1. Introduction
Predictive maintenance is the ability to use data-driven analytics to optimise the upkeep of capital equipment [
1]. Predictive maintenance bridges the gap between condition-based maintenance and corrective maintenance and is enabled by the advent of Industry 4.0 [
2]. Value is created by transforming the collected data from intelligent systems into predictions about the system’s health, so that maintenance can be done exactly when and where needed. Estimates of the impact of predictive maintenance vary widely, but in general the return of investment is deemed to be favourable [
3]. Despite the favourable return on investment, implementation of predictive maintenance in practice is still limited in many industries [
4,
5].
Furthermore, predictive maintenance is a key enabling technology for servitisation in smart industries. Servitisation is an emerging trend [
6] in which organisations and citizens no longer own their assets, but rather lease their services: companies buy hours on production machineries with a guaranteed throughput; people lease a car rather than buying one. As a consequence, servitisation mandates constant availability at a low cost, prescriptive (personalised) service, and full digitisation and automation of service provision.
Although the prospective benefits of predictive maintenance are tremendous, realising the envisioned benefits is far from trivial. While many core building blocks of predictive maintenance (such as sensor technology, failure prediction methods, and optimisation techniques) exist, current solutions focus on individual steps in the predictive maintenance cycle, and only work for very specific settings. The overarching challenge of predictive maintenance is to leverage these individual building blocks into an effective and efficient framework that supports optimal maintenance and asset management in a complex arena. The PrimaVera project picks up this challenge through a multidisciplinary team providing exactly these expertises.
This paper highlights two major elements of the project to synergise predictive maintenance. First, the challenges hindering the successful application of predictive maintenance have been identified and are presented in this paper. Secondly, this paper introduces a generic predictive maintenance process model which provides a structured approach for deploying new predictive maintenance solutions.
The PrimaVera project includes leading industrial partners from three major sectors of the Dutch economy: infrastructure, high-tech and maritime. The project has been awarded a grant of five million euros in funding from the Dutch Research Council (NWO) and co-funding from the participating consortium members. The project has a duration of five years.
The rest of this paper is organised as follows.
Section 2 presents the state of the art of each of the six elements compromising predictive maintenance. Based on the state of the art, the PrimaVera project has identified four obstacles to overcome in order to utilise predictive maintenance to its full potential. These obstacles are described in
Section 3,
Section 4 outlines the generic process model to tackle these obstacles. Furthermore,
Section 4 describes the research approach taken for each step of the process model.
Section 5 details the methodology used during the project together with a brief overview of the intended demonstrators.
Section 6 details the constituents of the consortium and finally, the last section contains the conclusion.
2. State of the Art
Predictive maintenance entails six steps; data acquisition, data processing and diagnostics, prognostics, optimisation of maintenance and logistics, asset management, and human and organisational factors. This section will outline the state of the art of each step. Later on asset management and human and organisational factors are considered as one step as these two steps are closely related.
2.1. Data Acquisition
Predictive maintenance or condition monitoring that goes beyond the visual inspections by a human inspector is always data-driven. The most rudimentary form of data-driven maintenance would be the analyses of log files and error messages [
7]. A next level is using specific sensing methods, e.g., vibrational frequency measurements at bearings [
8], to assess the health of components. More advanced methods include real-time monitoring which can raise an alarm based on predefined criteria. Taking it further, machine learning and big data analysis of sensor data are being researched [
9].
In practice, many companies struggle to incorporate data-driven workflows within their company [
4,
5]. First of all, there may be no data, incomplete data, erroneous data, unaligned data or simply not enough data. Logging of errors may be incomplete or data are not stored at all. To apply the power of machine learning techniques to identify patterns, large amounts of data are needed, which means longer periods of time need to be measured. Secondly, data ownership is an issue. Even though machines log data, there is no access to the data, data are too costly or is owned by another company [
10]. Thirdly, data are not labelled [
10] or is labelled inconsistently. Operators use different nomenclature or report all malfunctions under the same generic error code. That makes it difficult to learn within a single company, let alone to learn from (the data of) ‘peer’ companies.
What is needed is a structured approach to gather data in a goal-oriented way. The cross-industry standard process for data mining (CRISP-DM) [
11] is a good starting point, but it describes common approaches. Therefore, specialisation towards specific predictive maintenance problems or domains may be valuable. Given an objective, knowing what to measure is a challenge, knowing how to measure is even more challenging.
To overcome this challenge decision support tools which aid in the selection of an optimal sensor strategy can be used. For instance, optimal sensor placement can be found by genetic algorithms [
12] or by using finite element models [
13]. Sensor costs is another factor which can be optimised [
14]. Other elements an optimal sensing strategy decision support tool should take into account are costs of asset/component replacement, expected faults and required accuracy of the condition monitoring system. Another factor the decision support tool should take into account is the goal of monitoring, for instance wear or fatigue. To our knowledge no research has been done into designing an overarching and unifying optimal sensing strategy decision support tool.
Moreover, novel measuring technologies may appear which we are not even aware of. For instance, sensors on train axle boxes to enable the monitoring of insulated rail junctions [
15]. Or mobile phones of commuters could be used, so-called participatory sensing [
16]. For instance, mobile phones have been successfully used to monitor road conditions [
17]. So new sensing technologies may show up for predictive maintenance as well.
We see three main opportunities, i.e., challenges for data acquisition in predictive maintenance. First, the use of sensor fusion, in particular the combination of remote sensing (lidar, satellite, radar, sound-arrays, etc.) with in-situ sensors [
18]. Sensor fusion may compensate for data gaps of a single sensor, leading to new sensing approaches by combining sensors at different distances. Second, the automatic context detection of sensor data. For instance, a bridge is supposed to expand during hot weather, but if the same expansion happens during cold weather this could indicate an anomaly. The challenge is to automatically detect the context (situational awareness). Third, methods for effective cross-company data interoperability are lacking [
19]. These methods make it possible to enlarge data sets to get the size needed for machine learning. In particular this includes the definition of data quality: which quality of data is needed for which decision and how do we define this quality?
