





Abstract
Electronic health records (EHRs) are a rich source of information on human diseases, but the information is variably structured, fragmented, curated using different coding systems, and collected for purposes other than medical research. We describe an approach for developing, validating, and sharing reproducible phenotypes from national structured EHR in the United Kingdom with applications for translational research.
We implemented a rule-based phenotyping framework, with up to 6 approaches of validation. We applied our framework to a sample of 15 million individuals in a national EHR data source (population-based primary care, all ages) linked to hospitalization and death records in England. Data comprised continuous measurements (for example, blood pressure; medication information; coded diagnoses, symptoms, procedures, and referrals), recorded using 5 controlled clinical terminologies: (1) read (primary care, subset of SNOMED-CT [Systematized Nomenclature of Medicine Clinical Terms]), (2) International Classification of Diseases–Ninth Revision and Tenth Revision (secondary care diagnoses and cause of mortality), (3) Office of Population Censuses and Surveys Classification of Surgical Operations and Procedures, Fourth Revision (hospital surgical procedures), and (4) DM+D prescription codes.
Using the CALIBER phenotyping framework, we created algorithms for 51 diseases, syndromes, biomarkers, and lifestyle risk factors and provide up to 6 validation approaches. The EHR phenotypes are curated in the open-access CALIBER Portal (https://www.caliberresearch.org/portal) and have been used by 40 national and international research groups in 60 peer-reviewed publications.
We describe a UK EHR phenomics approach within the CALIBER EHR data platform with initial evidence of validity and use, as an important step toward international use of UK EHR data for health research.
INTRODUCTION
The UK National Health Service (NHS) offers international researchers opportunities to explore “cradle to grave” longitudinal electronic health record (EHR) phenotypes at scale. It is one of the few countries that combines a single-payer-and-provider comprehensive healthcare system, free at the point of care, with extensive national data resources across the entire population of 65 million. Patients are identified by a unique healthcare-specific identifier which enables linkage of patient data across EHR sources and the creation of longitudinal phenotypes that span primary and secondary care.1 Over 99% of people are registered with a general practitioner (GP) and structured primary care data collected electronically have been used by UK, U.S. and other researchers for decades.2 Furthermore, these national EHR data sources are being linked with large-scale consented genomic resources, for example, the 100 000 Genomes Project (also known as Genomics England)3 and UK Biobank,4–6 and enable the investigation of simple or complex traits across participant populations with diverse genetic backgrounds.7
The UK EHR landscape differs from the United States and elsewhere in important ways. Although the United Kingdom, unlike the United States, has the opportunity to establish a national approach, it faces the common challenge that EHR for primary care and hospital care are handled by different data providers and are kept separately, with independent access requirements.8,9 Significant progress has been made by U.S. initiatives such as Electronic Medical Records and Genomics (eMERGE),10 BioVU,11 Million Veteran Program,12 and All Of Us,13 and in Canada,14 Australia,15 Sweden,16 and Denmark.17 In the United Kingdom, however, there has been no recognized phenotyping framework or go-to resource for EHR researchers for systematically creating, curating and validating (rule-based or otherwise) EHR-derived phenotypes, obtaining information on controlled clinical terminologies, sharing algorithms, and communicating best approaches. Structured primary care EHR have been used in >1800 published studies,18 but only 5% of studies published sufficiently reproducible phenotypes,19 while significant heterogeneity exists (one review reported 66 asthma definitions).20 Current UK initiatives19,21,22 for curating EHR-derived phenotypes focus on lists of controlled clinical terminology terms (referred to as code lists) rather than self-contained phenotypes (terms, implementation, and validation evidence).
The scope of our research focuses on rule-based algorithms, as the majority of research studies (with some exceptions)23,24 using UK EHR utilize this approach for creating EHR-derived phenotypes.25 The main use case for CALIBER phenotypes and the approach presented in the manuscript is observational research (which is also the main stakeholder group of UK EHR): (1) high-resolution clinical epidemiology using national EHR examining disease etiology or prognosis, or (2) genetic epidemiology studies through the UK Biobank and Genomics England investigating simple and complex traits across populations. Our aspiration, however, is for CALIBER phenotypes to be adopted by the NHS in terms of computable knowledge which can be integrated in the healthcare system and used for interventional studies and clinical guidelines. Each of these use cases, however, has a different threshold on what is considered adequate performance, and we adopted a systematic and robust validation approach to quantify phenotype performance.
EHR phenotype validation is a critical process guiding their subsequent use in research or care.26,27 There are multiple sources of evidence or study designs that contribute to building confidence in the validity of an EHR phenotype for a particular purpose. Countries may also differ in the opportunities for validation: for example, in the United Kingdom, cross-referencing against multiple EHR sources, prognostic validation, and risk factor validation are all made possible by nationwide population-based records.28–32 In contrast with the United States, only recently have scalable methods been developed to access the entire hospital record for expert review,33 and text corpora are not available at scale.34 There have been few previous studies35 of the validity of International Classification of Disease and Health Related Problems–Tenth Revision (ICD-10) terms36 in the United Kingdom against hospital records because introduction of hospital EHRs is recent (for example, there are only 3 hospitals that have achieved stage 6 on the Healthcare Information and Management Systems Society Electronic Medical Record Adoption Model.37
We have developed the CALIBER EHR platform for the United Kingdom by adopting and extending best practices from leading initiatives and consortia (for example, eMERGE, Million Veteran Program, BioVU) with regards to creating, evaluating, and disseminating EHR-derived phenotypes for research. Specifically, these practices, which were previously not systematically followed in the UK EHR community before CALIBER include (1) establishing a robust and iterative phenotype creation process involving multiple scientific disciplines, (2) systematically curating EHR-derived phenotypes, (3) using methods for enhancing reproducibility, and (4) undertaking and reporting robust phenotype validation analyses. Here, we define a framework for enabling EHR phenotyping in a scalable and reproducible manner. Algorithm reproducibility was defined similarly to Goodman’s “methodology reproducibility,”38 that is, providing a systematic and precise description of the algorithm components, logic, implementation, and evidence of validity that would enable national or international independent researchers to create, apply, and evaluate CALIBER phenotyping algorithms in local similar data sources. We present a systematic validation framework for assessing accuracy consisting of up to 6 approaches of evidence (expert review to prognostic validation) and disseminating through a centralized open-access repository. We have chosen heart failure (HF), acute myocardial infarction (AMI), and bleeding as examples of medical conditions that exemplify the strengths of national linked UK EHR and the nontrivial challenges researchers encounter.
MATERIALS AND METHODS
We developed an iterative and collaborative approach for creating and validating rule-based EHR phenotyping algorithms using UK structured EHR. The approach involved expert review interwoven with data exploration and analysis. An EHR phenotyping algorithm translates the clinical requirements for a particular patient to be considered a case into queries that leverage EHR sources stored in a relational database and extracts disease onset, severity, and subtype information. In the following sections we describe the platform, the algorithm development process, and validation consisting of 6 approaches of evidence.
UK primary care EHR, hospital billing data, and cause-specific mortality in the CALIBER platform
The CALIBER platform39 is currently built around 4 national EHR data sources (Figure 1) deterministically linked using NHS number (unique 10-digit identifier assigned at birth or first interaction), gender, postcode, and date of birth; 96% of patients with a valid NHS number successfully linked.40
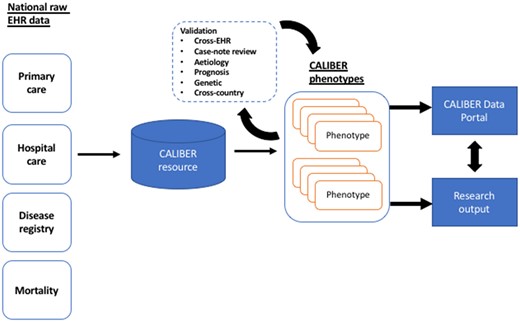
The CALIBER platform (https://www.caliberresearch.org) links national structured electronic health records (EHRs) across primary care, secondary care, and mortality for research. EHR-derived phenotypes are created using an iterative methodology and 6 independent approaches of evidence are generated to assess algorithm accuracy. More than 50 phenotypes are published in an open-access resource, the CALIBER Portal (https://www.caliberresearch.org/portal), and are used in >60 publications.
The baseline cohort is composed of a national primary care EHR database, the Clinical Practice Research Datalink (CPRD).41 Primary care has used computerized health records since 2000 and general practices use one of several EHR systems. CPRD contains longitudinal primary care data (extracted from the Vision and Egton Medical Information Systems clinical information systems) on diagnoses, symptoms, drug prescriptions, vaccinations, blood tests, and risk factors irrespective of disease status and hospitalization. The CPRD uses Read42 terms (112 806 terms; subset of the International Health Terminology Standards Development Organization SNOMED-CT [Systematized Nomenclature of Medicine Clinical Terms])42 to record information. Prescriptions are recorded using Gemscript (a commercial derivative of the NHS Dictionary of Medicines and Devices [dm+d])43 (72 664 entries). The CPRD contains >10 billion rows of data from >15 million patients (from all the contributing primary care practices, irrespective of consent to linkage) shown to be representative in terms of age, sex, mortality, and ethnicity44–46 and of high validity.47
Hospital Episode Statistics (HES) (https://digital.nhs.uk/)48 contains administrative data on diagnoses and procedures generated during hospital interactions. Diagnoses are recorded using the ICD-10 and procedures using the Office of Population Censuses and Surveys Classification of Surgical Operations and Procedures, Fourth Revision (10 713 terms, similar to Current Procedural Terminology).49 Up to 20 primary and secondary discharge diagnoses are recorded per finished consultant episode. The Myocardial Ischaemia National Audit Project (MINAP) is a national disease and quality improvement registry capturing all acute coronary syndrome events across England. MINAP contains diagnostic, severity and treatment information using 120 structured data fields.50 The Office for National Statistics (ONS) contains socioeconomic deprivation using the Index of Multiple Deprivation51 and physician-certified cause-specific mortality (underlying and up to 14 secondary causes using International Classification of Diseases–Ninth Revision [ICD-9] or ICD-10).
