
Abstract
Accelerated design of hard-coating materials requires state-of-the-art computational tools, which include data-driven techniques, building databases, and training machine learning models. We develop a heavily automated high-throughput workflow to build a database of industrially relevant hard-coating materials, such as binary and ternary nitrides. We use the high-throughput toolkit to automate the density functional theory calculation workflow. We present results, including elastic constants that are a key parameter determining mechanical properties of hard-coatings, for X1−xYxN ternary nitrides, where X,Y ∈ {Al, Ti, Zr, Hf} and fraction \(x=0,\frac{1}{4},\frac{1}{2},\frac{3}{4},1\). We also explore ways for machine learning to support and complement the designed databases. We find that the crystal graph convolutional neural network trained on ordered lattices has sufficient accuracy for the disordered nitrides, suggesting that existing databases provide important data for predicting mechanical properties of qualitatively different types of materials, in our case disordered hard-coating alloys.
Similar content being viewed by others
Introduction
Hard-coating materials have a wide range of applications including metal cutting, scratch-resistant coatings, grinding, and aerospace and automotive parts. For metal cutting tools, hard coatings are essential to their machining performance, increasing it by orders of magnitude over uncoated tools in most applications. Since the beginning, high-hardness materials have been developed experimentally, but for a few decades computational tools, such as density functional theory (DFT)1,2 and molecular dynamics, have been used to support and complement experiments. However, as the design of new coatings moves from binary and ternary systems to quaternary and beyond, the combinatorial complexity increases rapidly, making conventional approaches increasingly difficult.
More recently, machine learning (ML) has been found to be a viable way to reduce the number of experiments, as well as computations, to accelerate the design process3,4,5,6,7. Demand for robust ML models is there, but a big hurdle in their adoption is the limited availability of data, either experimental or computational, that ML models need to be trained on. Experimental data has traditionally been relatively scarce, while computational databases, such as Materials Project8 and AFLOW9, have grown to contain tens or hundreds of thousands of entries. For example, Avery et al. used AFLOW and a combined ML and evolutionary search method to predict new superhard phases in carbon6. Mazhnik et al. used Materials Project data to train the crystal graph convolutional neural network (CGCNN)10 model to predict the bulk and shear moduli of ordered compounds using only the structural and chemical information of the system as input5, obtaining good results. In this paper, we extend the approach to qualitatively different class of materials, disordered alloys (as-deposited metastable thin films). It is well-known that ML is good at interpolation, but bad at extrapolation, and it is therefore vital to establish how well ML models extrapolate from ordered data to disordered data. We utilize a transfer learning (TL) approach11 to predict polycrystalline elastic constants of disordered alloys based on data obtained from ordered compounds. To the best of our knowledge, there are only very few TL studies in predicting properties of alloys. For a broad overview of ML approaches utilized in the case of alloys, see12.
From the point of view of practical applications, e.g., to design new hard coatings, however, currently existing databases are lacking for two reasons. Firstly, elastic constants are important: for instance, the intrinsic hardness of a material can be qualitatively assessed from the elastic constants and moduli13,14. However, since elastic constants are demanding to calculate, only a limited fraction of the entries in existing databases have elastic constants data included. Secondly, most industrially relevant hard coatings, e.g., Ti1−xAlxN, Cr1−xAlxN, and Ti1−xSixN, are substitutionally disordered15, and are often thermodynamically metastable or even unstable, which is possible due to the far-from-equilibrium synthesis techniques of physical vapor deposition. Existing databases, on the other hand, are focused on ordered compounds. Creating databases for disordered systems is therefore an activity that requires more attention. There is a recent effort to enable data-driven study of high-entropy ceramics16, and in this paper we work towards a database of disordered hard-coating materials. Because of significant computational costs, direct first-principles calculations for disordered alloys would lead to a relatively small database, which limits the amount of data to train ML models on. On the other hand, there are recent efforts in literature to find ways to make ML useful for small datasets11,17,18,19,20.
Given the abundance of data for ordered compounds, we investigate how ordered data can help with the lack of disordered data. Using a bigger data set to help the modeling of a smaller data set is one of the goals of TL18. In this paper, we use a TL approach, in which the CGCNN model is trained on the data for ordered compounds available in Materials Project, and the model is then used to predict the properties of disordered systems. We are interested in predicting quantities that are known to correlate with the intrinsic hardness of materials, such as bulk and shear moduli21,22,23,24. We find that even without an explicit inclusion of the data for disordered alloys in the model, it is able to predict the bulk and shear moduli of the industrially relevant nitrides with sufficient accuracy.