2.2. Data Processing and Diagnostics
Automated data validation and correction for predictive maintenance requires methods that work under realistic assumptions. Within statistics and machine learning, many different techniques have been developed for dealing with missing data [
20,
21,
22]. Most existing techniques rely on the missing completely at random (MCAR) assumption, which does not apply to the typical sensor data relevant for predictive maintenance. Recent approaches based on Gaussian copulas [
23,
24] can at least handle the missing at random (MAR) assumption, in which whether or not a data point is missing may depend on the values of other variables. A key challenge is to develop techniques that can further relax these assumptions and efficiently handle streaming big data, while at the same time identifying and correcting for outliers. Missing value imputation methods based on low-rank matrix completion such as [
25,
26] provide a good starting point: they are computationally efficient and their implicit projection of high-dimensional data into a lower-dimensional space naturally facilitates the robust detection of outliers [
27,
28].
Monitoring is an essential part of condition based maintenance, since monitoring the condition of systems allows the early identification of imminent failures. Current monitoring methods are not yet suitable for automated use, since they fail when there is no labelled training data, cannot handle high-dimensional data streams, do not adapt to data arriving at different time scales or do not take into account internal dependencies [
29] and are not capable of making use of physical models. Regression-based monitoring methods have recently been extended to obtain adaptive detection thresholds in high-dimensional settings [
30]. A first attempt to develop self-starting regression-based monitoring methods that do not required labelled training data has been presented in [
31]. Purely statistical approaches have the advantage of providing performance guarantees, but they are difficult to automate. A promising recent approach to overcome this, is to use deep learning to correct for internal dependencies and use statistical approaches for monitoring [
32]. The PrimaVera project will build upon these approaches by developing automated approaches with guaranteed performance that work in realistic industrial settings. In addition to these data-driven condition monitoring techniques, also more physics-based structural health monitoring techniques will be developed. These techniques typically utilise the dynamic response of systems and structures (e.g., vibrations) to detect and assess the presence, location and severity of damage [
33].
To successfully design maintenance interventions, it is essential to understand why systems fail. The rapidly growing field of causal inference (see, e.g., the recent bestseller [
34]) here may provide a solution. So-called transfer entropy [
35] can be used to estimate the directed transfer of information between the time series of two variables, e.g., from sensors at different parts of a lithographic machine [
36]. Causal discovery methods [
37,
38] aim to unravel the causal structure underlying the interactions between many different variables from purely observational data. From a methodological point of view, a key challenge is to integrate these two approaches to go from pairwise measures of causal information flow to a graphical structure that can be efficiently queried to find the root causes of specific failures.
Whereas causal inference has been successfully applied in various scientific domains (e.g., climate research [
39], neuroscience [
40], proteomics [
41], psychology [
42]), its application in industrial settings is largely unprecedented. A methodological challenge here is to estimate transfer entropy in industrial settings.
2.3. Prognostics
The aim of prognostics is to develop accurate algorithms to predict the future failures of components and systems. The prognostics step follows the data processing step and quantifies relevant key performance indicators (KPI), such as the remaining useful life (RUL), time to first failure, availability and reliability. Although a lot of research has already been done in this field, still several major challenges remain. The first challenge is the gap between component and system level. Most of the methods available in literature predict failures on a component level, e.g., for bearings [
43], rail [
44] or vehicle tracks [
45]. However, asset owners are interested in the availability and expected failure of the complete system [
46]. As developing separate models for all components in a system still takes too much time and effort, solutions have to be found in either predicting system level failures from only a limited number of (critical) component models, or in speeding up the component model development process. In the former case, the selection of these critical components, especially for large and complex systems, is not trivial and requires attention. The second challenge is that many predictive models heavily depend on a large and complete set of failure data. As for well-maintained critical systems failures are by definition rare, such data sets are often not available. This means that data-driven models must be combined with domain knowledge or physics-based prognostic methods [
47]. This relates to the third challenge: only a small number of experts possess detailed knowledge on the failure behaviour of components, which is also very application-specific. This makes it difficult to incorporate that knowledge in generic prognostics tools. Automation of the failure or root cause analysis would make this knowledge more accessible. The fourth challenge in prognostics is that actual application of the methods proposed in scientific literature in industrial practice appears to be rather limited [
48]. The main reason is that companies struggle to determine which approach fits with their ambition and their data and knowledge maturity. The final challenge is human factor related: engineers are typically reluctant to adopt advice or predictions from ‘black box’ prognostic tools. Especially fully data-driven and AI-based methods are hard to comprehend. Adding explainability [
49] to these kind of methods might assist in increasing trust in the predictions. To summarise, prognostic methods are still considered to have high potential in predictive maintenance, but wide application in industry is still hindered by both technical and organisational challenges.
2.4. Maintenance and Logistics Optimisation
The easiest way to plan maintenance is to perform it upon failure, i.e., perform corrective maintenance. However, this leads to many failures and high downtime. For decades now, most organisations have used some form of preventive maintenance: periodic maintenance. Maintenance is then triggered by, for example, running time, calendar time or number of take-offs of an aeroplane. The first models were proposed over 60 years ago by Barlow and Hunter [
50]. Nowadays, predictive maintenance is an emerging trend.
For predictive maintenance, information is used that results from data acquisition, data processing and diagnostics, and prognostics, such as RUL estimates or failure probabilities. Typically, as asset gets older, the RUL estimate goes down and the failure probability goes up. If these estimates would be perfect, maintenance could be performed exactly before breakdown. However, estimates are imperfect and an economic trade-off needs to be made. Performing preventive maintenance too early leads to unnecessary down-time. Performing preventive maintenance too late leads to corrective maintenance, which is typically much more costly since the maintenance has to be performed under high time pressure, leading to high logistics costs to get a service engineer with the right parts and tools at the asset. Furthermore, downtime of a critical component causes the complete asset to be down, which implies high downtime costs for its owner. This means that there is an economically optimal moment to perform maintenance that incorporates these costs and the probability of failure or RUL estimate. This optimisation is further complicated because assets contain many (critical) components, and grouping maintenance leads to fewer disruptions for the customer and lower logistics costs.