Data quality
Primary care
Our analyses incorporated primary care EHR data quality metrics across 2 dimensions: at the patient level and at the primary care practice level.41
Patient-level data quality
In line with previous research using UK primary care EHRs from the CPRD and CPRD guidance, we only utilized patients which were marked as “acceptable for research” by the CPRD. Patients are labeled as acceptable through an algorithmic process that identified and excludes patients with noncontinuous follow-up and patients with poor data according to a predefined list of data quality metrics (for example, empty date of first registration, first registration before date of birth, invalid gender, missing or incorrect dates across all recorded healthcare episodes). We additionally excluded records in which the date was invalid or malformed or in the future occurring after the last date of data collection.
Practice level
The overall quality of the data recorded in a primary care practice is algorithmically marked by an “up to standard (UTS)” date by the CPRD. The UTS date is deemed as the date at which data in the practice are considered to have continuous high-quality data fit for use in research. The algorithm used to derive this date is based on 2 concepts: (1) gap analysis (assurance of continuity in data recording and establishing if any unexpected and prolonged gaps in recording exist) and (2) death recording (observing the expected and actual deaths recorded at a practice over time by taking into account season and geographical variation in death rates and establishing if any gaps in recording exist). In both of these cases, the UTS date is set to the latest of these dates.
Completeness patterns of key clinical covariates such as risk factors (for example, smoking status, blood pressure, body mass index) has been previously shown to have rapidly increased after the introduction of a financial incentives framework (Quality and Outcomes Framework) that encourages GPs to record key data items.41
Secondary care
The HES Admitted Patient Care data are collected for all admissions to all NHS secondary healthcare providers. The NHS funds 98%-99% of hospital activity in England. HES Admitted Patient Care data are administrative data collected for reimbursement of hospital activity and are postdischarge derived by clinical coders according to standardized rules for translating information from discharge summaries into diagnosis (ICD-10) and surgical procedure terms (Office of Population Censuses and Surveys Classification of Surgical Operations and Procedures, Fourth Revision) terms.48 The overarching reimbursement framework, Payment-By-Results (a fixed-tariff case mix–based payment system)52 provides financial incentives for hospitals to improve their coding accuracy and depth and ensure accurate reimbursement. This has led to an increase in the number of diagnosis terms recorded and coding accuracy (primary diagnoses accuracy was 96% [interquartile range, 89.3%-96.3%]) when compared with expert review of case notes.53 The NHS Digital Data Quality Maturity Index provides a per hospital overall score for clinical data quality in term of data field and hospitalization episode completeness on a quarterly basis.54
Algorithm development
The development pipeline was a collaborative and iterative process involving researchers from a diverse set of scientific backgrounds (for example, clinicians, epidemiologists, computer scientists, public health researchers, statisticians). An iteration refers to an adjustment in the computational strategy to derive the phenotype in question, based on data-driven examinations of its internal validity and according to the clinical context. The number of development iterations was proportionate with the complexity of the clinical phenotype: algorithms leveraging multiple sources required multiple iterations and substantially more clinician input.
We initially defined search strategies for identifying relevant diagnosis terms and their synonyms which were selected based on input from clinicians, existing literature, national guidelines and by consulting medical vocabulary repositories (for example, Unified Medical Language System Metathesaurus.)55,56 Two clinicians independently classified identified terminology terms (disagreements resolved by third) into nonoverlapping categories: (1) prevalent (for example, “history of heart failure”), (2) possible (for example, “congestive heart failure monitoring”), and (3) incident (potentially subclassified [for example, “chronic congestive heart failure,” “acute left ventricular failure,” “heart failure not otherwise specified”]). Similarly, we identified and classified coded symptoms recorded in primary care EHR. Many CALIBER phenotyping algorithms combine coded diagnosis, symptom information, continuous measurements (for example, laboratory values or other physiological measurements), and medication prescription information in a rule-based fashion (for example, hypertension is defined using continuous blood pressure, coded diagnoses, blood pressure–lowering prescriptions, and comorbidities). We generated ad hoc rules to reconcile (1) coding differences across EHR sources with respect to the granularity of diagnosis, (2) the presence of multiple terms (for example, multiple different ethnicity entries, and (3) transience in coding (for example, ICD-9 was used for recording the cause of death before 2000). In primary care EHR, identified Read terms were evaluated in terms of their information content and subsequent ability to ascertain a phenotype reliably.
Primary care EHRs contain over 450 structured data items for recording continuous measurements (for example, blood markers). For continuous phenotypes (for example, blood pressure), we normalized data quality by identifying the relevant units, specified unit conversions (where required), and defined valid value ranges. For example, the neutrophil count structured data area contained both the absolute values and percentages, and these had to be differentiated by supplementary Read terms and by checking the distribution of values by unit. Sometimes values were obviously on the wrong scale (for example, hemoglobin) in which some values were distributed as if measured in grams per liter but had (presumably incorrect) units recorded as grams per deciliter. Zero values caused particular problems; they could be impossible and represent missing data in some cases (for example, ferritin) but might be true zeroes representing undetectable values in other cases (eg, basophils). Careful investigation by units and Read term was required to avoid creating Missing Not at Random data (if the zeroes were true) or false data (if the zeroes were false). Definition of valid ranges for values was also problematic, as we wanted to exclude erroneous values without excluding true physiologically extreme values.
Validation: systematic evaluation using 6 approaches
Obtaining and curating evidence of phenotype validity is an essential component of the phenotyping process. We evaluated EHR-derived phenotypes across up to 6 different approaches of providing of evidence of phenotype validity, acknowledging that that the use case will inform which validation(s) are most important. For example, phenotyping algorithms developed for disease epidemiology (for example, screening or disease surveillance) might be designed for higher sensitivity whereas those used in genetic association studies might be designed to maximize positive predictive value (PPV). We provide details of these validation approaches in the following sections.
Cross-EHR source concordance
For EHR-derived cases of AMI, HF, and bleeding, we quantified the percentage of cases identified in each source, quantified the overlap between sources, and evaluated per-source completeness and diagnostic validity. Additionally, we used a disease registry (MINAP) as a reference to derive the PPV of AMI diagnoses recorded in hospital EHR (HES), that is, the probability that an AMI diagnosis recorded in HES was indeed an AMI as ascertained by MINAP (that contains information on AMI ascertainment such as electrocardiogram results and troponin measurements) rather than unstable angina or a noncardiac diagnosis. We did not calculate sensitivity and specificity relative to MINAP given that MINAP does not include all cases of AMI, as it is a disease registry that requires bespoke data entry by audit staff separate from clinical care or coding. It is therefore not possible to use MINAP as a gold standard to evaluate hospital EHR (HES) in relation to completeness of detection of AMI (sensitivity) or non-MI (specificity). However, there is a concern that HES data may be inaccurate, and MINAP can be used to evaluate its PPV for the subset of cases with a MINAP record for the event, in which the exact diagnosis in MINAP can be considered a “gold standard.”
Case note review
We evaluated the performance of the secondary care component of the bleeding phenotype by assessing the ability of the diagnosis terms (ICD-10) utilized by the phenotype to correctly identify hospitalized bleeding events in 2 independent hospital EHR sources. Two clinicians (blinded to the ICD-10 diagnosis terms) reviewed the entire hospital record (charts, referral letters, discharge letters, imaging reports) for 283 completed patient hospital episodes across 2 large hospitals (University College London Hospitals, King's College Hospital). Bleeding assignments from the clinicians review was compared with those from the phenotyping algorithm and we estimated the PPV, negative predictive value (NPV), sensitivity, and specificity using the case review data as the “gold standard.” We extracted hospital data (14 364 947 words) using CogStack57 from the consented SIGNUM (Stroke InvestiGation Network-Understanding Mechanisms) study.
Consistency of risk factor–disease associations from non-EHR studies
For all exemplars, we produced and reported hazard ratios (HRs) and 95% confidence intervals (CIs) of known risk factors from Cox proportional hazards models adjusted for age, sex, and other covariates. We evaluated the ability of obtaining consistent estimates (in terms of direction and magnitude) with risk factor associations derived from non-EHR research-driven studies.
Consistency with prior prognosis research
We produced Kaplan–Meier cumulative incidence curves at appropriate time intervals and endpoints and stratified by EHR source. We evaluated the observed prognostic profiles with previously reported evidence for example observing different survival patterns between patients diagnosed with HF in CPRD but never hospitalized compared with patients diagnosed in HES.