Results
DFT results
We calculate disordered binary and ternary nitrides of the form X1−xYxN, where X,Y ∈ {Al, Ti, Zr, Hf} and the concentration parameter \(x=0,\frac{1}{4},\frac{1}{2},\frac{3}{4},1\). The calculations are performed with and without taking atomic relaxations into account, so that we can assess the importance of the atomic relaxation effects. Cell shape and volume are optimized in both cases. Note that in this comparison in the unrelaxed B4 calculations we must fix the one available atomic degree of freedom along the z-direction. We fix it by setting the atomic unit cell coordinates as z1 = 0 and z2 = 0.38 in terms of the notation of ref. 25. One can define z1 = 0 without loss of generality and z2 = 0.38 represents the average value for the type of systems we consider here. It should be noted that the z2 coordinate is also called the u parameter in some literature sources26.
Let us first investigate the effect of atomic relaxations on the elastic constants. Assessment of the computational cost due to atomic relaxation is useful, because computing the elastic constants is time consuming. Thus, if the effect is minor, some computational time could be saved by neglecting atomic relaxations. Several previous studies have investigated the impact that atomic relaxations have on the elastic constant results27,28,29,30,31,32,33. In summary, the previous studies have found that, in most cases, relaxed and unrelaxed elastic constants are quite similar. Most often, the relative differences are lower than ≈ 10%. Relaxation effects can also be qualitatively estimated from symmetry arguments. For some lattice symmetries, a uniform deformation (used for elastic-constant calculations) may be sufficient to shift atoms from their equilibrium positions. This implies, in turn, that the resulting elastic tensors strongly depend on the strain matrix used for the calculation.
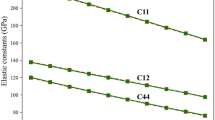
Table 1 shows the mean absolute errors (MAE) and mean absolute relative errors (MARE) (Xrel − Xunrel)/Xunrel between the relaxed and unrelaxed elastic constants and the polycrystalline quantities, calculated for all the alloys that can be found in Table 2, except for those that are marked B4 → Bk. We have not included those B4 structures that relaxed into Bk, because all unrelaxed calculations remain in the B4 phase and therefore are not directly comparable to the relaxed calculations that end up in the Bk phase (see Fig. 3). We can see that for the B1, which is a highly symmetric structure, relaxation effects are minor. With the B3 phase, atomic relaxation effects on calculated c11 and c12 are negligible. Conversely, the MAE and MARE values indicate a strong effect of atomic relaxation on c44. That is due to local B3-symmetry-breaking induced by shear lattice distortions. Also the B4 phase shows noticeable relaxation effects.
Based on our findings, if one is only interested in the bulk modulus, one might perform only unrelaxed calculations. If the shear modulus, or quantities that depend on the shear modulus, is of interest, the unrelaxed shear modulus will be accurate only for structures such as B1, where the different distortions do not break the symmetry in such a way that there are significant distortion dependent atomic movements.
The calculated elastic properties are shown in Table 2 and the mixing energies E[X1−xYxN] − (1 − x)E[XN] − xE[YN] and relative stabilities E[structure] − E[B1] of the B1 and B3 structure types are shown in Fig. 1. The B4 alloys, most of which relaxed into the Bk setting are not shown. All of the calculated alloys are found to be mechanically stable within a 10% tolerance of ϵ = 1.1 (see “DFT calculations”). Dynamical stability checks, which are based on phonon dispersion calculations, are out of the scope of this work, but based on existing literature some of the calculated alloys can be expected to be dynamically unstable. All two-component systems are ordered and those systems have been checked against available Materials Project data and the two sets have been found to be generally in good agreement. Our results for the well-studied Ti1−xAlxN system are also in agreement with literature data15,34,35,36.

a Calculated DFT mixing energies E[X1−xYxN] − (1 − x)E[XN] − xE[YN]. b Structural stability with respect to B1 with the same composition E[structure] − E[B1]. B4 alloys, most of which relaxed into the Bk setting (see Table 2) are not shown.
For the alloys in B1 structure we find good agreement with the elastic constants, bulk modulus, and mixing energy results of refs. 37,38. Reference 37 calculated the same set of alloys that can be found in Fig. 1, except for Hf1−xZrxN. The mixing energies of Fig. 1 are in general in good agreement with those of ref. 37, except for the trend found in ref. 37, whereby the obtained mixing energies that are highly symmetrical in terms of the concentration parameter x-axis. Our mixing energies in panel (a) of Fig. 1 show more pronounced asymmetry (except Hf1−xZrxN and Zr1−xTixN) with the x ≈ 1 side having larger positive mixing energies. The reason for these different trends could be related to differences in the SQS supercells between our study and ref. 37.
We notice that all alloys, except HfN and Al-rich alloys, prefer the planar Bk structure. We interpret the tendency to relax toward the planar Bk structure (u parameter ~0.5) as an effect induced by the dynamical instability (imaginary phonon frequencies39, see Fig. 3g in ref. 40) combined with an energetic preference for the Bk hexagonal polymorph41. Additionally, the B4 ZrN and HfN binaries are predicted to be dynamically stable in the Bk phase40.