Because it is of key importance to perform maintenance at the right time, there has been a lot of research on making optimal predictive maintenance decisions(for recent reviews, see, e.g., [
5,
51]). However, most of the research has been on single-item problems (i.e., one type of component). Exceptions, so papers focusing on multi-item problems, are those of Zhu [
52] and Arts and Basten [
53]. There has been some research on integrating maintenance and the service logistics needed to have the right parts, people, and tools available at the moment maintenance is planned [
54,
55] and on the usage of condition monitoring information to adapt operations [
56]. Further integration of the topics of operations, maintenance, and service logistics is required. Another trending research area is making decisions with limited information. Since the prognostics and other information are often far from perfect, models and decision making need to take these imperfections into account. One way to do that is by modelling problems with partially observable Markov decision processes [
57]. Such models are often hard to solve, but research on solving such models is ongoing [
58].
2.5. Asset Management and Organisational Factors
Predictive maintenance is an active research area that has seen significant progress over the past decade, both in industry and in academia. Progress is much related to advancements in the area of big data analytics [
59]. While many core building blocks of predictive maintenance (such as sensor technology, failure prediction methods, and optimisation techniques) exist, current solutions focus on individual steps in the predictive maintenance cycle and only work for very specific settings as discussed in the introductory chapter of this paper. Developing advanced maintenance techniques is therefore only useful if they are well integrated into an organisation [
60].
A quote of a Maintenance Engineer at the Netherlands Railways who recently studied the use of predictive strategies illustrates these organisational challenges:
“Preventive water filling based on real-time water level data and a predictive model seems to be an appropriate maintenance strategy; however, this requires the dynamic usage of human resources and filling stations … Trains move, making the logistic puzzle more complicated … Our overall goal is to maximise the availability of trains with functioning toilets in a cost-effective way.”
Traditionally organisational aspects regarding the implementation of data-driven maintenance have been mentioned by other authors and have often been neglected [
48,
60,
61,
62,
63]. Therefore, the PrimaVera project specifically studies the impact of data-driven maintenance on organisational processes where data-driven maintenance is being introduced. Procedures for the effective implementation of data-driven maintenance systems within organisations need to be designed in a timely way to allow effective use of its predictions in operational maintenance planning processes.
Furthermore, earlier research shows that the implementation of predictive maintenance should include ambition levels, available data [
64] and a fit of predictive maintenance with the organisational maturity of the organisation [
60]. The following organisational interfaces have been identified by [
60]: strategy and goals, decisions, structure, budget and capacity, and documentation. It can be debated that early integrated decision making is needed to evaluate the impact on these interfaces.
Because asset management is a multi-disciplinary discipline, the organisational impacts expected by the introduction of data-driven maintenance systems on the aforementioned interfaces should therefore be approached from multiple perspectives. The perspectives mentioned by [
65], e.g., technical, economic, commercial, compliance, and organisational aspects seem relevant to be used here, especially because asset management aspects are rarely limited to a one-dimensional perspective.
The most critical organisational impacts should therefore ideally be identified and assessed before the introduction of data-driven maintenance by studying the use of the aforementioned perspectives in this specific asset management area. Because of the complexity of the associated systems, processes, and people there will always remain a number of organisational decisions that need to be identified and addressed before data-driven maintenance of individual components can actually be implemented. As [
66] pointed out there are always trade-offs between maintenance costs, availability and efficiency in (multi-component) systems.
It can be argued based on the outcomes of the work of Koochaki [
66] that organisational processes need to become more flexible to make data-driven maintenance on a multi-component system more feasible. Therefore, the PrimaVera project will also investigate how organisational readiness and resilience in processes can be developed before or during the introduction of these systems. The use of high-reliability theory and anti-fragility in organisations can be seen as emerging fields [
67] besides the needed attention for cultural aspects [
60].
For the development of appropriate decision making support tools an iterative design science research (DSR) approach [
68] is envisioned in which artefacts are iteratively evaluated and improved. A DSR strategy focuses on developing artefacts as well as knowledge creation, and aims to produce improvements based on a thorough understanding of problems or opportunities [
68]. Therefore, the outcome of DSR is not only relevant to the practical application domain, but is also explicitly aimed at the creation of theoretical knowledge [
69].
2.6. Human Factors
Human beings are critical to the functioning and performance of the majority of operating systems. However, human behaviour traditionally has been ignored in the field of operation management (OM). That is, most models in OM assume that agents who participate in operating processes are either fully rational or can be induced to behave rationally [
70,
71]. More specifically, these models assume that people have stable preferences, are not affected by cognitive biases or emotions, and have the ability to disregard irrelevant information by only responding to relevant information when making decisions [
72]. The emerging field of Behavioural Operations Management departs from these (rather unrealistic) assumptions by acknowledging that human decision-makers are guided by emotions, cognitive biases or irrelevant situational cues that may affect the adoption and usage of operating systems [
73]. More specifically, transforming maintenance systems and operations into ones that rely on data-driven technologies bring many challenges. One important challenge concerns the design of (data-driven) maintenance systems that organisational members are willing to trust and use [
74,
75]. That is, in order to successfully integrate these promising technologies into organisations, it is of critical importance to understand when and why users are hesitant to adopt these new technologies in their daily working routine and how we can stimulate its effective usage. As such, the goal and novelty of PrimaVera is to develop key insights into (i) what factors impacts a person’s acceptance and use of data-driven failure predictions and maintenance recommendations and (ii) how to effectively combine human judgement with the solution of a system. These insights will be used to design novel, user-centred maintenance tools that make the user–system interaction more effective and efficient.
3. Obstacles to Overcome
To reap the fruits of predictive maintenance and leverage individual building blocks into an effective solution, the PrimaVera project has identified four cross-cutting obstacles that need to be overcome. These obstacles have been established based on our own expert interviews from people within academia and industry and are backed by recent insights from major consultancy firms [
76,
77]. The obstacles that thus far have hindered effective solutions are lack of orchestration, lack of automation, data uncertainty and the role of human and organisational factors. The justification of these obstacles is supported by an empirical Delphi-based scenario planning study conducted within the area of maintenance in digitalised manufacturing [
78]. Each of these obstacles are detailed in the following sections.