Consistency of genetic associations
Similar to previous studies, we attempted to replicate previously reported associations between genetic variants and diseases discovered from non-EHR studies (for example, research-driven observational cohort studies or interventional studies). The ability of EHR-derived phenotypes to replicate previously discovered associations derived from non-EHR studies and observing similar direction and magnitude of association reinforces the evidence toward the overall validity of the EHR phenotype.58 Using PLINK,59 we extracted genetic variants associated with AMI reaching genome-wide significance (P < 5 × 10−8) from publicly available 1000 Genomes–based genome-wide association study summary data (“CARDIoGRAMplusC4D - mi.additive.Oct2015”) in the CARDIoGRAMplusC4D60 consortium. In the UK Biobank, we identified AMI cases in linked hospital and mortality EHR using the CALIBER AMI phenotype and defined controls as noncase participants with no self-reported record of AMI at baseline. We estimated the association of genetic variants and AMI using logistic regression with an underlying additive model in PLINK adjusting for the first 10 principal components, age and sex. Replication was defined as the single nucleotide polymorphism being associated with AMI in the UK Biobank (Bonferroni-adjusted P < .0016) with a concordant direction of effect with CARDIOGRAMPlusC4D.
External populations
We assessed the validity of developed algorithms by implementing them in external data sources (UK or elsewhere) and examining consistency of results in the evaluation criteria.
Phenotype dissemination
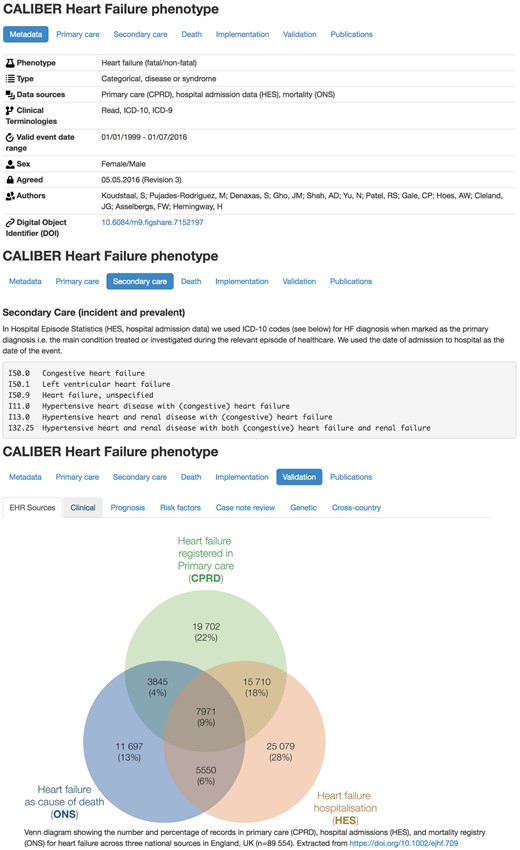
We generated textual descriptions of algorithms with explicit detail on the logic behind the algorithm (preprocessing, cross-source reconciliation, quality checks) in a clinician-friendly manner. We generated flowchart representations accompanied by pseudocode for facilitating the translation of the algorithm to Structured Query Language (SQL) queries. We created entries in the CALIBER Portal (Figure 2) describing implementation details across sources, research outputs, validation evidence and a Digital Object Identifier.61 We created an open-source R library for manipulating clinical terminologies (http://caliberanalysis.r-forge.r-project.org/) using a custom file format including metadata (for example, naming, version, authors, timestamp).
CALIBER Portal entry for the heart failure phenotype (available at https://www.caliberresearch.org/portal/phenotypes/heartfailure). Each entry in the Portal contains implementation details on the logic and the terms from controlled clinical terminologies associated with the phenotyping algorithm. Additionally, the 6 approaches of validation evidence are presented and the research output that has used the phenotype is provided.
Ethical approval
The CPRD has broad ethical approval for purely observational research using pseudonymized linked primary or secondary care data for supporting medical purposes that are in the interests of patients and the wider public. Linkages were performed by NHS Digital, the statutory body in England responsible for providing core healthcare information technology and curating many of the national datasets. This study was approved by the Medicines and Healthcare Products Regulatory Agency Independent Scientific Advisory Committee (protocol references: 11_088, 12_153R, 16_221, 18_029R2, 18_159R).
RESULTS
Using the CALIBER EHR phenotyping approach described here, we curated over 90 000 terms from 5 controlled clinical terminologies to create 51 validated phenotyping algorithms (35 diseases or syndromes, 10 biomarkers, 6 lifestyle risk factors). In this manuscript, we used 3 exemplar phenotypes: HF (https://www.caliberresearch.org/portal/phenotypes/heartfailure), bleeding (https://www.caliberresearch.org/portal/phenotypes/bleeding), and AMI (https://www.caliberresearch.org/portal/phenotypes/acutemyocardialinfarction). Table 1 provides a complete list of published, peer-reviewed phenotypes and the approaches of evidence supporting their validity. CALIBER phenotypes have been used by 40 national and international research groups in 60 peer-reviewed publications.62 The CALIBER Portal (http://www.caliberresearch.org/portal) opened in October 2018 to the community and provides a centralized resource for curating EHR-derived phenotypes.
Overview of published, peer-reviewed EHR phenotypes derived from the CALIBER platform and the approaches of validation evidence - More information available on the CALIBER Portal https://www.caliberresearch.org/portal/phenotypes
| Phenotype | EHR data source | Validation evidence | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Primary care | Secondary care | Death | Cross-source | Case-note review | Prognosis | Etiology | Genetic | Cross-country | |
| Disease or syndrome | |||||||||
| AAA | ● | ● | ● | ● | ● | ● | |||
| AMI | ● | ● | ● | ● | ● | ● | ● | ● | |
| AD | ● | ● | ● | ● | ● | ||||
| AF | ● | ● | ● | ● | ● | ● | ● | ||
| Uveitis | ● | ● | ● | ||||||
| Bleeding | ● | ● | ● | ● | ● | ● | ● | ● | |
| Bullous disorder | ● | ● | ● | ● | |||||
| CHD | ● | ● | ● | ● | ● | ||||
| Depression | ● | ● | ● | ● | |||||
| Diabetes | ● | ● | ● | ● | |||||
| Giant cell arteritis | ● | ● | ● | ● | |||||
| HF | ● | ● | ● | ● | ● | ● | |||
| HIV | ● | ● | ● | ● | ● | ||||
| Hypertension | ● | ● | ● | ● | ● | ||||
| HCM | ● | ● | ● | ● | |||||
| Influenza | ● | ● | |||||||
| MS | ● | ● | ● | ● | |||||
| PAD | ● | ● | ● | ● | ● | ● | |||
| Polymyalgia | ● | ● | ● | ● | |||||
| PBC | ● | ● | ● | ● | |||||
| Psoriasis | ● | ● | ● | ● | |||||
| Dementia NOS | ● | ● | ● | ● | ● | ||||
| RA | ● | ● | ● | ● | |||||
| SA | ● | ● | ● | ● | ● | ||||
| Intracerebral hemorrhage | ● | ● | ● | ● | ● | ● | |||
| Ischemic stroke | ● | ● | ● | ● | ● | ● | |||
| SAH | ● | ● | ● | ● | ● | ● | |||
| Stroke NOS | ● | ● | ● | ● | ● | ● | |||
| SCD | ● | ● | ● | ● | ● | ● | |||
| Systemic sclerosis | ● | ● | ● | ● | |||||
| TIA | ● | ● | ● | ● | ● | ● | |||
| UCD | ● | ● | ● | ● | ● | ||||
| UA | ● | ● | ● | ● | ● | ||||
| Vascular dementia | ● | ● | ● | ● | ● | ||||
| Obesity | ● | ● | ● | ● | |||||
| Biomarkers | |||||||||
| Blood pressure | ● | ● | |||||||
| Eosinophils | ● | ● | |||||||
| Heart rate | ● | ● | |||||||
| Lymphocytes | ● | ● | |||||||
| Neutrophils | ● | ● | |||||||
| White blood cells | ● | ● | ● | ||||||
| LDL cholesterol | ● | ● | |||||||
| HDL cholesterol | ● | ● | |||||||
| Triglycerides | ● | ● | |||||||
| BMI | ● | ● | ● | ||||||
| Lifestyle risk factors and other | |||||||||
| Alcohol | ● | ● | |||||||
| Ethnicity | ● | ● | ● | ||||||
| Pregnancy | ● | ● | ● | ||||||
| Sex | ● | ● | |||||||
| Smoking | ● | ● | |||||||
| Deprivation | ● | ● | |||||||
| Phenotype | EHR data source | Validation evidence | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Primary care | Secondary care | Death | Cross-source | Case-note review | Prognosis | Etiology | Genetic | Cross-country | |
| Disease or syndrome | |||||||||
| AAA | ● | ● | ● | ● | ● | ● | |||
| AMI | ● | ● | ● | ● | ● | ● | ● | ● | |
| AD | ● | ● | ● | ● | ● | ||||
| AF | ● | ● | ● | ● | ● | ● | ● | ||
| Uveitis | ● | ● | ● | ||||||
| Bleeding | ● | ● | ● | ● | ● | ● | ● | ● | |
| Bullous disorder | ● | ● | ● | ● | |||||
| CHD | ● | ● | ● | ● | ● | ||||
| Depression | ● | ● | ● | ● | |||||
| Diabetes | ● | ● | ● | ● | |||||
| Giant cell arteritis | ● | ● | ● | ● | |||||
| HF | ● | ● | ● | ● | ● | ● | |||
| HIV | ● | ● | ● | ● | ● | ||||
| Hypertension | ● | ● | ● | ● | ● | ||||
| HCM | ● | ● | ● | ● | |||||
| Influenza | ● | ● | |||||||
| MS | ● | ● | ● | ● | |||||
| PAD | ● | ● | ● | ● | ● | ● | |||
| Polymyalgia | ● | ● | ● | ● | |||||
| PBC | ● | ● | ● | ● | |||||
| Psoriasis | ● | ● | ● | ● | |||||
| Dementia NOS | ● | ● | ● | ● | ● | ||||
| RA | ● | ● | ● | ● | |||||
| SA | ● | ● | ● | ● | ● | ||||
| Intracerebral hemorrhage | ● | ● | ● | ● | ● | ● | |||
| Ischemic stroke | ● | ● | ● | ● | ● | ● | |||
| SAH | ● | ● | ● | ● | ● | ● | |||
| Stroke NOS | ● | ● | ● | ● | ● | ● | |||
| SCD | ● | ● | ● | ● | ● | ● | |||
| Systemic sclerosis | ● | ● | ● | ● | |||||
| TIA | ● | ● | ● | ● | ● | ● | |||
| UCD | ● | ● | ● | ● | ● | ||||
| UA | ● | ● | ● | ● | ● | ||||
| Vascular dementia | ● | ● | ● | ● | ● | ||||
| Obesity | ● | ● | ● | ● | |||||
| Biomarkers | |||||||||
| Blood pressure | ● | ● | |||||||
| Eosinophils | ● | ● | |||||||
| Heart rate | ● | ● | |||||||
| Lymphocytes | ● | ● | |||||||
| Neutrophils | ● | ● | |||||||
| White blood cells | ● | ● | ● | ||||||
| LDL cholesterol | ● | ● | |||||||
| HDL cholesterol | ● | ● | |||||||
| Triglycerides | ● | ● | |||||||
| BMI | ● | ● | ● | ||||||
| Lifestyle risk factors and other | |||||||||
| Alcohol | ● | ● | |||||||
| Ethnicity | ● | ● | ● | ||||||
| Pregnancy | ● | ● | ● | ||||||
| Sex | ● | ● | |||||||
| Smoking | ● | ● | |||||||
| Deprivation | ● | ● | |||||||
AAA: abdominal aortic aneurysm; AD: Alzheimer’s disease; AF: atrial fibrillation; AMI: acute myocardial infarction; BMI: body mass index; CHD: coronary heart disease; EHR: electronic health record; HCM: hypertrophic cardiomyopathy; HDL: high-density lipoprotein; HF: heart failure; HIV: human immunodeficiency virus; LDL: low-density lipoprotein; MS: multiple sclerosis; NOS: not otherwise specified; PAD: peripheral arterial disease; PBC: primary biliary cirrhosis; RA: rheumatoid arthritis; SA: stable angina; SAH: subarachnoid hemorrhage; SCD: sudden cardiac death; TIA: transient ischemic attack; UA: unstable angina; UCD: unheralded coronary death.