Previous ab initio results41 and Fig. 1 suggest that X1−xAlxN (X = Ti, Zr, Hf) solid solutions energetically favor the B1 structure for Al contents x ≲ 0.5, whereas the wurtzite B4 alloy phase becomes the most stable for high x (≳ 0.7). At ambient conditions, the ordered TiN, HfN, and ZrN favor the B1 structure, which is also their ground state. Other recent ab initio results indicate that TiN can be metastable in the B4 structure (see Fig. 3g in ref. 40). Our calculations, however, do not find TiN to be stable in the B4 structure. Note, indeed, that ref. 40 reports phonon dispersion results only along a few high-symmetry directions. Evaluation of the B4 TiN phonon-density of states may be necessary to reveal imaginary frequencies.
Machine learning results
Given that it is relatively resource heavy to calculate the elastic tensor of disordered structures, a large amount of supercomputer time would be needed to amass a sizable database of such materials. We are therefore interested in different strategies to supplement or augment the database using ML techniques. One way to tackle the problem of low data availability is to train the ML model to a part of the available data that is related to the problem at hand, and then appropriately modifying and verifying the model with the smaller dataset. This is the basic idea behind TL18. In this work, we use an approach that might be considered a zeroth-order approximation to TL. In this approach, we train an ML model using Materials Project data, which are ordered compounds, and see how well that model predicts the disordered alloys simulated in the present study. In other words, we check how well the patterns learned from the ordered dataset, without modifications, transfer or generalize to the disordered dataset. If the ML model generalizes well, one can employ the network to predict, or at least estimate the properties of disordered systems outright, as the case may be, or use it as a basis for further training with the disordered dataset11. Performing more sophisticated TL, such as fine-tuning and layer freezing11,18, is out of the scope of this study and will be addressed in future work.
Throughout the ML section, the B4 phase is not included because most of the studied B4 alloys turns out to be unstable and transform into Bk structure upon structural relaxation. At the same time, information on compounds with Bk structure in the databases is insufficient to build reliable ML models: hexagonal systems (and the Bk in particular) are underrepresented in the training set (only ~1000 compounds are hexagonal out of the total 8000). One may view the inability to describe B4/Bk alloys as a limitation of the applicability of the ML and TL that requires further in-depth study. Additionally, those ordered binary compounds (concentration parameter x = 0 or 1) that can be found in the Materials Project data are excluded, because for those data points the error would be biased as they were part of the training set.
The ML architecture that we use is the CGCNN, and Mazhnik et al. have shown that it can be succesfully harnessed, together with Materials Project data, to predict simultaneously both the bulk and shear moduli of an input crystal structure. One could always train separate ML models for the bulk and shear moduli, but in the approach of Mazhnik et al. both quantities are treated on equal footing. Based on their good results, we are encouraged to implement a similar approach here. We employ a typical train-validate-test workflow to build the optimal CGCNN model from the Materials Project data.
The performance of the finished model is depicted in Table 3 in terms of MAE and MARE for the test set and the disordered dataset, with and without atomic relaxations. In the Table, the B1 + B3 means the combination of the B1 and B3 structure sets. We can see that the predictions made by the ML model for the disordered alloys with B1 and B3 crystal structure are quite accurate, even though no actual TL was done to the model. We notice that for the B3 structures the shear modulus prediction error is noticeably better for the relaxed data compared to unrelaxed data. This difference reflects the differences in unrelaxed and relaxed shear moduli in Table 1. There are two possible reasons that could explain this behavior. Firstly, the ML prediction error is smaller for the relaxed data, which makes sense since the model was trained on Materials Project data, for which atomic relaxation is used systematically. It is reasonable to assume that the bonding lengths of the unrelaxed structures appear unphysical to the ML model. That would explain why the model performs poorly for unrelaxed structures. Secondly, the CGCNN construction includes a certain cutoff parameter (8 Å in this work) that is used to make the descriptor of each atomic site finite; neighboring atomic sites that fall outside the cutoff radius are neglected. When the structure is relaxed, some atomic sites may move beyond the cutoff radius while others may move within the radius. The descriptors between relaxed and unrelaxed structures are therefore slightly different, which could create discrepancies in the ML results for relaxed and unrelaxed structures.
An interesting observation is that the test set and disordered nitrides MAEs show opposite qualitative trends; for the test set, the shear modulus MAE is smaller than the bulk modulus MAE, while for the disordered data this trend is reversed. Overall, the average ML prediction error for the disordered nitrides is good for the bulk modulus and somewhat worse for the shear modulus. We can say that the CGCNN architecture generalizes quite well from ordered systems to disordered ones even without explicit fine-tuning of the ML model.