3.1. Orchestration
Current predictive maintenance solutions often focus on a single step in the predictive maintenance chain, with poor alignment to the rest of the workflow. This is suboptimal, since locally optimal solutions do not usually lead to overall optimal solutions. Thus, effective maintenance requires novel optimisation techniques that work across different aggregation levels. In particular, asset management involves supply chain optimisation, orchestrating the planning of maintenance personnel, equipment and groups of assets.
Bokrantz et al. envision that effective maintenance will lead to optimised performance of entire manufacturing systems [
78]. To achieve this the challenge is to develop methods and algorithms which are useful in practice [
78]. Implementing predictive maintenance solutions which focus on a single failure mode are non-optimal, solutions must be implemented which consider the interaction of components with their operating environment [
79]. Kipper et al. suggest that researchers need to develop studies to improve the understanding of how Industry 4.0 technologies and concepts impact processes, products and services [
80].
3.2. Automation
Current applications of predictive maintenance usually consist of a large number of non-automated procedures. This is not only inefficient, but also error prone. Automating these steps into systematic procedures is challenging, because they involve a wealth of domain knowledge. In particular, accurate, scalable and robust algorithms for data cleaning, causal discovery of failures and root cause analysis are currently lacking, and the same holds for prediction algorithms for software and electronics, as well as for algorithms to optimise the supply chain logistics.
Bokrantz et al. underline this obstacle by noting that developing maintenance management systems that automatically transform big data into decision support is still challenging [
78]. Kipper et al. recommends future research should be carried out in order to develop frameworks for deploying Industry 4.0 in real applications, such as predictive maintenance, not only in large companies but also in Small Medium Enterprises (SMEs) [
80].
3.3. Data Uncertainty
Data from sensors or other sources is often inaccurate or incomplete. Obtaining accurate prognostics and maintenance decisions despite imperfect and uncertain data requires sophisticated methods that are capable of handling real world uncertainties [
81]. Since uncertainties propagate along the predictive maintenance workflow, these techniques play a role in each step of the predictive maintenance cycle. Methods which evaluate the effectiveness and accuracy of predictive maintenance solutions with regards to uncertainty are required [
81].
3.4. Human and Organisational Factors
The transition towards the Industry 4.0 requires organisations to embed the data-driven culture into their workflow. A key issue is the trust in data-driven decision support tools: maintenance decisions that are automatically computed by tools must be acted upon by maintenance engineers. This requires a user-centric design of these decision support tools. In addition, the project team responsible for successfully deploying a predictive maintenance solution is often confronted with reluctance and reservations [
10]. The lack of communication between between theory developers and practitioners in the area of reliability and maintenance is also an issue [
82].
Besides the right presentation of information, the right process information needs to be made available at the right moment to allow data-driven maintenance activities. Often there is limited information available on expected organisational impacts of data-driven maintenance actions.
4. Predictive Maintenance Process Model
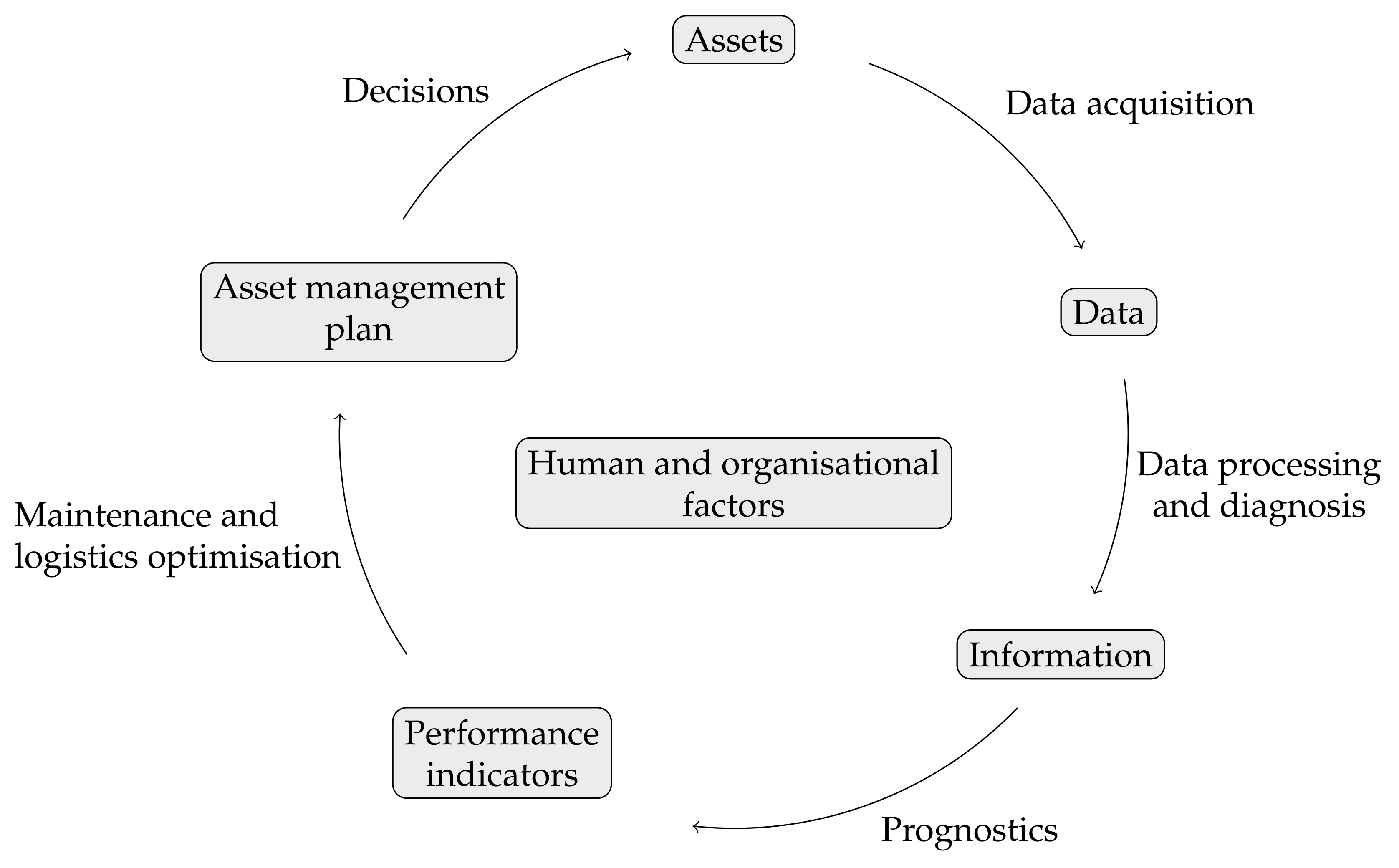
To overcome the before mentioned obstacles and to orchestrate the different steps in the predictive maintenance workflow a generic applicable process model is proposed to facilitate this (
Figure 1). The proposed model is similar to existing models [
83,
84,
85,
86,
87], which are in essence all based on the generic model of Jardine et al. [
82]. The model of Jardine et al. has three distinct stages; data acquisition, data processing and maintenance decision-making. As the goal is to define a generically applicable process model for predictive maintenance, not only should it be applicable at system level but also at fleet level [
88,
89]. To ensure this genericity, the proposed model will also be based on the generic model of Jardine et al. To highlight the significance of diagnostics and prognostics within predictive maintenance, the proposed model explicitly breaks down the data processing step into these two elements. The importance of human and organisation factors is commonly overlooked by engineering disciplines [
48,
61,
62,
63] but is well rooted within information systems research [
90,
91]. Technology and behaviour are not dichotomous [
90], therefore human and organisational factors have been added to the proposed model. This element is placed at the very centre of the model as it affects all other stages of the model. It is exactly this addition which sets the proposed model apart from the previously proposed models. The usability and applicability of the proposed model will be evaluated by applying it to the demonstrators described in
Section 5.1.
