3.1. Inpatient Mortality (IPD)
The results section describes the performance metrics of the predictive models constructed in this study, as well as the conditional probabilities of outcome occurrence given different exemplary combinations of independent factor variables.
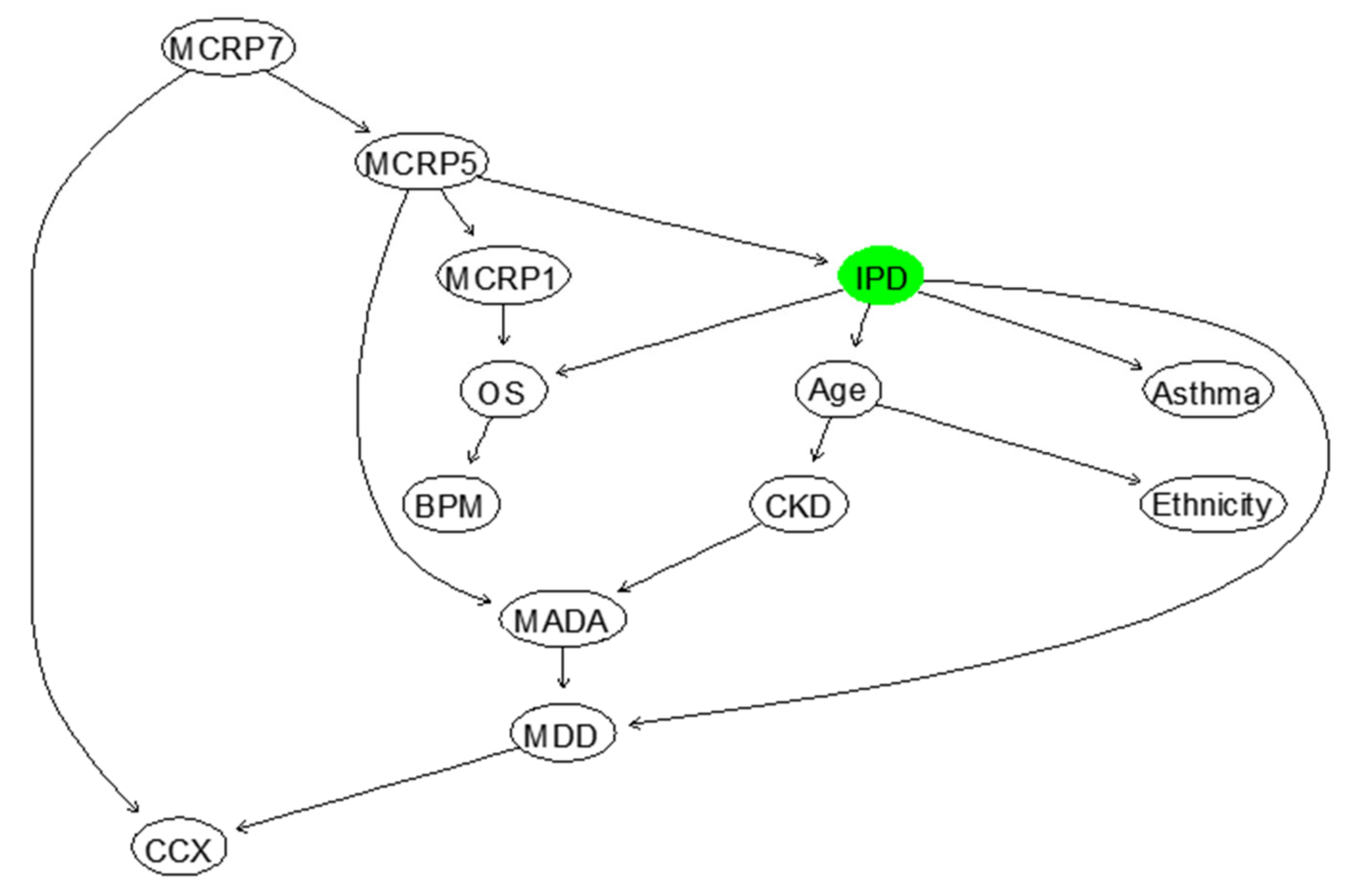
Based on the BN model shown in
Figure 7, the probabilities of IPD and survival of COVID-19 inpatients at different age groups can be computed, as shown in
Supplementary Table S3. It highlights that the death rate of COVID-19 patients with ≥70 years is five times larger than patients’ with ≤40 years. These probabilities can be updated by observing more evidence about the states of other influencing variables.