To get a clearer picture of the performance of the ML model, Fig. 2 shows a parity plot of the DFT versus ML predicted values (B4/Bk not included). Panel (a) of Fig. 2 shows the performance of the network for the test set (green round markers), as well as for the training set (blue cross markers). The figure also shows ML predictions for Young’s modulus E and Poisson’s ratio ν, which are not directly produced by the ML model, but can be calculated from the predicted bulk and shear moduli. Our results for the test set are comparable to those of Mazhnik et al.5. The prediction accuracy for the disordered nitrides falls within the accuracy range of the Materials Project test set.

a Materials Project training, validation, and test sets. Blue cross markers indicate training set, red diamonds validation set, and green disks test set. b Disordered nitrides test set. The minimum and maximum DFT and ML prediction values for the disordered nitrides are also labeled by chemical formulas and dashed lines.
Panel (b) of Fig. 2 shows how well the ML model with the lowest loss function performs for the disordered nitrides. We can see a fairly tight clustering around the diagonal and an absense of major outliers. Clear outliers or significant scatter for the nitrides is not expected anyway, because the disordered dataset is very homogeneous (in terms of the variety of structures and chemical elements) compared to the Materials Project training set, so the ML model should work similarly for all the data points the disordered data. We can identify some structure specific trends in the ML prediction accuracy. While the bulk and shear moduli of the B3 structures are especially well predicted, the B1 shear moduli show a lower accuracy. For the B1 phase the shear modulus is consistently underestimated and the largest single underestimation is ≈ 50 GPa. It is not easy to give a simple reason for the inconsistent shear modulus prediction performance, but we can note that the shear modulus, as evidenced by Table 1, is a more sensitive quantity than the bulk modulus. It is the aim of future studies to see how much fine-tuning the current ML network will improve the prediction accuracy.
Discussion
We have developed an automated high-throughput workflow for building a computational database of disordered hard-coating materials and presented results of our calculations. The reliability of our data is verified by comparing to the Materials Project data and existing literature. Moreover, we have trained the CGCNN ML model on ordered compounds from the Materials Project and demonstrated that this model is able to readily predict the bulk and shear moduli of disordered nitrides with sufficient accuracy. The CGCNN architecture seems to be able to learn such fundamental patterns in the data that these patterns hold regardless of the degree of order, indicating good generalizability of CGCNN from ordered to disordered systems. Prediction accuracy for disordered systems can be further improved by using the ML model trained on ordered data as the starting point for TL. Our findings open new ways to gain insight into disordered hard-coating materials, as well as to support and possibly speed up the investigations of disordered hard-coating materials, which are computationally demanding to calculate and thus slow to accumulate into a large database.
Methods
DFT calculations
The DFT calculations were performed using the Vienna Ab initio Simulation Package (VASP)42,43. The exchange and correlation effects were treated at the generalized gradient approximation (GGA) level44,45,46 using the Perdew–Burke–Ernzerhof (PBE)47 functional. Energy cutoff is set to 500 eV in the preliminary relaxation phase and to 700 eV in subsequent phases. The precision mode is set to Accurate (PREC = Accurate). The Gaussian smearing scheme with a smearing width of 0.05 eV is used. Ionic relaxations are stopped when all forces are below the threshold 0.01 eV/Å. In cases where the threshold 0.01 eV/Å is difficult to reach, the threshold is increased to 0.03 eV/Å or 0.05 eV/Å. The elastic constants calculations include the support grid for augmentation charges (ADDGRID=.TRUE.).
The VASP calculations were managed with The High-Throughput Toolkit (httk)48,49. The httk software offers workflows to create input files, manage calculations on computing clusters, automatically fix broken calculations by adjusting VASP input settings, and organize results in databases. The automatic computation of elastic constants is implemented in httk.
In this work, we consider disordered binary and ternary nitrides in cubic rocksalt (B1)50, cubic zincblende (B3)51, and hexagonal wurtzite (B4)25 structures. These structure types are illustrated in Fig. 3. Disorder is modeled using the special quasirandom structures (SQS) technique52,53. The SQS supercells that are used in this study are listed in Supplementary Methods. Here, substitutional disorder is considered only on the metallic sublattice, i.e., the nitrogen sublattice is ordered because it is fully occupied by nitrogen atoms. All SQS supercells had size of 96 atoms. This size has been found to be within the optimal range for ternary nitrides from the standpoint of accuracy versus computational speed35. The B1 X0.5Y0.5N SQS cell is taken from the supplementary materials of ref. 35, where it is referred to as the (4 × 4 × 3) cell. In ref. 35 the (4 × 4 × 3) cell was found to model disorder at a high-quality level, that is, comparable to SQS cells of bigger sizes. The B3 X0.5Y0.5N SQS can be easily derived from the B1 X0.5Y0.5N SQS by noting that the B1 conventional unit cell turns into B3 when the N atom is shifted from the high-symmetry position \(\frac{1}{2}{\overrightarrow{a}}_{1}+\frac{1}{2}{\overrightarrow{a}}_{2}+\frac{1}{2}{\overrightarrow{a}}_{3}\) to another high-symmetry position \(\frac{1}{4}{\overrightarrow{a}}_{1}+\frac{1}{4}{\overrightarrow{a}}_{2}+\frac{1}{4}{\overrightarrow{a}}_{3}\). All the other SQS supercells are generated with the stochastic Monte-Carlo SQS program mcsqs54, which is part of the Alloy Theoretic Automated Toolkit (ATAT) program package55.