The generic model consists of five stages: (1) data are acquired from assets using sensors or other sources, (2) these data are then processed and turned into meaningful diagnostic information through data selection, cleaning and interpretation, (3) from this information predictions are made about the system’s health (prognostics), (4) based on these prognostics, maintenance and associated logistics are optimised, (5) all information has to be incorporated into a strategic asset management plan. Decisions listed in the asset management plan are transformed into actions which will affect the asset being managed, hence closing the cycle. An asset management plan documents the activities, resources and timescales required to achieve the organisation’s asset management objectives for an individual asset or group of assets [
92]. Note that each of the stages relate to one or more of the before mentioned obstacles of predictive maintenance to overcome.
The starting point within the predictive maintenance cycle depends on the motivation for asset management [
93]. This motivation can be initiated by a technology push; existing technology is available which needs to be management, in this case the cycle would start with data acquisition. On the other hand motivation can be initiated by a decision pull; there is a certain economic necessity, in this case the cycle would start with an asset management plan.
4.1. PrimaVera Approach
The subsequent sections will focus on each individual stage of the proposed process model and will describe the envisaged scientific outcome for this stage. Once again it should be stressed that the project’s main endeavour is to enrol a holistic, cross-sectoral approach, thus explicitly addressing the observed obstacle of a lack of orchestration.
4.1.1. Data Acquisition
In practical settings selection of suitable sensors for implementing a predictive maintenance solution pose a challenge [
10]. To overcome this, a decision support tool will be realised that advises on the most appropriate sensing techniques, spatial sensor placement and optimal sensing strategy to monitor an asset. Though there is a lot of work on optimal sensor placement [
12,
13,
94], an overarching decision support tool which takes all facets of predictive maintenance into account is still lacking. Input to such a decision support tool will include critical components together with their failure modes, required accuracy and resolution, cost factors and expert domain knowledge. Implementing an optimal sensing strategy will aid in the mitigation of data uncertainty.
One of the case studies being analysed in the PrimaVera project is a sludge dredger’s propulsion system. A limited amount of recorded failure data is available of this system, only eight clearly labelled eminent failures are present. In order to obtain accurate prognostic models, more failure data are required. Therefore, various methods to acquire more failure data will be evaluated. First method is a model based approach to gather more failure data. A computational white box model is created based on a qualitative functional decomposition of the system. Second method is the use of a scaled physical model of a propulsion systems which purposefully has damaged components installed such as faulty bearings. Third method is the use of public available data sets from similar systems such as the Machinery Fault Database [
95] to evaluate the feasibility of transfer learning. Transfer learning allows the domains, tasks and distributions to be different for training and testing [
96].
4.1.2. Data Processing and Diagnostics
Novel automated methods for real-time data validation and correction will be developed, building upon probabilistic and statistical techniques for missing value imputation [
25,
26] and outlier detection [
28]. Development of these methods is done under realistic assumptions reflecting the industrial practice. This implies that methods should be able to handle high-dimensional data streams, mixed sampling frequencies, guarantee performance and should take internal dependencies into account [
29]. Furthermore, care will be taken to incorporate effects of changing operational conditions on the measurements, as these are directly affecting failure rates, and separate them from the direct effects caused by failures.
Since uncertainties propagate along the predictive maintenance workflow, these techniques play a crucial role at the beginning of the predictive maintenance cycle. Since it is impossible to eliminate uncertainty, it is better to acknowledge uncertainty and quantify it [
97]. Uncertainty is a quantitative indication of the quality of the result, it allows decision makers to assess the reliability of predictive maintenance process outcomes [
98]. The PrimaVera project will explore methods, such as fuzzy sets [
98], Bayesian approach [
97] or Dempster–Shafer theory [
99], to quantify uncertainty throughout the predictive maintenance workflow. This will contribute to overcoming the data uncertainty obstacle.
A key step in failure prevention is to understand why systems fail. While data-driven techniques are good at finding correlations between failure modes, finding causal relations is challenging. Causal inference graphs can be efficiently queried to find the root causes of specific failures [
100,
101]. The PrimaVera project will propose a framework to construct these causal inference graphs and extend them to perform in an industrial setting. The framework will build on the advantages of Bayesian networks [
102,
103], Granger causality [
104] and transfer entropy [
35,
105].
4.1.3. Prognostics
A key innovation of the PrimaVera project is to leverage the two most prominent classes of prognostic algorithms: data-driven and model-based methods.
Data-driven approaches, based on advanced data analytics [
106,
107], are fast and fully automatic. However, they require large amounts of data and, as black box methods, their outcomes are difficult to understand and interpret.