Overview of published, peer-reviewed EHR phenotypes derived from the CALIBER platform and the approaches of validation evidence - More information available on the CALIBER Portal https://www.caliberresearch.org/portal/phenotypes
| Phenotype | EHR data source | Validation evidence | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Primary care | Secondary care | Death | Cross-source | Case-note review | Prognosis | Etiology | Genetic | Cross-country | |
| Disease or syndrome | |||||||||
| AAA | ● | ● | ● | ● | ● | ● | |||
| AMI | ● | ● | ● | ● | ● | ● | ● | ● | |
| AD | ● | ● | ● | ● | ● | ||||
| AF | ● | ● | ● | ● | ● | ● | ● | ||
| Uveitis | ● | ● | ● | ||||||
| Bleeding | ● | ● | ● | ● | ● | ● | ● | ● | |
| Bullous disorder | ● | ● | ● | ● | |||||
| CHD | ● | ● | ● | ● | ● | ||||
| Depression | ● | ● | ● | ● | |||||
| Diabetes | ● | ● | ● | ● | |||||
| Giant cell arteritis | ● | ● | ● | ● | |||||
| HF | ● | ● | ● | ● | ● | ● | |||
| HIV | ● | ● | ● | ● | ● | ||||
| Hypertension | ● | ● | ● | ● | ● | ||||
| HCM | ● | ● | ● | ● | |||||
| Influenza | ● | ● | |||||||
| MS | ● | ● | ● | ● | |||||
| PAD | ● | ● | ● | ● | ● | ● | |||
| Polymyalgia | ● | ● | ● | ● | |||||
| PBC | ● | ● | ● | ● | |||||
| Psoriasis | ● | ● | ● | ● | |||||
| Dementia NOS | ● | ● | ● | ● | ● | ||||
| RA | ● | ● | ● | ● | |||||
| SA | ● | ● | ● | ● | ● | ||||
| Intracerebral hemorrhage | ● | ● | ● | ● | ● | ● | |||
| Ischemic stroke | ● | ● | ● | ● | ● | ● | |||
| SAH | ● | ● | ● | ● | ● | ● | |||
| Stroke NOS | ● | ● | ● | ● | ● | ● | |||
| SCD | ● | ● | ● | ● | ● | ● | |||
| Systemic sclerosis | ● | ● | ● | ● | |||||
| TIA | ● | ● | ● | ● | ● | ● | |||
| UCD | ● | ● | ● | ● | ● | ||||
| UA | ● | ● | ● | ● | ● | ||||
| Vascular dementia | ● | ● | ● | ● | ● | ||||
| Obesity | ● | ● | ● | ● | |||||
| Biomarkers | |||||||||
| Blood pressure | ● | ● | |||||||
| Eosinophils | ● | ● | |||||||
| Heart rate | ● | ● | |||||||
| Lymphocytes | ● | ● | |||||||
| Neutrophils | ● | ● | |||||||
| White blood cells | ● | ● | ● | ||||||
| LDL cholesterol | ● | ● | |||||||
| HDL cholesterol | ● | ● | |||||||
| Triglycerides | ● | ● | |||||||
| BMI | ● | ● | ● | ||||||
| Lifestyle risk factors and other | |||||||||
| Alcohol | ● | ● | |||||||
| Ethnicity | ● | ● | ● | ||||||
| Pregnancy | ● | ● | ● | ||||||
| Sex | ● | ● | |||||||
| Smoking | ● | ● | |||||||
| Deprivation | ● | ● | |||||||
| Phenotype | EHR data source | Validation evidence | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Primary care | Secondary care | Death | Cross-source | Case-note review | Prognosis | Etiology | Genetic | Cross-country | |
| Disease or syndrome | |||||||||
| AAA | ● | ● | ● | ● | ● | ● | |||
| AMI | ● | ● | ● | ● | ● | ● | ● | ● | |
| AD | ● | ● | ● | ● | ● | ||||
| AF | ● | ● | ● | ● | ● | ● | ● | ||
| Uveitis | ● | ● | ● | ||||||
| Bleeding | ● | ● | ● | ● | ● | ● | ● | ● | |
| Bullous disorder | ● | ● | ● | ● | |||||
| CHD | ● | ● | ● | ● | ● | ||||
| Depression | ● | ● | ● | ● | |||||
| Diabetes | ● | ● | ● | ● | |||||
| Giant cell arteritis | ● | ● | ● | ● | |||||
| HF | ● | ● | ● | ● | ● | ● | |||
| HIV | ● | ● | ● | ● | ● | ||||
| Hypertension | ● | ● | ● | ● | ● | ||||
| HCM | ● | ● | ● | ● | |||||
| Influenza | ● | ● | |||||||
| MS | ● | ● | ● | ● | |||||
| PAD | ● | ● | ● | ● | ● | ● | |||
| Polymyalgia | ● | ● | ● | ● | |||||
| PBC | ● | ● | ● | ● | |||||
| Psoriasis | ● | ● | ● | ● | |||||
| Dementia NOS | ● | ● | ● | ● | ● | ||||
| RA | ● | ● | ● | ● | |||||
| SA | ● | ● | ● | ● | ● | ||||
| Intracerebral hemorrhage | ● | ● | ● | ● | ● | ● | |||
| Ischemic stroke | ● | ● | ● | ● | ● | ● | |||
| SAH | ● | ● | ● | ● | ● | ● | |||
| Stroke NOS | ● | ● | ● | ● | ● | ● | |||
| SCD | ● | ● | ● | ● | ● | ● | |||
| Systemic sclerosis | ● | ● | ● | ● | |||||
| TIA | ● | ● | ● | ● | ● | ● | |||
| UCD | ● | ● | ● | ● | ● | ||||
| UA | ● | ● | ● | ● | ● | ||||
| Vascular dementia | ● | ● | ● | ● | ● | ||||
| Obesity | ● | ● | ● | ● | |||||
| Biomarkers | |||||||||
| Blood pressure | ● | ● | |||||||
| Eosinophils | ● | ● | |||||||
| Heart rate | ● | ● | |||||||
| Lymphocytes | ● | ● | |||||||
| Neutrophils | ● | ● | |||||||
| White blood cells | ● | ● | ● | ||||||
| LDL cholesterol | ● | ● | |||||||
| HDL cholesterol | ● | ● | |||||||
| Triglycerides | ● | ● | |||||||
| BMI | ● | ● | ● | ||||||
| Lifestyle risk factors and other | |||||||||
| Alcohol | ● | ● | |||||||
| Ethnicity | ● | ● | ● | ||||||
| Pregnancy | ● | ● | ● | ||||||
| Sex | ● | ● | |||||||
| Smoking | ● | ● | |||||||
| Deprivation | ● | ● | |||||||
AAA: abdominal aortic aneurysm; AD: Alzheimer’s disease; AF: atrial fibrillation; AMI: acute myocardial infarction; BMI: body mass index; CHD: coronary heart disease; EHR: electronic health record; HCM: hypertrophic cardiomyopathy; HDL: high-density lipoprotein; HF: heart failure; HIV: human immunodeficiency virus; LDL: low-density lipoprotein; MS: multiple sclerosis; NOS: not otherwise specified; PAD: peripheral arterial disease; PBC: primary biliary cirrhosis; RA: rheumatoid arthritis; SA: stable angina; SAH: subarachnoid hemorrhage; SCD: sudden cardiac death; TIA: transient ischemic attack; UA: unstable angina; UCD: unheralded coronary death.