The larger red spheres indicate metallic sublattice and the smaller gray spheres the nitrogen sublattice.
Although the SQS scheme is an efficient way to simulate disorder, the downside is that the proper (macroscopic) symmetry is broken and the generated SQS cells typically only have triclinic symmetry. For the calculation of elastic constants this poses a problem, because we are interested in elastic constant tensors of cubic (B1 and B3) or hexagonal (B4) classes instead of triclinic-structure elastic tensors. In order to derive properly symmetrized elastic constants from the full triclinic elastic tensor, we employ the projection technique that has been discussed in ref. 35 and references therein. For the unprojected triclinic elastic constants, see Supplementary Tables. We can see that the deviations between the different crystallographic directions are small, even though the disordered SQS supercells do not respect the proper macroscopic symmetry. As ref. 35 shows, the projected elastic constants have the desirable property that they converge fast to the correct value as a function of supercell size, faster than the unprojected elastic constants. To facilitate automated calculations, we have implemented the symmetrization technique in httk. The elastic constants in VASP are calculated using the stress-strain method in the same general way that was used, e.g., in ref. 56. Four distorted structures are generated for each strain component (in terms of Voigt notation) and the range of distortion are −3%, −1.5%, 1.5%, 3% for non-shear components and −6%, −3%, 3%, 6% for shear components. All polycrystalline quantities are calculated using the Hill averaging scheme56. The mechanical stability is checked based on the Born-Huang stability criteria57. In addition to the normal stability check, we also use the stricter tolerance based check of ref. 56. For example, cubic systems must fulfill a condition C11 > ∣C12∣ to be mechanically stable. In the tolerance based check, a more rigorous condition C11 > ϵ∣C12∣ (ϵ > 1) must be fulfilled. All of the calculated alloys are found to be mechanically stable. Dynamical stability checks, which are based on phonon dispersion calculations, are out of the scope of this work, but based on existing literature some of the calculated alloys can be expected to be dynamically unstable.
Machine learning
The ML part of this work is done using the PyTorch package. The CGCNN10 architecture is applied using the code available at GitHub as the basis58. In the CGCNN model the input crystal structure is transformed into a crystal graph, which is constructed from node feature vectors vi and edge feature vectors uij. The node feature vector encodes information about the type of atom located at atomic site i. The atomic information is encoded in an integer vector using one-hot or dummy encoding. For example, if the training data includes elements N, Al, and Ti, then the elements can be encoded as N ⇒ [1, 0, 0], Al ⇒ [0, 1, 0], and Ti ⇒ [0, 0, 1]. The edge feature vector encodes information about the bonds that the atom at site i makes with its nearest neighbors. This bonding information is encoded by discretizing a Gaussian distribution function centered around the nearest neighbors of the reference site i. The feature vector for site i with one of its nearest neighbors j is then calculated as
where dij is the distance between sites i and j, h is a discretization step size, and α is a vector of discretized trial distances
where Rcut is a cutoff radius to make the vector finite in length. We can see that when α is close to dij, uij has values close to one, and when α deviates from dij, uij is close to zero. The crystal graph is then fed into a convolutional neural network, which consists of convolutional layers and pooling layers. The convolutional layers iteratively modify the node feature vector of site i by convolving it with the edge feature vector uij and node feature vectors of surrounding sites j. The convolution is described by the equation
where \({{{{\bf{z}}}}}_{i,j}^{(t)}={{{{\bf{v}}}}}_{i}^{(t)}\oplus {{{{\bf{v}}}}}_{j}^{(t)}\oplus {{{{\bf{u}}}}}_{i,j}\) is the concatenation of the node and edge feature vectors, σ is the sigmoid activation function, g is the softplus activation function, and \({{{{\bf{W}}}}}_{\,{{\mbox{s}}}\,}^{(t)},{{{{\bf{W}}}}}_{\,{{\mbox{f}}}\,}^{(t)},{{{{\bf{b}}}}}_{\,{{\mbox{s}}}\,}^{(t)},{{{{\bf{b}}}}}_{\,{{\mbox{f}}}\,}^{(t)}\) are the weights and biases of the tth convolutional layer10. After R convolutional layers (three in this work), a pooling layer is applied to produce the overall feature vector of the crystal vc. The pooling layer is implemented as a normalized summation of all the feature vectors \({{{{\bf{v}}}}}_{1}^{(0)},{{{{\bf{v}}}}}_{2}^{(0)},\ldots ,{{{{\bf{v}}}}}_{1}^{(R)},{{{{\bf{v}}}}}_{2}^{(R)},\ldots ,{{{{\bf{v}}}}}_{N}^{(R)}\). Finally, vc is inputed to fully connected hidden layers (two in this work) that predict the output. A diagram of the CGCNN architecture is presented in Fig. 4.