Model-based approaches are based on knowledge on the physics of failure [
108,
109]. They are created using domain knowledge, which typically is rather time consuming. Their main advantage is that they give insight in why systems fail, and how these failures are related to (changes in) operating conditions. By combining data-driven and model based approaches, PrimaVera aims to obtain the best of both worlds: automatic, versatile and understandable prognostic methods.
In particular, we plan to develop model learning techniques to automatically derive appropriate models from empirical data sets—initial results for learning fault tree models appeared in [
110,
111]. Further, as data are often incomplete, domain knowledge can be incorporated to define the initial structure of the model. Further, data analytics will be utilised to determine the model parameters in traditional physical prognostic models, like fatigue crack growth and corrosion models, from data collected on real systems. The other way around, simulations with physical models will be used to generate additional data in cases where real data sets are too limited for machine learning applications. These hybrid prognostic methods will result in considerably more accurate and efficient methods.
As many failures of today’s systems are caused by software rather than hardware, the project will also work on predicting software failures. Again, a hybrid approach will be adopted, leveraging model-based software reliability techniques (e.g., reliability growth models [
112], software metrics [
113]) with data-driven techniques (e.g., observed failure times [
114], mining the characteristics of software failures [
115]).
4.1.4. Maintenance and Logistics Optimisation
Because data uncertainty is one of the obstacles to overcome, the project will deliver models and methods for maintenance optimisation under partial observability, i.e., when most of the inputs have high uncertainty. The project will work both on modelling and optimising problems from practice using partially observable Markov decision processes [
57] and on solving such models quickly [
58].
As a next step, to improve orchestration, the project will work on integrating large-scale robust maintenance optimisation and service logistics (spare parts inventory) control at asset and fleet level. The link between maintenance optimisation and service logistics control has recently been receiving considerable attention [
54,
55,
116], as maintenance is unrealisable when spare parts are unavailable and spare parts are useless if no maintenance is performed. As such, integrating the two objectives through multi-level optimisation is expected to significantly lower costs, as the solutions to the independent optimisation problems do not lead to a global optimum. The integration of these two objectives is a highly complex and computational expensive task. In order to move towards a fully integrated maintenance optimisation and service logistic framework a hybrid approach is adopted combining elements from the fields of stochastic operations research, such as spare parts inventory theory [
117], and machine learning or artificial intelligence.
4.1.5. Decisions
Decisions arising from the asset management plan need to consider organisational and human factors. Transforming traditional maintenance procedures into ones that rely on advanced data-driven techniques bring many organisational challenges. One important challenge concerns the design of data-driven maintenance tools that organisational members trust and use [
118,
119,
120,
121]. That is, users on various levels often experience difficulties in trusting and using these systems and they therefore frequently deviate from its advice by relying on their own judgements [
122]. Further, to successfully integrate new technical solutions into organisations, it is of critical importance to understand (i) when and why users are hesitant to adopt these new technologies in their working routines and (ii) how to redesign these tools in such a way that it improves the operational performance of organisations. Furthermore, findings from this research will enable a better orchestration within the predictive maintenance workflow.
5. Methodology
The scientific methodology in PrimaVera is action research [
123], a novel and successful scientific paradigm where theory is not developed first and validated later. Instead, innovative solutions for challenging problems are developed together with stakeholders, through a series of short, iterative cycles. In this way, results provide workable solutions for real issues. Action research also fits well with research practices at the Universities of Applied Sciences (Saxion and THUAS) and the independent research organisation (NLR).
To carry out the principles of action research, the project is centred around three application domains, aligning with the domains of the industrial partners of the project. Each application domain will provide several case studies that involve all stages of the predictive maintenance cycle. This way the project will realise synergy between the research lines and leads to a careful balance between generic and domain-specific maintenance principles.
5.1. Demonstrators
Besides case studies the project will also work on three closely interlinked large scale field demonstrators that are aligned with the application domains of the industrial partners. The work on these demonstrators will span the entire duration of the project and will integrate knowledge, insights, methods and models developed during the project. The three demonstrators are:
Health assessment and prognostics tool for infrastructure related equipment (PLC, e-drive). This demonstrator tool will implement the data collection, diagnostic and prognostic methods into a practical software tool that enables an asset owner to assess the system’s health and predict future failures.
Planning and maintenance tool to optimise service logistics (high-tech). This demonstrator tool will implement the maintenance and supply chain optimisation methods into a user-friendly software tool.
Digital twin to support ship maintenance fed by real-time sensor data (maritime). The digital twin is a computer model representing the physical components and functions of (part of) a real ship, as well as its degradation behaviour. By feeding sensor data from the real ship into its digital twin, the actual status can be used as starting point for the simulation of various scenarios. User-friendly visualisation capabilities then enable to present the present and future status of on-board critical systems, which will support maintenance decision making.
These demonstrators will also function as an important tool to evaluate the applicability and usability of the proposed process model.
Implementation of Demonstrators
During the proposal phase it was already recognised that the work on the three industrial demonstrators is a substantial task which can only be achieved by using existing tools and making it a common goal, requiring a continuously collaboration between all the partners throughout the whole project. The DevOps approach is highly suited to meet these requirements as cross-functional teams work on continuous operational feature deliveries [
124].
To manage the amount of work, one generic framework is built on which the three demonstrators will be executed. The framework will consist of a separate building block for each of the five stages presented in
Section 4.1, i.e., Data acquisition; Data processing and diagnostics; Prognostics; Maintenance and logistics optimisation and Decisions, forming a complete predictive maintenance cycle. The building blocks will contain the new methodologies developed in each of these five stages as well as existing methodologies. The five stages correspond to the first five work packages in the project.
To implement the framework, each of the five work packages is responsible for delivering their own building block. A separate sixth work package is defined for the integration of all the building blocks in the final framework. To guarantee the integration of the various building blocks, at the beginning of the project already a deliverable with the definition of the building blocks content and their interfaces is defined with input from all the partners and used for further discussion and refined throughout the project. To enhance the quality and functionality of the framework, it will be delivered in three stages throughout the project: a functional prototype, a working prototype and the final version. These are separate deliverables already foreseen in the proposal stage, to which all the partners will contribute.