Cross-EHR source concordance
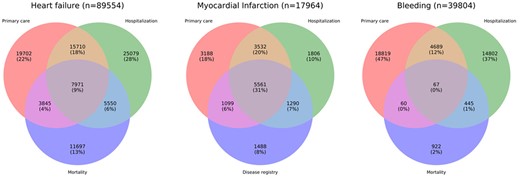
The PPV of AMI (the probability that the diagnosis recorded in MINAP was AMI rather than unstable angina or a noncardiac diagnosis) was 92.2% (6660 of 7224; 95% CI, 91.6%-92.8%) in CPRD and 91.5% (6851 of 7489; 95% CI, 90.8%-92.1%) in HES (Figure 3). Among the 17 964 patients with at least 1 record of nonfatal AMI, 13 380 (74.5%) were recorded by CPRD, 12 189 (67.9%) by HES, and 9438 (52.5%) by MINAP. Overall, 5561 (31.0%) of patients had AMI recorded in 3 sources (32.0% within 90 days), with 11 482 (63.9%) in at least 2 sources. For 89 554 HF cases, 26% were recorded in CPRD only, 27% in both CPRD and HES, and 34% in HES only, and 13% had HF as cause of death without a previous record elsewhere. In 39 804 bleeding cases, 59.4% were captured in CPRD and 50.2% in HES, with 3.8% events in ONS. Allowing a 30 day window, only 13.2% of events were captured in 2 or more sources. Similarly, a very small proportion (13.2%) of bleeding cases identified were captured in multiple data sources.
![Assessing the recording and concordance of 3 electronic health record (EHR)–derived phenotypes (heart failure, nonfatal acute myocardial infarction [AMI], and bleeding) across 3 EHR data sources: primary care (Clinical Practice Research Datalink [CPRD]), hospital care (Hospital Episode Statistics [HES]), and mortality (Office for National Statistics [ONS]) or disease registry data (Myocardial Ischaemia National Audit Project [MINAP]). Only a very small proportion (9% for heart failure, 31% for AMI, and <1% for bleeding) of cases are identified concurrently by all 3 data sources. ICD-10: International Classification of Diseases–Tenth Revision.](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/jamia/26/12/10.1093_jamia_ocz105/3/m_ocz105f3.jpeg?Expires=1716330688&Signature=UYRNHLjfEZll4x2SYkqjm56DSas2gIjJebkcl6Qw2g12uodTIublrSAxkFc~xZfA~ACYr97VRGa-K72-X0BavR3p3tr8o~3vH4PP68koLCc1t-rkYDmyB2~3qI7AAniEr8h4w-nYHOzO2kZcJOlYGIlT88ZyUJ~V5M4x1ezThn43tndkq7sK8iiuU1tvIb0LuMTWuJmeSWzlBSAzI~3~~6D7GWn3Eu-Z2pKjvNhzwWYCrqoY6EXo-h-hERED-hyKuQexGrkbW7XqdSqpiHr5eTd2FBdI26bMD3e2ghAjV5zN9pPEkLjCVjowTfNRC~tdFo5DC-3DimugQEE33-bV2w__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA)
Assessing the recording and concordance of 3 electronic health record (EHR)–derived phenotypes (heart failure, nonfatal acute myocardial infarction [AMI], and bleeding) across 3 EHR data sources: primary care (Clinical Practice Research Datalink [CPRD]), hospital care (Hospital Episode Statistics [HES]), and mortality (Office for National Statistics [ONS]) or disease registry data (Myocardial Ischaemia National Audit Project [MINAP]). Only a very small proportion (9% for heart failure, 31% for AMI, and <1% for bleeding) of cases are identified concurrently by all 3 data sources. ICD-10: International Classification of Diseases–Tenth Revision.
Case note review
We tested the validity of ICD-10 terms used in our bleeding phenotype and found an NPV of 0.94 (95% CI, 0.90-0.97) and a PPV of 0.88 (88% of bleeding events identified by the ICD-10 terms utilized in the CALIBER bleeding phenotype were indeed bleeding events according to the independent review of the entire hospital record by 2 clinicians, blinded to the term assignment. We found that ICD-10 coded events underestimate the occurrence of bleeding, with a sensitivity estimate of 0.48, consistent with a previous study where 38% of hospitalized bleeding events were not captured by coded terms.63 Specificity was found to be 0.99 (95% CI, 0.97-1.00), indicating a very low number of false positive bleeding events.
Etiology
Figure 4 shows age- and sex-adjusted HRs from Cox proportional hazards models for HF and CVD risk factors (smoking, type 2 diabetes, systolic blood pressure, heart rate) in CALIBER and non-EHR studies.
Risk factors for initial presentation of heart failure (HF) phenotype: hazard ratio (HR) and 95% confidence interval of smoking status, type 2 diabetes mellitus (T2DM), systolic blood pressure (BP) and heart rate based on previously published CALIBER studies29,75,76 compared with estimates obtained from investigator-led studies derived using manually curated research data.77–80 All individual analyses have been adjusted for age and sex and other covariates. Scale: 279 × 215 mm (72 × 72 dots per inch).
Prognosis
In 20 819 AMI cases, we found that patients with events recorded in only 1 source had higher mortality than did those recorded in more than 1 source (age- and sex-adjusted HR, 2.29; 95% CI, 2.17-2.42; P < .001).29 Among patients with AMI recorded in only 1 source, those only in CPRD had the highest mortality on the first day but the lowest mortality thereafter. Among patients with AMI recorded in HES or MINAP, those in MINAP had lower coronary mortality in the first month (age- and sex-adjusted HR, 0.33; 95% CI, 0.28-0.39; P < .001) but similar mortality for noncoronary events (HR, 1.12; 95% CI, 0.90-1.40; P = .3). After the first month, patients with AMI in CPRD had about half the hazard of mortality of patients with AMI recorded in 1 of MINAP or HES (age- and sex-adjusted HR, 0.49; 95% CI, 0.40-0.60; P < .001). In 89 994 HF cases, we observed 51 903 deaths and generated Kaplan–Meier curves for 90‐day survival. Adjusted for age and sex, HF was strongly associated with mortality, with HRs for all‐cause mortality ranging from 7.01 (95% CI, 6.83-7.20) to 7.23 (95% CI, 7.03-7.43), and up to 15.38 (95% CI, 15.02-15.83) for patients in CPRD with acute HF hospitalization, CPRD only, and HES only, compared with an age- and sex-matched reference population. Age, concomitant chronic obstructive pulmonary disease, and diabetes were among the strongest predictors of death. Compared with patients with no bleeding, patients with bleeding recorded in CPRD and HES were at increased risk of all-cause mortality and atherothrombotic events (HR all-cause mortality for CPRD bleeding, 1.98; 95% CI: 1.86-2.11; and HR all-cause mortality for HES bleeding, 1.99; 95% CI: 1.92-2.05).
Genetic associations
In the CARDIoGRAMplusC4D genome-wide association study summary data, we identified 31 independent variants associated with AMI by linkage disequilibrium clumping (R2 < 0.001, 250 kb) genetic variants reaching genome-wide significance (P < 5 × 10–8). In the UK Biobank, we identified 8281 AMI cases and 394 933 controls, and excluded 5266 participants from the analysis due to self-reported AMI at baseline. From 31 previously reported single nucleotide polymorphisms, 31 (100%) had P < .05 with same direction, with 26 (83.8%) passing Bonferroni correction (P < .0016) (Supplementary Table 1).
External populations
We assessed the validity of the AMI, HF, and bleeding phenotypes by comparing long-term outcomes (any cause death, fatal AMI or stroke, hospital bleeding) in AMI survivors in England (n = 4653), Sweden (n = 5484), United States (n = 53 909), and France (n = 961).64 We found consistent associations with 12 baseline prognostic factors (age, sex, AMI, HF, diabetes, stroke, renal disease, peripheral arterial disease, atrial fibrillation, hospital bleeding, cancer, chronic obstructive pulmonary disease) and each outcome. In each country, we observed high 3-year crude cumulative risks of all-cause death (from 19.6% [England] to 30.2% [United States]), with the composite of AMI, stroke, or death (from 26.0% [France] to 36.2% [United States]) and hospitalized bleeding (from 3.1% [France] to 5.3% [United States]). Adjusted risks were similar across countries, but higher in the United States for all-cause death (Relative Risk (RR) United States vs. Sweden, 1.14; 95% CI, 1.04-1.26) and hospitalized bleeding (RR United States vs. Sweden, 1.54; 95% CI, 1.21-1.96). Similar analyses were performed for white blood cells, comparing all-cause mortality in England and New Zealand.65,66 High white blood cells within the reference range (8.65-10.05 × 109/L) was associated with significantly increased mortality compared with the middle quintile (6.25-7.25 × 109/L; adjusted HR for England, 1.51; 95% CI, 1.43-1.59; adjusted HR for New Zealand, 1.33; 95% CI, 1.06-1.65).