A high-level representation of how a prediction is made for an input crystal structure (e.g. B3), by converting it into a crystal graph and then passing it through a series of purpose-build ML layers.
Following ref. 5, the network is trained to predict bulk and shear moduli using Materials Project data as the training and test datasets. At the time of writing, Materials Project contains a little over 8000 systems that have elasticity data available. We randomly split the data into training, validation, and test sets in a 8:1:1 ratio. While the training set is used to optimize the model parameters, the difference between the validation and test has to do with avoiding biases in the final estimation of the accuracy of the ML model. Here validation set is used to minimize overfitting in a way that is described below. This means that the validation set is part of the model optimization process and the model accuracy for the validation set is slightly biased. Hence we need a test set that only contains data that the final ML model has never seen before. By evaluating model performance on the test set is therefore a way to minimize biases and maximize the trustworthiness of the model accuracy estimate.
Before training, the target values (bulk and shear moduli) are normalized using the formula
where \(\bar{{{{\bf{y}}}}}\) is the mean and σ(y) is the standard deviation of the target vector y. The loss function to be minimized is defined in terms of the normalized bulk modulus \(\widetilde{{{{\bf{B}}}}}\) and shear modulus \(\widetilde{{{{\bf{G}}}}}\) as
where N is the number of data points. Based on the information of refs. 5,10,18 and their supplementary materials, as well as our own testing, we can infer reasonable values for the hyperparameters without performing extensive hyperparameter tuning. The crystal structure descriptor-related settings are the same as those reported in ref. 5. The training process uses the Adam optimizer with a learning rate of 0.005 and weight decay 0.0. Training is continued for a minimum of 500 epochs to give the randomly initialized model parameters enough time to develop. Training is stopped after 1500 epochs, as it is unlikely that any significant progress will happen after that point. In order to avoid the training process getting stuck in a suboptimal local minimum, 30 instances were trained. To reduce random variance, an ensemble of five networks with the lowest validation loss is used to make predictions. The validation set is used to decide the final model parameters by extracting the parameters from the epoch that yields the loss function minimum for the validation set. This is one form of the early stopping technique and the purpose is to mitigate overfitting issues59. Finally, an unbiased estimate of the performance of the finished model is obtained by evaluating the model using the unseen test set (see Table 3). For further details about the CGCNN architecture and the training process, the reader is referred to refs. 5,10,18.
Data availability
Relevant calculated DFT data and instructions to download the Materials Project data, as well as the trained ML model to reproduce the results of this paper can be downloaded from https://doi.org/10.6084/M9.FIGSHARE.17129045.V2.
Code availability
The code to reproduce the results of this paper can be downloaded from https://doi.org/10.6084/M9.FIGSHARE.17129045.V2.
References
Hohenberg, P. & Kohn, W. Inhomogeneous electron gas. Phys. Rev. 136, B864—B871 (1964).
Kohn, W. & Sham, L. J. Self-consistent equations including exchange and correlation effects. Phys. Rev. 140, A1133—A1138 (1965).
Bhadeshia, H. Neural networks in materials science. ISIJ Int. 39, 966–979 (1999).
Tehrani, A. M. et al. Machine learning directed search for ultraincompressible, superhard materials. J. Am. Chem. Soc. 140, 9844–9853 (2018).
Mazhnik, E. & Oganov, A. R. Application of machine learning methods for predicting new superhard materials. J. Appl. Phys. 128, 075102 (2020).
Avery, P. et al. Predicting superhard materials via a machine learning informed evolutionary structure search. npj Comput. Mater. 5, 89 (2019).
Bedolla, E., Padierna, L. C. & Castañeda-Priego, R. Machine learning for condensed matter physics. J. Phys. Condens. Matter 33, 053001 (2020).
Jain, A. et al. Commentary: The Materials Project: a materials genome approach to accelerating materials innovation. APL Mater. 1, 011002 (2013).
Curtarolo, S. et al. AFLOWLIB.ORG: A distributed materials properties repository from high-throughput ab initio calculations. Comput. Mater. Sci. 58, 227–235 (2012).
Xie, T. & Grossman, J. C. Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties. Phys. Rev. Lett. 120, 145301 (2018).
Yamada, H. et al. Predicting materials properties with little data using shotgun transfer learning. ACS Cent. Sci. 5, 1717–1730 (2019).
Hart, G. L. W., Mueller, T., Toher, C. & Curtarolo, S. Machine learning for alloys. Nat. Rev. Mater. 6, 730–755 (2021).