Similarly, the three demonstrators to which the framework will be applied are being defined from the start of the project. All the involved industrial partners have been visited by the various project partners as a mutual effort, and had led to the three demonstrators mentioned above. Next, the demonstrators will be examined in more detail, for instance for the available sensor data, its quality, and current methods applied by the industrial partners. This reveals missing information in an early stage that can be gathered throughout the project (for instance by applying new sensor technologies) and act as a baseline for the development of improved methodologies throughout the different work packages.
To minimise the effort of the framework implementation, use will be made of existing software tools such as Python, R and Java that come with a plethora of publicly available libraries that provide access to implementations of many advanced algorithms on which the new methods will be build. Furthermore, Docker containers in combination with the above mentioned clear interfaces between the building blocks will be applied to efficiently integrate the different building blocks, various programming languages and tools. Moreover, using Docker results in a reproducible framework [
125] which is scalable, operating system independent and easy to deploy. In addition, using Docker containers also enables the distribution of working systems which contain a mix of proprietary and open software. It should be noted that the PrimaVera project is committed to release code under an open-source licence as much as possible.
6. The Consortium
The PrimaVera consortium consists of a broad multidisciplinary team from academia, industry and an independent research organisation. Academic partners are affiliated with the University of Twente, Eindhoven University of Technology, Radboud University, Saxion University of Applied Sciences and The Hague University of Applied Sciences (THUAS) which are all based in the Netherlands. The independent research organisation Royal Netherlands Aerospace Centre (NLR) is also part of the consortium. The consortium will initiate three closely interlinked large scale field demonstrators that are aligned with three important sectors of the Dutch economy, namely infrastructure, high-tech and maritime. To facilitate these demonstrators the following leading industrial partners, both public and private, have joined the consortium:
- Infrastructure
Rijkswaterstaat, Rolsch Asset Management, Waterboard de Dommel
- High-tech
ASML, Technobis, Nederlandse Spoorwegen, ORTEC
- Maritime
Damen Shipyards, Alfa Laval, Royal IHC, Royal Netherlands Navy
7. Conclusions
The overarching challenge of the PrimaVera project is to leverage all individual building blocks of predictive maintenance into an effective and efficient framework that supports optimal maintenance and asset management in a complex arena. To realise this goal, the project has identified four cross cutting challenges to tackle that thus far have hindered effective solutions to predictive maintenance. These four challenges are the lack of orchestration and automation of the predictive maintenance workflow, inaccurate or incomplete data and the role of human and organisational factors in data-driven decision support tools.
To tackle these challenges, the PrimaVera project introduces an intuitive generic process model which provides a structured approach to predictive maintenance projects. The results of the PrimaVera project will synergise the individual building blocks of predictive maintenance and will pave the way towards utilising predictive maintenance at its full potential, achieving higher availability of assets at lower cost.
Author Contributions
Writing—original draft preparation, B.T.; writing—review and editing, M.S., R.B., J.B. (Jan Braaksma), T.T., A.D.B., P.v.d.C., W.T., F.G.; conceptualisation, J.B. (John Bolte), T.H., N.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partly funded by Nederlandse Organisatie voor Wetenschappelijk Onderzoek (NWO) grant number NWA.1160.18.238 and co-funding from the participating consortium members. The Article Processing Charges (APC) was funded by the University of Twente.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Mobley, R.K. An Introduction to Predictive Maintenance, 2nd ed.; Butterworth-Heinemann: Oxford, UK, 2002. [Google Scholar] [CrossRef]
- Lee, J.; Kao, H.A.; Yang, S. Service Innovation and Smart Analytics for Industry 4.0 and Big Data Environment. Procedia CIRP 2014, 16, 3–8. [Google Scholar] [CrossRef] [Green Version]
- Thomas, D.S. The Costs and Benefits of Advanced Maintenance in Manufacturing; Advanced Manufacturing Series (NIST AMS 100-18); US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018. [CrossRef]
- Tiddens, W.W.; Braaksma, A.J.J.; Tinga, T. The adoption of prognostic technologies in maintenance decision making: A multiple case study. Procedia CIRP 2015, 38, 171–176. [Google Scholar] [CrossRef] [Green Version]
- De Jonge, B.; Scarf, P. A review on maintenance optimization. Eur. J. Oper. Res. 2020, 285, 805–824. [Google Scholar] [CrossRef]
- Kowalkowski, C.; Gebauer, H.; Oliva, R. Service growth in product firms: Past, present, and future. Ind. Mark. Manag. 2017, 60, 82–88. [Google Scholar] [CrossRef]
- Sipos, R.; Fradkin, D.; Moerchen, F.; Wang, Z. Log-based predictive maintenance. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1867–1876. [Google Scholar] [CrossRef]
- McFadden, P.; Smith, J. Vibration monitoring of rolling element bearings by the high-frequency resonance technique—A review. Tribol. Int. 1984, 17, 3–10. [Google Scholar] [CrossRef]
- Atat, R.; Liu, L.; Wu, J.; Li, G.; Ye, C.; Yang, Y. Big Data Meet Cyber-Physical Systems: A Panoramic Survey. IEEE Access 2018, 6, 73603–73636. [Google Scholar] [CrossRef]
- Wagner, C.; Hellingrath, B. Implementing Predictive Maintenance in a Company: Industry Insights with Expert Interviews. In Proceedings of the 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Shearer, C. The CRISP-DM Model: The New Blueprint for Data Mining. J. Data Warehous. 2000, 5, 13–22. [Google Scholar]
- Guo, H.Y.; Zhang, L.; Zhang, L.L.; Zhou, J.X. Optimal placement of sensors for structural health monitoring using improved genetic algorithms. Smart Mater. Struct. 2004, 13, 528–534. [Google Scholar] [CrossRef] [Green Version]
