | 586.6 | 1310 | 900 | 436 | 5082 |
| Water inrush grade | 0010 | 1000 | 0001 | 0001 | 1000 | 0010 | 0100 | 1000 | 0001 |
Table 4.
Statistics of the parameter initial range.
| Kernel Type | Parameter | Minimum Value | Maximum Value | ||||
|---|---|---|---|---|---|---|---|
| kp | C | Error Rate | kp | C | Error Rate | ||
| Polynomial kernel | Valence number | 1 | 10−5 | 47% | 2 | 103 | 18% |
| Gaussian RBF kernel | Width | 25 | 2−1 | 36% | 215 | 231 | 6% |
Table 5.
Statistics of the SVM classifier parameter comparison.
| Kernel Function | kp | C | Training Precision | Test Accuracy | Support Vector Number | Proportion of Training Set |
|---|---|---|---|---|---|---|
| Polynomial kernel | 2 | 0.0008 | 96.3% | 95% | 20 | 20% |
| Gaussian RBF kernel | 213 | 223.5 | 96.5% | 96% | 26 | 26% |
Table 6.
Predictive values of SVM and GA-SVM.
| No. | Actual Water Inrush Volume | SVM Predictive Value | Prediction Error (%) | GA-SVM Predictive Value | Prediction Error (%) | Actual Level | SVM Prediction | GA-SVM Prediction |
|---|---|---|---|---|---|---|---|---|
| 16 | 900 | 864.8 | 3.91 | 887.1 | 1.43 | 0 | 0.00216 | 0.00039 |
| 0 | 0.00398 | 0.00073 | ||||||
| 1 | 0.9254 | 0.9671 | ||||||
| 0 | 0.00871 | 0.00021 | ||||||
| 17 | 436 | 479.3 | 9.93 | 413.4 | 5.18 | 0 | 0.0019 | 0.00085 |
| 1 | 0.9346 | 0.99763 | ||||||
| 0 | 0.0044 | 0.00068 | ||||||
| 0 | 0.0033 | 0.00033 | ||||||
| 18 | 5082 | 4144.5 | 18.45 | 4959.1 | 2.42 | 1 | 0.8974 | 0.99535 |
| 0 | 0.0068 | 0.00024 | ||||||
| 0 | 0.0052 | 0.00052 | ||||||
| 0 | 0.0015 | 0.00081 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ma, D.; Duan, H.; Cai, X.; Li, Z.; Li, Q.; Zhang, Q. A Global Optimization-Based Method for the Prediction of Water Inrush Hazard from Mining Floor. Water 2018, 10, 1618. https://doi.org/10.3390/w10111618
AMA Style
Ma D, Duan H, Cai X, Li Z, Li Q, Zhang Q. A Global Optimization-Based Method for the Prediction of Water Inrush Hazard from Mining Floor. Water. 2018; 10(11):1618. https://doi.org/10.3390/w10111618
Chicago/Turabian StyleMa, Dan, Hongyu Duan, Xin Cai, Zhenhua Li, Qiang Li, and Qi Zhang. 2018. "A Global Optimization-Based Method for the Prediction of Water Inrush Hazard from Mining Floor" Water 10, no. 11: 1618. https://doi.org/10.3390/w10111618
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.