Table 3 shows the conditional probabilities of IPD given MADA (1 = <30, 2 = 30–35, 3 = 35<), MCRP7 (1 = <50, 2 = 51–100, 3 = 100<), and Age in years (1 = <40, 2 = 40–70, 3 = 70<). It can be concluded that for the patients in the first age group (<40 years) if the MADA is above 35 g/L, they will survive COVID-19 regardless of MCRP7. For a patient in this age group and with the MADA level less than 30 g/L, they would more likely survive if their MCRP7 were less than 50 mg/L. This means that when the MADA level is less than 30 g/L, patients are at a particularly high risk, especially if their MCRP7 level is above 50 mg/L. Interestingly, similar patterns can be found for the patients aged > 70 years old, but the corresponding survival probabilities are considerably lower.
Overall, these results indicate how low albumin (reflective of malnourishment, as well as infection owing to its negative acute phase protein property), high CRP, and old age correlate with inpatient mortality in an additive manner.
Oxygen Saturations (OS) at the time of presentation with COVID-19 were also associated with mortality. As OS decreases from >92% to <92%, the risk of mortality increases by 2%, suggesting that there is a negative association between these two variables, as shown in
Supplementary Table S4. We expected this association to be stronger, but found it difficult to measure the oxygen saturations during admission at any other time, or as an average, as it would be heavily affected by the level of oxygen therapy being received by the patient. Although these findings are useful, it is also fascinating to observe how OS could jointly, with other influencing independent variables, affect the risk of inpatient mortality, as shown below in
Table 4, where OS in % (2 = <91, 1 = 92<), CCX (1 = ‘No’, 2 = ‘Yes’), Ethnicity (1 = ‘Caucasian’, 2 = ‘Non-Caucasian’), and Age in years (1 = <40, 3 = 70<). The illustrated results in this table suggest that the risk of inpatient mortality is elevated for patients with reduced oxygen saturations and older patients. Ethnicity seems to increase the risk of death in patients 70< years, which is concordant with surrounding literature [
3]; however, the results were not true for younger patients. This may have been due to a skewed population demographic, whereby older patients tended to be Caucasian and younger patients reflected a more multicultural demographic. Changes on chest X-ray (CCX) did not seem to significantly affect the risk of IPD, perhaps because the presence of changes is more likely an indicator of the time-point that an individual is along in their COVID-19 infection rather than an indicator of severity.
The next important research question is how the trend in CRP levels during the clinical course of a COVID-19 infection can be incorporated and evaluated using an appropriate model. This is because CRP levels can often correlate with infection severity, with a small associated lag time. Therefore, the trend in CRP is clinically useful for predicting what will happen to the patient. For example, if the gradient between the latest two CRP variables were positive, it would indicate that the infection is getting worse, whereas if the gradient were negative, it would indicate infection resolution. To account for the gradient between the CRPs, a dynamic version of BN needs to be developed, which is not possible due to the lack of training data. However, the BN model, illustrated in
Figure 7, can be used to compute the risk of inpatient mortality for different levels of CRP at the different days during the clinical course of COVID-19 infection, as shown below in
Table 5. This table shows the conditional probability of IPD given different configurations of Mean CRP between days 1–2 since clinical COVID-19 presentation (MCRP1) (1 = <30, 2 = 31–100, 3 = 100<) and Mean CRP between days 7–8 since clinical COVID-19 presentation (MCRP7) (1 = <50, 2 = 50–100, 3 = 100<), Age in years (1 = <40, 3 = 70<) and Minimum Albumin During Admission (MADA) (1 = <30, 2 = 30–35, 3 = 35<). As shown, if the level of MADA is 35<, increases or decreases in CRP levels during the clinical course of COVID-19 infection will not impose a mortality risk in patients <40 years. However, in patients aged 70< years, any increase in CRP levels (mg/L) from days 1–2 to days 7–8, would significantly increase mortality risk.