Tse, J. S. Intrinsic hardness of crystalline solids. J. Superhard Mater. 32, 177–191 (2010).
Tehrani, A. M. & Brgoch, J. Hard and superhard materials: a computational perspective. J. Solid State Chem. 271, 47–58 (2019).
Abrikosov, I. A. et al. Phase stability and elasticity of TiAlN. Materials 4, 1599–1618 (2011).
Oses, C., Toher, C. & Curtarolo, S. High-entropy ceramics. Nat. Rev. Mater. 5, 295–309 (2020).
De Breuck, P.-P., Hautier, G. & Rignanese, G.-M. Materials property prediction for limited datasets enabled by feature selection and joint learning with MODNet. npj Comput. Mater. 7, 83 (2021).
Lee, J. & Asahi, R. Transfer learning for materials informatics using crystal graph convolutional neural network. Comput. Mater. Sci. 190, 110314 (2021).
Zhang, Y. & Ling, C. A strategy to apply machine learning to small datasets in materials science. npj Comput. Mater. 4, 25 (2018).
Chen, C., Zuo, Y., Ye, W., Li, X. & Ong, S. P. Learning properties of ordered and disordered materials from multi-fidelity data. Nat. Comput. Sci. 1, 46–53 (2021).
Oganov, A. R. & Lyakhov, A. O. Towards the theory of hardness of materials. J. Superhard Mater. 32, 143–147 (2010).
Tian, Y., Xu, B. & Zhao, Z. Microscopic theory of hardness and design of novel superhard crystals. Int. J. Refract. Met. Hard Mater. 33, 93–106 (2012).
Kvashnin, A. G., Allahyari, Z. & Oganov, A. R. Computational discovery of hard and superhard materials. J. Appl. Phys. 126, 040901 (2019).
Mazhnik, E. & Oganov, A. R. A model of hardness and fracture toughness of solids. J. Appl. Phys. 126, 125109 (2019).
Mehl, M. J. et al. Prototype of the B4 structure. http://aflowlib.org/prototype-encyclopedia/AB_hP4_186_b_b.html (2021).
Kisi, E. H. & Elcombe, M. M. U parameters for the wurtzite structure of ZnS and ZnO using powder neutron diffraction. Acta Crystallogr. C: Cryst. Struct. Commun. 45, 1867–1870 (1989).
Tian, L.-Y. et al. Elastic constants of random solid solutions by SQS and CPA approaches: The case of fcc Ti-Al. J. Phys. Condens. Matter 27, 315702 (2015).
Tian, L.-Y. et al. Alloying effect on the elastic properties of refractory high-entropy alloys. Mater. Des. 114, 243–252 (2016).
Song, H. et al. Local lattice distortion in high-entropy alloys. Phys. Rev. Mater. 1, 023404 (2017).
Tian, L.-Y. et al. CPA descriptions of random Cu-Au alloys in comparison with SQS approach. Comput. Mater. Sci. 128, 302–309 (2017).
Kim, G. et al. First-principles and machine learning predictions of elasticity in severely lattice-distorted high-entropy alloys with experimental validation. Acta Mater. 181, 124–138 (2019).
Jafary-Zadeh, M., Khoo, K. H., Laskowski, R., Branicio, P. S. & Shapeev, A. V. Applying a machine learning interatomic potential to unravel the~effects of local lattice distortion on the elastic properties of multi-principal element alloys. J. Alloy. Compd. 803, 1054–1062 (2019).
Taga, A., Vitos, L., Johansson, B. & Grimvall, G. Ab initio calculation of the elastic properties of Al(1-x)Li(x) (x < =0.20) random alloys. Phys. Rev. B 71, 014201 (2005).
Lind, H. et al. Improving thermal stability of hard coating films via a concept of multicomponent alloying. Appl. Phys. Lett. 99, 091903 (2011).
Tasnádi, F., Odén, M. & Abrikosov, I. A. Ab initio elastic tensor of cubic Ti0.5Al0.5N alloys: Dependence of elastic constants on size and shape of the supercell model and their convergence. Phys. Rev. B 85, 144112 (2012).
Shulumba, N. et al. Temperature-dependent elastic properties of Ti1-xAlxN alloys. Appl. Phys. Lett. 107, 231901 (2015).
Holec, D., Zhou, L., Rachbauer, R. & Mayrhofer, P. H. Alloying-related trends from first principles: An application to the Ti-Al-X-N system. J. Appl. Phys. 113, 113510 (2013).
Wang, F. et al. Systematic ab initio investigation of the elastic modulus in quaternary transition metal nitride alloys and their coherent multilayers. Acta Mater. 127, 124–132 (2017).
Isaev, E. I. et al. Phonon related properties of transition metals, their carbides, and nitrides: A first-principles study. J. Appl. Phys. 101, 123519 (2007).