DISCUSSION
In this study, we describe the CALIBER phenotyping approach, which has been used to produce 51 validated phenotyping algorithms which capture disease status, biomarker values, and lifestyle risk factors across 4 UK national EHR data sources spanning primary care, hospital admissions, a disease registry, and a mortality register. Creating nationally applicable phenotypes leveraging multiple EHR sources has, until recently, been a challenging, time-consuming, unreplicable, and somewhat opaque process without any centralized resources. Research studies require precise phenotype definitions but phenotypic information found in EHR is typically inconsistent and of variable data quality. These problems are exacerbated when linking data across healthcare settings (primary care and hospital admissions), as each source records information using different healthcare processes, disparate formats, and terminologies and interact with fundamentally different patient populations. Complementary initiatives exist,19 but these are different from CALIBER, as they focus on curating code lists. We have taken a different approach and define an EHR phenotype as a combination of 3 essential elements: controlled clinical terminology terms, implementation logic, and validation evidence, all of which are curated on the CALIBER Portal. Compared with the Phenotype Knowledgebase developed by the eMERGE consortium, CALIBER includes additional approaches of validation, such as etiological and prognostic across population samples, but lacks comprehensive detailed PPV or NPV measurements that are made possible by the availability of text and access to case notes at scale in the United States.
CALIBER phenotyping algorithms use structured information on diagnoses, symptoms, referrals, prescriptions, and procedures, which are recorded using 5 controlled clinical terminologies and continuous measurements to extract disease onset and severity. The actual phenotyping algorithm production was lengthy and labor intensive and usually involved a large number of iterations although the exact number of person hours was difficult to ascertain. A particular challenge was the need to reconcile differences in granularity of diagnosis terms used in primary care and secondary care EHR, as each healthcare setting utilizes different clinical terminologies to record information (Read in primary care, ICD-10 in secondary care). For example, in HF, the Read controlled clinical terminology allowed us to potentially distinguish between the 2 main congestive heart failure types: heart failure with normal or preserved ejection fraction (Read term “G583.11 HFNEF - heart failure with normal ejection fraction”) and heart failure with reduced ejection function or left ventricular systolic dysfunction (Read term “G5yy900 - Left ventricular systolic dysfunction”). Conversely, ICD-10 terms are substantially less specific (ICD terms “I50.0 Congestive heart failure” and “I50.9 Heart failure, unspecified”) and do not allow for this distinction. As a rule, for overlapping diagnoses across multiple sources, CALIBER phenotypes utilize the source with the highest clinical resolution to ascertain disease status.
We found that diagnosis terms in primary care using Read terms were not always informative and could not directly be used to ascertain particular phenotypes. For example, when attempting to create a dietary phenotype, we identified 173 Read terms related to nutrition, which were recorded across 5.6 million diagnosis events. Only 8% of these, however, were sufficiently informative to infer a particular nutritional diet (for example, low-fat diet, gluten-free diet, diabetic diet, or low-sodium diet). The majority of terms used were generic terms that carried little information (“8CA4.00 Patient advised re diet” or “9N0H.00 Seen in dietician clinic”) and could not be used for ascertaining a phenotype with reasonable performance. While such terms could potentially be utilized as supporting information for other phenotypes (for example, diabetic diet as evidence of diabetes) they cannot be used to ascertain a phenotype directly.
We observed that clinically informed combinations of information across EHR sources improves case detection. All disease and syndrome phenotypes (n = 35) utilized information sourced from primary care and hospital care EHR and roughly half (n = 18) utilized cause-specific mortality information recorded in the national death register. In general, we considered EHR sources complementary to each other with each providing a different aspect of a patient’s disease state (chronic vs acute) rather than denote one as the authoritative source of information. One notable exception to this is mortality, in which we used the ONS date of death as the “gold standard,” as studies have shown that discrepancies exist between the recorded death dates in primary care EHR and the date recorded on the death certificate (ONS). A previous study67 of 118 571 deaths in England showed that a discrepancy existed in almost a quarter of deaths. Considerable variation was observed between GP practices on the degree of such discrepancies (in the majority of cases, the date of death recorded by the GP was after the date of death recorded on the death certificate). This is because GPs do not routinely see the death certificate (which is the definitive record of time and cause of death) and there is no legal obligation for them to record the date of death accurately. If there is a delay in their receipt of notification of death, they might record the date of death as the date of notification, or the date the patient’s record was closed, rather than the actual date of death. In line with previous literature we therefore used the ONS as the “gold standard” for ascertaining mortality.
A major effort of CALIBER has been to create longitudinal disease phenotypes that capture early and late manifestations of disease. We observed that the proportion of cases contributed by each EHR source differed by age at diagnosis: patients identified in secondary care EHR were substantially older than were those identified in primary care. For example, substantially more atrial fibrillation cases were identified in secondary care EHR rather than in primary care (32 930 cases compared with 11 068 from primary care), and using only a single source would have introduced bias and underestimated the incidence of disease. Conversely, type 2 diabetes cases were exclusively identified through primary care EHR with no cases identified exclusively in hospital EHR due to the fact that, such as other diseases such as hypertension, diagnosis, and management, is almost entirely performed in primary care.
Validation (Table 2) was a critical step for assessing the accuracy of EHR-derived phenotypes. We did not consider algorithm validation as a finite task, but rather as a constantly evolving process due to the underlying complexity of EHR data and the processes which generate them.68 We sought to address the spectrum of validation views and developed an approach that captures 6 levels of evidence. The majority of disease and syndrome phenotypes examined incidence estimates across different EHR sources and consistency with previous associations in terms of disease etiology and prognosis. Validation was more restricted in biomarker and lifestyle risk factor phenotypes because information was derived from only 1 particular source (in the case of biomarkers, measurements were exclusively identified in primary care). Clinician case note review was considered the “gold standard” of phenotype validation that enables PPV or NPV calculations but access to medical records was not widely available, and thus we could only perform this in a single instance. Prognostic validation was one of the main validation approaches where consistency with previously reported findings provided a degree of confidence in terms of phenotype validity (for exposures, outcomes, and covariates used in the analyses). Inconsistent results, however, were possible and could be explained due to multiple factors such as different health settings and sources of data, healthcare process factors and workflows and uncomparable definitions.
Systematic validation of the CALIBER EHR-derived phenotypes for HF, AMI, and bleeding across 6 approaches of evidence: cross-EHR concordance, case-note review, etiology, prognosis, genetic associations, and external populations
| Validation domain | Description | What has been done | ||
|---|---|---|---|---|
| HF | AMI | Bleeding | ||
| Cross-EHR source concordance | To what extent is the phenotype concordant across EHR sources? | The proportion of HF cases recorded in primary care and hospital care EHR was 27%31 | The proportion of nonfatal AMI defined across primary care, hospital care, and disease registry was 32%29 | The proportion of bleeding events recorded in primary care and hospital care was 12%, with 47% of bleeding events recorded only in primary care and 12% only in hospital care |
| Case-note review | What is the PPV and the NPV when comparing the algorithm with clinician review of case notes or “gold standard” source of information? | Compared with AMI defined in the disease registry, the PPV of AMI recorded in primary care was 92.2% (95% CI, 91.6%-92.8%) and in hospital admissions was 91.5% (95% CI, 90.8%-92.1%)29 | Compared through independent review by 2 clinicians, the PPV of bleeding events identified through the phenotyping algorithm was 0.88 | |
| Etiology | Are the prospective associations with risk actors consistent with previous evidence? | Type 2 diabetes,84 systolic/diastolic blood pressure,32 heart rate,85 socioeconomic deprivation,86 alcohol consumption,87 smoking,88 ethnicity,44,AMI,29 depression,89 neutrophil counts,90 eosinophil/lymphocyte counts,91 atrial fibrillation,30 sex92 | Type 2 diabetes,84 systolic/diastolic blood pressure,32 heart rate,85 socioeconomic deprivation,86 alcohol consumption,87 smoking,88 ethnicity,44 AMI,29 depression,89 neutrophil counts,90 eosinophil/lymphocyte counts,91 atrial fibrillation,30 influenza infection,93 ischemic presentations,94 sex92 | At 5 y, 29.1% (95% CI, 28.2%-29.9%) of atrial fibrillation patients, 21.9% (95% CI, 21.2%-22.5%) of myocardial infarction patients, 25.3% (95% CI, 24.2%-26.3%) of unstable angina patients and 23.4% (95% CI, 23.0%-23.8%) of stable angina had bleeding of any kind |
| Prognosis | Are the risks of subsequent events plausible? | Corrected for age and sex, HF was strongly associated with mortality, with HRs for all‐cause mortality ranging from 7.01 (95% CI, 6.83-7.20) to 7.23 (95% CI, 7.03-7.43), and up to 15.38 (95% CI, 15.02-15.83) for patients in primary care with acute HF hospitalization, primary care only, and patients hospitalized but no primary care record31 |
| The HR for all-cause mortality was 1.98 (95% CI, 1.86-2.11) for primary care bleeding with markers of severity, and 1.99 (95% CI, 1.92-2.05) for hospitalized bleeding without markers of severity, compared with patients with no bleeding |