Table 6 below indicates the promising Positive Predictive Value (PPV), Negative Predictive Value (NPV), Sensitivity, Specificity, Overall accuracy and F-Score, which are used to evaluate the predictive performance of the BN suggested to model IPD in
Figure 7, in terms of the feature selected risk factors. The definitions and details of how these metrics can be computed are described in [
35]. F1 Score is the Harmonic Mean between precision and recall. The F1 score (83.7%) and accuracy (84.1) of our BN model developed for IPD is high, despite the small dataset used to train and test our BN model. Eighty-two percent (PPV) of adult patients predicted to die as inpatients during clinical COVID-19 infection, by our model, will die. However, only 67.86% (NPV) of adult COVID-19 patients predicted to survive the inpatient admission will indeed survive. This indicates that our model may fail to predict inpatient death of a sub-set of adult COVID-19 patients, but we expect this to improve with a larger dataset, which also incorporates more variables such as socioeconomic factors.
3.2. Duration of Inpatient Treatment for COVID-19 (ADT)
Understanding the simultaneous impact of MADA, obesity, and MCRP1 on the duration of COVID-19 treatment in patients is increasingly important to manage the growing, unrelenting pressures on hospitals and the NHS.
Table 7 shows the probabilities of several important queries computed from the learned BN. In this table, ADT categories are ‘1’ (<1 day), ‘2’ (>2 days but < 3 days) and ‘3’ (>3 days). MCRP1 has been divided into 3 categories: ‘1’ (<50), ‘2’ (51–100) and ‘3’ (>100), and MADA has been divided into 3 categories: ‘1’ (<30), ‘2’ (30–35) and ‘3’ (>35). As is evident from this table, the duration of treatment of 71% of non-obese COVID-19 patients with normal MADA levels (>35 g/L) and low MCRP1 (<30 mg/L) is up to 1 day. In addition, the treatment duration of 95% of the patients with the above characteristics would be less than 3 days. In comparison to the obese patients, it can be observed that this probability (i.e., probability that the duration of treatment is up to one day) will be reduced to 54.4% (with the same characteristics). On the other hand, the predicted probabilities for duration of treatment of the obese and non-obese patients, with very low levels of MADA (<30 g/L), regardless of levels of MCRP1, are not significantly different from each other. Furthermore, the model and results reported in
Table 7 suggest that the levels of MCRP1 alone would not be adequate to accurately predict the probabilities of treatment duration of more than 3 days. These probabilities must be updated by adding more evidence about the levels of MCRP at other days. It would be straightforward to revise and update the BN by augmenting the other outcomes, for example “IPD”, to understand what proportion of patients with a treatment duration <3 days may not survive. Overall, it can be observed that the COVID-19 treatment duration is higher for obese patients with high CRP levels and low Albumin levels.
Several metrics to assess the predictive performance of the proposed BN for the three different categories of ADT are shown in
Table 8.
The computed sensitivity measures, which is the metric to evaluate the learned BN ability to predict true positives of each available category of ADT, suggest that “ADT > 3” days has the highest rate (77%), and ‘2 ≤ ADT < 3^’ days has the lowest sensitivity rate (41.4%). We also compute specificity, which is the metric to evaluate the fitted BN ability to predict true negatives of each ADT category. The results suggest “ADT < 1” days (83.5%) and “ADT > 3” days are the categories with the highest and lowest specificity rates, respectively. The next important metric is F1-score that can be interpreted as a weighted average of the precision and sensitivity values, where an F1 score reaches its best value at 1 and worst value at 0. Since, the F1-score takes both false positives and false negatives into account; it will be usually more useful than accuracy, especially if the original test dataset has an uneven class distribution. The computed F1-scores for the ADT categories suggest promising accuracy for ‘ADT < 1’ days and ‘ADT > 3’ days.
3.3. Max Oxygen or Ventilatory Support (MOoVS)
It is of great important to understand how the right level of oxygen therapy or ventilatory support should be selected to enhance the survival rate and recovery speed of COVID-19 patients.
Table 9 shows the conditional probabilities (as heat-mapped) of Max Oxygen or Ventilatory Support (MOoVS) given the different configurations of MADA (1 = ‘<30’, 2 = ‘30–35’, 3 = ‘35<’), OS (‘1’ = >92 and ‘2’ < 92) and MCRP11 (1 = <100 and 2 = >100).
Patients either required no high-flow oxygen (NHF), high-flow oxygen (HF), CPAP/NIV (CPN) or ITU admission (ITU). The illustrated results in this table suggest that most of the patients with the better health characteristics such as high MADA (>35 g/L), high OS (≥92%), and low MCRP11 (≤100 mg/L) are likely to only require no-high flow O2 (73%) or high flow O2 (12.5%). These patients are thus suitable for ward-based care and will not need ITU admission. On the contrary, when MADA and OS levels, respectively, drop to below 30 g/L and 91%, and MCRP11 level increases to over 100 mg/L, the need is increased for these patients to receive CPAP/NIV (37%) or ITU admission (49%).