Arango-Ramirez, M., Vargas-Calderon, A. & Garay-Tapia, A. M. On the importance of hexagonal phases in TM (TM = Ti, Zr, and Hf) mono-nitrides. J. Appl. Phys. 128, 105106 (2020).
Holec, D. et al. Phase stability and alloy-related trends in Ti–Al–N, Zr–Al–N and Hf–Al–N systems from first principles. Surf. Coat. Technol. 206, 1698–1704 (2011).
Kresse, G. & Furthmüller, J. Efficiency of ab-initio total energy calculations for metals and semiconductors using a plane-wave basis set. Comput. Mater. Sci. 6, 15–50 (1996).
Kresse, G. & Furthmüller, J. Efficient iterative schemes for ab initio total-energy calculations using a plane-wave basis set. Phys. Rev. B 54, 11169–11186 (1996).
Langreth, D. C. & Mehl, M. J. Beyond the local-density approximation in calculations of ground-state electronic properties. Phys. Rev. B 28, 1809–1834 (1983).
Perdew, J. P. Accurate density functional for the energy: real-space cutoff of the gradient expansion for the exchange hole. Phys. Rev. Lett. 55, 1665–1668 (1985).
Perdew, J. P. & Yue, W. Accurate and simple density functional for the electronic exchange energy: Generalized gradient approximation. Phys. Rev. B 33, 8800–8802 (1986).
Perdew, J. P., Burke, K. & Ernzerhof, M. Generalized gradient approximation made simple. Phys. Rev. Lett. 77, 3865–3868 (1996).
Armiento, R. The high-throughput toolkit (httk). https://httk.org/ (2021).
Armiento, R. In Machine Learning Meets Quantum Physics (eds Schütt, K. T., Chmiela, S., von Lilienfeld, O. A., Tkatchenko, A., Tsuda, K. & Müller, K.-R.) 377–395 (Springer International Publishing, 2020).
Mehl, M. J. et al. Prototype of the B1 structure. http://aflowlib.org/prototype-encyclopedia/AB_cF8_225_a_b.html (2021).
Mehl, M. J. et al. Prototype of the B3 structure. http://aflowlib.org/prototype-encyclopedia/AB_cF8_216_c_a.html (2021).
Zunger, A., Wei, S.-H., Ferreira, L. G. & Bernard, J. E. Special quasirandom structures. Phys. Rev. Lett. 65, 353–356 (1990).
Wei, S. H., Ferreira, L. G., Bernard, J. E. & Zunger, A. Electronic properties of random alloys: Special quasirandom structures. Phys. Rev. B 42, 9622–9649 (1990).
Van De Walle, A. et al. Efficient stochastic generation of special quasirandom structures. Calphad Comput. Coupling Phase Diagr. Thermochem. 42, 13–18 (2013).
Van de Walle, a., Asta, M., Ceder, G. & Cederb, G. The alloy theoretic automated toolkit: A user guide. Calphad Comput Coupling Phase Diagr. Thermochem 26, 539–553 (2002).
Jong, M. D. et al. Charting the complete elastic properties of inorganic crystalline compounds. Sci. Data 2, 150009 (2015).
Mouhat, F. & Coudert, F.-X. Necessary and sufficient elastic stability conditions in various crystal systems. Phys. Rev. B 90, 224104 (2014).
Xie, T. https://github.com/txie-93/cgcnn (2021).
Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning (Springer, 2009).
Acknowledgements
The authors gratefully acknowledge financial support from the Competence Center Functional Nanoscale Materials (FunMat-II) (Vinnova Grant No. 2016-05156). Support from the Knut and Alice Wallenberg Foundation (Wallenberg Scholar Grant No. KAW-2018.0194), the Swedish Government Strategic Research Areas in Materials Science on Functional Materials at Linköping University (Faculty Grant SFO-Mat-LiU No. 2009 00971) and SeRC is gratefully acknowledged. Theoretical analysis of results of first-principles calculations was supported by the Russian Science Foundation (Project No. 18-12-00492). R.A. acknowledges support from the Swedish Research Council (VR) Grant No. 2020-05402 and the Swedish e-Science Centre (SeRC). The computations were enabled by resources provided by the Swedish National Infrastructure for Computing (SNIC), partially funded by the Swedish Research Council through grant agreement no. 2018-05973. The computational resources provided by the PDC Center for High Performance Computing are also acknowledged.
Funding
Open access funding provided by Linköping University.
Author information
Authors and Affiliations
Contributions
H.L., R.A., and I.A.A. conceived the project. H.L. performed the calculations and analyzed the results. H.L., F.T., D.G.S., L.J.S.J., R.A., and I.A.A. discussed the results and wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Levämäki, H., Tasnádi, F., Sangiovanni, D.G. et al. Predicting elastic properties of hard-coating alloys using ab-initio and machine learning methods. npj Comput Mater 8, 17 (2022). https://doi.org/10.1038/s41524-022-00698-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41524-022-00698-7