| Genetic associations | Are the observed genetic associations plausible and concordance with previous evidence? | Consistent direction and magnitude of associations were replicated in 67 (97%) of previously reported genetic variants4 | ||
| External populations | Has the algorithm been tested (in any of the previous validation domains) in different countries? | We observed high 3-y crude cumulative risks of all-cause death (from 19.6% [England] to 30.2% [United States]); the composite of AMI, stroke, or death (from 26.0% [France] to 36.2% [United States]); and hospitalized bleeding (from 3.1% [France] to 5.3% [United States])64 | ||
| Validation domain | Description | What has been done | ||
|---|---|---|---|---|
| HF | AMI | Bleeding | ||
| Cross-EHR source concordance | To what extent is the phenotype concordant across EHR sources? | The proportion of HF cases recorded in primary care and hospital care EHR was 27%31 | The proportion of nonfatal AMI defined across primary care, hospital care, and disease registry was 32%29 | The proportion of bleeding events recorded in primary care and hospital care was 12%, with 47% of bleeding events recorded only in primary care and 12% only in hospital care |
| Case-note review | What is the PPV and the NPV when comparing the algorithm with clinician review of case notes or “gold standard” source of information? | Compared with AMI defined in the disease registry, the PPV of AMI recorded in primary care was 92.2% (95% CI, 91.6%-92.8%) and in hospital admissions was 91.5% (95% CI, 90.8%-92.1%)29 | Compared through independent review by 2 clinicians, the PPV of bleeding events identified through the phenotyping algorithm was 0.88 | |
| Etiology | Are the prospective associations with risk actors consistent with previous evidence? | Type 2 diabetes,84 systolic/diastolic blood pressure,32 heart rate,85 socioeconomic deprivation,86 alcohol consumption,87 smoking,88 ethnicity,44,AMI,29 depression,89 neutrophil counts,90 eosinophil/lymphocyte counts,91 atrial fibrillation,30 sex92 | Type 2 diabetes,84 systolic/diastolic blood pressure,32 heart rate,85 socioeconomic deprivation,86 alcohol consumption,87 smoking,88 ethnicity,44 AMI,29 depression,89 neutrophil counts,90 eosinophil/lymphocyte counts,91 atrial fibrillation,30 influenza infection,93 ischemic presentations,94 sex92 | At 5 y, 29.1% (95% CI, 28.2%-29.9%) of atrial fibrillation patients, 21.9% (95% CI, 21.2%-22.5%) of myocardial infarction patients, 25.3% (95% CI, 24.2%-26.3%) of unstable angina patients and 23.4% (95% CI, 23.0%-23.8%) of stable angina had bleeding of any kind |
| Prognosis | Are the risks of subsequent events plausible? | Corrected for age and sex, HF was strongly associated with mortality, with HRs for all‐cause mortality ranging from 7.01 (95% CI, 6.83-7.20) to 7.23 (95% CI, 7.03-7.43), and up to 15.38 (95% CI, 15.02-15.83) for patients in primary care with acute HF hospitalization, primary care only, and patients hospitalized but no primary care record31 |
| The HR for all-cause mortality was 1.98 (95% CI, 1.86-2.11) for primary care bleeding with markers of severity, and 1.99 (95% CI, 1.92-2.05) for hospitalized bleeding without markers of severity, compared with patients with no bleeding |
| Genetic associations | Are the observed genetic associations plausible and concordance with previous evidence? | Consistent direction and magnitude of associations were replicated in 67 (97%) of previously reported genetic variants4 | ||
| External populations | Has the algorithm been tested (in any of the previous validation domains) in different countries? | We observed high 3-y crude cumulative risks of all-cause death (from 19.6% [England] to 30.2% [United States]); the composite of AMI, stroke, or death (from 26.0% [France] to 36.2% [United States]); and hospitalized bleeding (from 3.1% [France] to 5.3% [United States])64 | ||
AMI: acute myocardial infarction; CI: confidence interval; EHR: electronic health record; HF: heart failure; HR: hazard ratio; NPV: negative predictive value; PPV: positive predictive value.
Systematic validation of the CALIBER EHR-derived phenotypes for HF, AMI, and bleeding across 6 approaches of evidence: cross-EHR concordance, case-note review, etiology, prognosis, genetic associations, and external populations
| Validation domain | Description | What has been done | ||
|---|---|---|---|---|
| HF | AMI | Bleeding | ||
| Cross-EHR source concordance | To what extent is the phenotype concordant across EHR sources? | The proportion of HF cases recorded in primary care and hospital care EHR was 27%31 | The proportion of nonfatal AMI defined across primary care, hospital care, and disease registry was 32%29 | The proportion of bleeding events recorded in primary care and hospital care was 12%, with 47% of bleeding events recorded only in primary care and 12% only in hospital care |
| Case-note review | What is the PPV and the NPV when comparing the algorithm with clinician review of case notes or “gold standard” source of information? | Compared with AMI defined in the disease registry, the PPV of AMI recorded in primary care was 92.2% (95% CI, 91.6%-92.8%) and in hospital admissions was 91.5% (95% CI, 90.8%-92.1%)29 | Compared through independent review by 2 clinicians, the PPV of bleeding events identified through the phenotyping algorithm was 0.88 | |
| Etiology | Are the prospective associations with risk actors consistent with previous evidence? | Type 2 diabetes,84 systolic/diastolic blood pressure,32 heart rate,85 socioeconomic deprivation,86 alcohol consumption,87 smoking,88 ethnicity,44,AMI,29 depression,89 neutrophil counts,90 eosinophil/lymphocyte counts,91 atrial fibrillation,30 sex92 | Type 2 diabetes,84 systolic/diastolic blood pressure,32 heart rate,85 socioeconomic deprivation,86 alcohol consumption,87 smoking,88 ethnicity,44 AMI,29 depression,89 neutrophil counts,90 eosinophil/lymphocyte counts,91 atrial fibrillation,30 influenza infection,93 ischemic presentations,94 sex92 | At 5 y, 29.1% (95% CI, 28.2%-29.9%) of atrial fibrillation patients, 21.9% (95% CI, 21.2%-22.5%) of myocardial infarction patients, 25.3% (95% CI, 24.2%-26.3%) of unstable angina patients and 23.4% (95% CI, 23.0%-23.8%) of stable angina had bleeding of any kind |
| Prognosis | Are the risks of subsequent events plausible? | Corrected for age and sex, HF was strongly associated with mortality, with HRs for all‐cause mortality ranging from 7.01 (95% CI, 6.83-7.20) to 7.23 (95% CI, 7.03-7.43), and up to 15.38 (95% CI, 15.02-15.83) for patients in primary care with acute HF hospitalization, primary care only, and patients hospitalized but no primary care record31 |
| The HR for all-cause mortality was 1.98 (95% CI, 1.86-2.11) for primary care bleeding with markers of severity, and 1.99 (95% CI, 1.92-2.05) for hospitalized bleeding without markers of severity, compared with patients with no bleeding |
| Genetic associations | Are the observed genetic associations plausible and concordance with previous evidence? | Consistent direction and magnitude of associations were replicated in 67 (97%) of previously reported genetic variants4 | ||
| External populations | Has the algorithm been tested (in any of the previous validation domains) in different countries? | We observed high 3-y crude cumulative risks of all-cause death (from 19.6% [England] to 30.2% [United States]); the composite of AMI, stroke, or death (from 26.0% [France] to 36.2% [United States]); and hospitalized bleeding (from 3.1% [France] to 5.3% [United States])64 | ||
| Validation domain | Description | What has been done | ||
|---|---|---|---|---|
| HF | AMI | Bleeding | ||
| Cross-EHR source concordance | To what extent is the phenotype concordant across EHR sources? | The proportion of HF cases recorded in primary care and hospital care EHR was 27%31 | The proportion of nonfatal AMI defined across primary care, hospital care, and disease registry was 32%29 | The proportion of bleeding events recorded in primary care and hospital care was 12%, with 47% of bleeding events recorded only in primary care and 12% only in hospital care |
| Case-note review | What is the PPV and the NPV when comparing the algorithm with clinician review of case notes or “gold standard” source of information? | Compared with AMI defined in the disease registry, the PPV of AMI recorded in primary care was 92.2% (95% CI, 91.6%-92.8%) and in hospital admissions was 91.5% (95% CI, 90.8%-92.1%)29 | Compared through independent review by 2 clinicians, the PPV of bleeding events identified through the phenotyping algorithm was 0.88 | |
| Etiology | Are the prospective associations with risk actors consistent with previous evidence? | Type 2 diabetes,84 systolic/diastolic blood pressure,32 heart rate,85 socioeconomic deprivation,86 alcohol consumption,87 smoking,88 ethnicity,44,AMI,29 depression,89 neutrophil counts,90 eosinophil/lymphocyte counts,91 atrial fibrillation,30 sex92 | Type 2 diabetes,84 systolic/diastolic blood pressure,32 heart rate,85 socioeconomic deprivation,86 alcohol consumption,87 smoking,88 ethnicity,44 AMI,29 depression,89 neutrophil counts,90 eosinophil/lymphocyte counts,91 atrial fibrillation,30 influenza infection,93 ischemic presentations,94 sex92 | At 5 y, 29.1% (95% CI, 28.2%-29.9%) of atrial fibrillation patients, 21.9% (95% CI, 21.2%-22.5%) of myocardial infarction patients, 25.3% (95% CI, 24.2%-26.3%) of unstable angina patients and 23.4% (95% CI, 23.0%-23.8%) of stable angina had bleeding of any kind |
| Prognosis | Are the risks of subsequent events plausible? | Corrected for age and sex, HF was strongly associated with mortality, with HRs for all‐cause mortality ranging from 7.01 (95% CI, 6.83-7.20) to 7.23 (95% CI, 7.03-7.43), and up to 15.38 (95% CI, 15.02-15.83) for patients in primary care with acute HF hospitalization, primary care only, and patients hospitalized but no primary care record31 |
| The HR for all-cause mortality was 1.98 (95% CI, 1.86-2.11) for primary care bleeding with markers of severity, and 1.99 (95% CI, 1.92-2.05) for hospitalized bleeding without markers of severity, compared with patients with no bleeding |
| Genetic associations | Are the observed genetic associations plausible and concordance with previous evidence? | Consistent direction and magnitude of associations were replicated in 67 (97%) of previously reported genetic variants4 | ||
| External populations | Has the algorithm been tested (in any of the previous validation domains) in different countries? | We observed high 3-y crude cumulative risks of all-cause death (from 19.6% [England] to 30.2% [United States]); the composite of AMI, stroke, or death (from 26.0% [France] to 36.2% [United States]); and hospitalized bleeding (from 3.1% [France] to 5.3% [United States])64 | ||
AMI: acute myocardial infarction; CI: confidence interval; EHR: electronic health record; HF: heart failure; HR: hazard ratio; NPV: negative predictive value; PPV: positive predictive value.