The probabilities given in
Table 9 can be significantly altered in the light of new evidence, such as patient age. The updated probabilities are shown below in
Table 10.
Table 10 shows the conditional probabilities (as heat-mapped,) of MOoVS given the different configurations of MADA, OS, MCRP11, and Age (1 = ‘<40 years’ and 3 = ‘>70 years’). As mentioned above, patients required either NHF, HF, CPN or ITU.
From this table, it can be concluded that all young patients with OS ≥ 92, MADA ≤ 30 and MCRP11 ≤ 100 require either NHF (80%) or HF (20%) to recover. If MADA levels of young patients increase to over 35 g/L, with the same levels of OS (≥92) and MCRP11 (<30), they will more likely need to use only NHF (93%) to recover. However, if the health of the patients starts to deteriorate, as MADA and OS levels, respectively, drop to <30 g/L and <92%; and MCRP11 level increases to over 100 mg/L, their need for HF, CPAP/NIV (CPN) or ITU will significantly increase depending to the age of patient. For the young patients, CPAP/NIV (36.5%) or ITU (63.5%) would be recommended. However, for patients > 70 years, either HF (22%) or CPAP/NIV (76%), and paradoxically not ITU (0%), would be recommended, usually because they are deemed unsuitable for ITU admission due to the futility of ITU-based treatment relative to a younger patient. This reflects the rationing of healthcare resources that occurs in hospitals after difficult medico-ethical decisions.
Table 11 illustrates several metrics to assess predictive performance of the proposed BN for the different states of “MOoVS”. The overall classification accuracy suggests that over 60% of cases have been correctly classified. Despite the small sample size of data and high percentages of missing values of the raw data, the computed overall accuracy (60.25%) is quite promising. The ability to predict true positives of each available category of MOoVS is measured by Recall, or Sensitivity, which suggests ITU admission has the highest rate (89%), and “CPN” has the lowest sensitivity rate (36%). We also compute specificity, whereby “CPN” (91%) and ITU admission (73%) are the categories with the highest and lowest rates, respectively. Since the original raw data has an uneven class distribution, F1-score as a weighted average of the precision and sensitivity values were calculated.
3.4. New Confirmed Pulmonary Embolism during Admission (NCPE)
Understanding the influence of various independent variables upon the conditional probability of having an NCPE is important for clinicians in guiding their use of thromboprophylaxis within the context of COVID-19. Our results confirmed that having bilateral COVID-19 changes on CT scan can increase the risk of NCPE from 13.9% to 72.4%. This suggests that more extensive ground-glass or consolidative changes on CT scan secondary to COVID-19 may be associated with NCPE secondary to COVID-19. Another well-known key predictor variable is the maximum D-dimer during admission (MDD), which is often an indicator of thrombosis. Our results indicated that having an MDD of 400<, as opposed to <400, increases the risk of NCPE from 34.6% to 54.5%. Interestingly, NCPE appeared to be more significantly influenced by the presence of MADA < 30 or bilateral ground-glass or consolidative CT scan changes secondary to COVID-19, rather than levels of MDD, as shown below in
Table 12. This may be explained by the fact that many other conditions can also increase D-Dimer, such as disseminated intravascular coagulation, deep vein thrombosis and infection, which could thus be leading to high rates of PE false positives amongst COVID-19 patients. Furthermore, not all patients with raised D-dimers would have had CT-scans to investigate for PE, especially if it was deemed futile and the patient was palliative.
We finally investigated the impact of obesity alongside MADA and MCRP7 levels on NCPE in
Table 13. It can be concluded that there is a strong association (70%) between the presence of NCPE and MADA < 30, as well as MCRP7 > 100, for the non-obese patients. If the patient is obese, MADA < 30 seems to be more influential in contributing towards the risk of NCPE, as opposed to MCRP7 > 100.
Various metrics, including PPV, NPV, sensitivity, specificity, overall accuracy, and F-Score, have been used to evaluate the predictive performance of the BN created to model NCPE, as shown in
Table 14. The computed F1-score of almost 86% shows the classification prediction of the learned BN for NCPE is precise and robust. In addition, the PPV (83.7%), sensitivity (88%) and NPV (80.9%), which collectively represent the BN model’s ability to predict inpatient NCPE, was high.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}