In terms of the complete hospital interaction, HES data are a snapshot of the patient journey as data are collected for hospital reimbursement.8,52 Hospital records are converted into diagnosis and procedure codes locally (following an existing protocol) at each hospital and submitted to the NHS. HES data are provided to researchers with identifiers for hospitals removed to protect patient anonymity as a common identifier is used across HES and CPRD GP practices, which have a substantially smaller catchment area. As such, we were unable to assess the effect of site-level variability in terms of data capture and quality and phenotype validity. Multiple initiatives, however, exist for obtaining raw hospital records for research, such as the National Institute for Health Research Health Informatics Collaborative, which links 11 intensive care units in 5 hospitals for research (>18 000 patients, >21 000 admissions, median 1030 time-varying measures).69 Crucially, these initiatives will enable researchers to have access to raw hospital data, including free text, for creating and validating phenotypes and will create a feedback loop with clinical care that will provide detailed information on the healthcare processes generating the data (critical for phenotyping) and drive data standardization and quality.
CALIBER phenotyping algorithms are rule-based, deterministic, and provide a framework on which future phenotypes can be created. While our approach yields robust and accurate algorithms, it does not scale with our ambition to create and curate thousands of high-quality phenotypes (and their validation) that capture the entire human phenome. To do this, research is required on high-throughput phenotyping involving supervised and unsupervised learning approaches and natural language processing.70 Such methods can generate thousands of phenotypes and discover hidden associations within clinical data in a fraction of the current cost and time requirements and with minimal human intervention. Robust approaches for classifying phenotype complexity are required to ensure proportional resourcing for phenotyping.71 Finally, a key next step is to use the 6 sites of the recently funded Health Data Research UK national institute to scale up the number of phenotypes created and curated using UK EHR.
The use of a common data model to map between the clinical terminologies used across EHR sources, such as the Observational Medical Outcomes Partnership Common Data Model can potentially address some of the labor-intensive tasks associated with phenotyping. For example, the translation from phenotype definition to SQL for data extraction was manual due to the lack of an established storage format72 for the algorithms and variable schema across EHR sources. Observational Medical Outcomes Partnership Common Data Model can potentially act as Relational Database Management System agnostic schema which standardized analytical tools can be deployed on and has been shown to be robust73,74 and we are currently in the process of evaluating the fidelity of the data transformation. We have additionally evaluated different approaches (Semantic Web Technologies, openEHR)75,76 for storing phenotype definitions in a computable format that can enable high-throughput phenotyping and eliminate the need for manual human-driven translation to SQL queries. Given that all of UK primary care EHR data are hosted on 4 clinical information systems vendors, there is a real opportunity to create computable phenotypes which can be utilized across the NHS.77 To accomplish this, information exchange standards (for example, Fast Healthcare Interoperability Resources78) have to be utilized and combined with approaches such as the Phenotype Execution and Modeling Architecture79 and the Measure Authoring Tool.80
CONCLUSION
We have demonstrated the strengths and challenges of phenotyping national UK EHR data using 3 exemplars (HF, AMI, bleeding) and have exemplified the United Kingdom’s national EHR phenomics platform. In this manuscript, we presented the CALIBER platform as a framework for using national EHR from primary and secondary health care, disease and national mortality registries. CALIBER is analogous and complementary to other leading initiatives, (for example, eMERGE), in that it ensures best practice and reproducibility for creating and validating EHR-derived phenotypes.81,82 In contrast with eMERGE, however, which uses secondary care data (higher proportion of disease), CALIBER exploits primary care EHRs, which contain healthy and ill individuals. Importantly, the approaches described here are potentially scalable or adaptable to the entire UK population of 65 million.
Through CALIBER we provide a framework for the consistent definition, use, and reuse of EHR-derived phenotypes from national UK EHR sources for observational research: (1) high-resolution clinical epidemiology using national EHRs examining disease etiology or prognosis96 or (2) genetic epidemiology studies through the UK Biobank and Genomics England investigating simple and complex traits across populations. One of the primary audiences of CALIBER phenotypes is international: U.S. investigators account for a third of studies using UK primary care EHRs18 and two-thirds of UK Biobank studies are carried out by U.S. investigators. Additionally, the controlled clinical terminologies used in UK EHRs are directly translatable and transferable to the United States, for example, Read terms (CTV3 [Clinical Terms Version 3]) are part of SNOMED-CT, and ICD-9 Clinical Modification to ICD-10 mappings exist. As Phenotype Knowledgebase and other initiatives evolve, establishing links across national portals83 and infrastructure can enable cross-biobank analyses of complex or rare phenotypes.7
The creation of a national phenomics platform through CALIBER provides an opportunity for the UK EHR community to interact, nationally and internationally, and connects data producers and consumers. Researchers can deposit phenotyping algorithms in the Portal for others to download, refine, and use. EHR users (such as clinicians) can view these algorithms and understand how the data they record are being used for research.
FUNDING
This study is part of the BigData@Heart programme that has received funding from the Innovative Medicines Initiative 2 Joint Undertaking under grant agreement no. 116074. This Joint Undertaking receives support from the European Union's Horizon 2020 research and innovation programme and EFPIA. This work was supported by Health Data Research UK, which receives its funding from Health Data Research UK Ltd (NIWA1) funded by the UK Medical Research Council, Engineering and Physical Sciences Research Council, Economic and Social Research Council, Department of Health and Social Care (England), Chief Scientist Office of the Scottish Government Health and Social Care Directorates, Health and Social Care Research and Development Division (Welsh Government), Public Health Agency (Northern Ireland), British Heart Foundation, and the Wellcome Trust. This study was supported by National Institute for Health Research (RP-PG-0407-10314) and Wellcome Trust (086091/Z/08/Z). This study was supported by the Farr Institute of Health Informatics Research at UCL Partners, from the Medical Research Council, Arthritis Research UK, British Heart Foundation, Cancer Research UK, Chief Scientist Office, Economic and Social Research Council, Engineering and Physical Sciences Research Council, National Institute for Health Research, National Institute for Social Care and Health Research, and Wellcome Trust (MR/K006584/1). This article represents independent research part funded (AG-I, KD, NKF) by the National Institute for Health Research Biomedical Research Centre at University College London Hospitals. HH is an National Institute for Health Research Senior Investigator. ADS is a THIS Institute postdoctoral fellow. VK is supported by the Wellcome Trust (WT 110284/Z/15/Z). SD is supported by an Alan Turing Fellowship. RSP is funded by a BHF Fellowship FS/14/76/30933. ADH is an NIHR Senior Investigator. RTL is supported by a UKRI Rutherford Fellowship.
CONTRIBUTIONS
Conceived and designed the study: SD, HH. Analyzed the data: SD, LP, LJH, ADS, GF. Contributed reagents/materials/analysis tools: AGI, KD, NFK, GF, ADS, RD, VK. Wrote the paper: SD, HH. Commented on manuscript, contributed to revisions: AGI, KD, NFK, GF, AB, LP, RD, LJH, VK, RTL, LP, RSP, ADS, ADH, CS, HH. All authors reviewed and interpreted the results, read and approved the final version.
ACKNOWLEDGMENTS
This study was approved by the Medicines and Healthcare Products Regulatory Agency Independent Scientific Advisory Committee protocol references: 11_088, 12_153R, 16_221, 18_029R2, 18_159R. This study is based in part on data from the Clinical Practice Research Datalink obtained under license from the UK Medicines and Healthcare products Regulatory Agency. The data are provided by patients and collected by the NHS as part of their care and support. The interpretation and conclusions contained in this study are those of the author(s) alone. Hospital Episode Statistics Copyright (2019) is reused with the permission of The Health & Social Care Information Centre. All rights reserved. The Office of Population Censuses and Surveys Classification of Interventions and Procedures, codes, terms and text is Crown copyright (2016) published by Health and Social Care Information Centre, also known as NHS Digital and licensed under the Open Government Licence (available at www.nationalarchives.gov.uk/doc/open-government-licence/open-government-licence.htm). This study was carried out as part of the CALIBER programme (https://www.ucl.ac.uk/health-informatics/caliber). CALIBER, led from the UCL Institute of Health Informatics, is a research resource consisting of linked electronic health records phenotypes, methods and tools, specialized infrastructure, and training and support. The views expressed are those of the author(s) and not necessarily those of the National Health Service, the National Institute for Health Research, or the Department of Health. This paper represents independent research [part] funded by the National Institute for Health Research (NIHR) Biomedical Research Centre at South London and Maudsley NHS Foundation Trust and King's College London. The views expressed are those of the author(s) and not necessarily those of the NHS, the NIHR or the Department of Health and Social Care.
Conflict of interest statement
None declared.
REFERENCES

{kind=link}
{kind=link}
{kind=link}
{kind=link}