- Yi, T.H.; Li, H.N.; Gu, M. A new method for optimal selection of sensor location on a high-rise building using simplified finite element model. Struct. Eng. Mech. 2011, 37, 671–684. [Google Scholar] [CrossRef]
- Debouk, R.; Lafortune, S.; Teneketzis, D. On an optimization problem in sensor selection for failure diagnosis. In Proceedings of the 38th IEEE Conference on Decision and Control (Cat. No.99CH36304), Phoenix, AZ, USA, 7–10 December 1999; Volume 5, pp. 4990–4995. [Google Scholar]
- Molodova, M.; Oregui, M.; Nunez, A.; Li, Z.; Moraal, J.; Dollevoet, R. Axle box acceleration for health monitoring of insulated joints: A case study in the Netherlands. In Proceedings of the 17th IEEE International Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014. [Google Scholar] [CrossRef]
- Feng, M.; Fukuda, Y.; Mizuta, M.; Ozer, E. Citizen Sensors for SHM: Use of Accelerometer Data from Smartphones. Sensors 2015, 15, 2980–2998. [Google Scholar] [CrossRef] [Green Version]
- Seraj, F.; Meratnia, N.; Havinga, P.J. RoVi: Continuous transport infrastructure monitoring framework for preventive maintenance. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications (PerCom), Kona, HI, USA, 13–17 March 2017. [Google Scholar] [CrossRef]
- Alani, A.M.; Tosti, F.; Ciampoli, L.B.; Gagliardi, V.; Benedetto, A. An integrated investigative approach in health monitoring of masonry arch bridges using GPR and InSAR technologies. NDT E Int. 2020, 115. [Google Scholar] [CrossRef]
- Kusiak, A. Smart manufacturing. Int. J. Prod. Res. 2018, 56, 508–517. [Google Scholar] [CrossRef]
- Donders, A.; Van Der Heijden, G.J.; Stijnen, T.; Moons, K.G. A gentle introduction to imputation of missing values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef] [PubMed]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 793. [Google Scholar]
- Koopmans, F.; Cornelisse, L.N.; Heskes, T.; Dijkstra, T.M. Empirical Bayesian random censoring threshold model improves detection of differentially abundant proteins. J. Proteome Res. 2014, 13, 3871–3880. [Google Scholar] [CrossRef]
- Cui, R.; Bucur, I.G.; Groot, P.; Heskes, T. A novel Bayesian approach for latent variable modeling from mixed data with missing values. Stat. Comput. 2019, 29, 977–993. [Google Scholar] [CrossRef] [Green Version]
- Cui, R.; Groot, P.; Heskes, T. Learning causal structure from mixed data with missing values using Gaussian copula models. Stat. Comput. 2019, 29, 311–333. [Google Scholar] [CrossRef] [Green Version]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717. [Google Scholar] [CrossRef] [Green Version]
- Mardani, M.; Mateos, G.; Giannakis, G.B. Subspace learning and imputation for streaming big data matrices and tensors. IEEE Trans. Signal Process. 2015, 63, 2663–2677. [Google Scholar] [CrossRef] [Green Version]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Proceedings of the 23rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 2080–2088. [Google Scholar]
- Xiong, L.; Chen, X.; Schneider, J. Direct robust matrix factorization for anomaly detection. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 844–853. [Google Scholar] [CrossRef]
- Weese, M.; Martinez, W.; Megahed, F.M.; Jones-Farmer, L.A. Statistical Learning Methods Applied to Process Monitoring: An Overview and Perspective. J. Qual. Technol. 2016, 48, 4–24. [Google Scholar] [CrossRef]
- Capizzi, G.; Masarotto, G. A least angle regression control chart for multidimensional data. Technometrics 2011, 53, 285–296. [Google Scholar] [CrossRef]
- Kenbeek, T.; Kapodistria, S.; Di Bucchianico, A. Data-driven online monitoring of wind turbines. In Proceedings of the 12th EAI International Conference on Performance Evaluation Methodologies and Tools, Palma de Mallorca, Spain, 13–15 March 2019; pp. 143–150. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Long, H.; Zhang, Z.; Xu, J.; Liu, R. Wind turbine gearbox failure monitoring based on SCADA data analysis. In Proceedings of the Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016; pp. 1–5. [Google Scholar]
- Tinga, T.; Loendersloot, R. Physical Model-Based Prognostics and Health Monitoring to Enable Predictive Maintenance. In Predictive Maintenance in Dynamic Systems; Lughofer, E., Sayed-Mouchaweh, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 313–353. [Google Scholar] [CrossRef]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect; Basic Books: New York, NY, USA, 2018. [Google Scholar]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [Green Version]
- Sigtermans, D.; Fussenich, R.; Kielczewski, A.; Zalmijn, E.; Brunt, M.; Voinea, S.L. Methods of Modelling Systems or Performing Predictive Maintenance of Lithographic Systems. U.S. Patent Application No. 15/760228, 20 November 2018. [Google Scholar]
- Claassen, T.; Heskes, T. A Bayesian approach to constraint based causal inference. In Proceedings of the UAI 2012, 28th Conference on Uncertainty in Artificial Intelligence, Catalina Island, CA, USA, 15–17 August 2012; pp. 207–216. [Google Scholar]
- Spirtes, P.; Zhang, K. Causal discovery and inference: Concepts and recent methodological advances. In Applied Informatics; Springer: Berlin/Heidelberg, Germany, 2016; Volume 3. [Google Scholar] [CrossRef] [Green Version]
- Hlinka, J.; Hartman, D.; Vejmelka, M.; Runge, J.; Marwan, N.; Kurths, J.; Paluš, M. Reliability of inference of directed climate networks using conditional mutual information. Entropy 2013, 15, 2023–2045. [Google Scholar] [CrossRef]
- Vicente, R.; Wibral, M.; Lindner, M.; Pipa, G. Transfer entropy—A model-free measure of effective connectivity for the neurosciences. J. Comput. Neurosci. 2011, 30, 45–67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sachs, K.; Perez, O.; Pe’er, D.; Lauffenburger, D.A.; Nolan, G.P. Causal protein-signaling networks derived from multiparameter single-cell data. Science 2005, 308, 523–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sokolova, E.; Oerlemans, A.M.; Rommelse, N.N.; Groot, P.; Hartman, C.A.; Glennon, J.C.; Claassen, T.; Heskes, T.; Buitelaar, J.K. A causal and mediation analysis of the comorbidity between attention deficit hyperactivity disorder (ADHD) and autism spectrum disorder (ASD). J. Autism Dev. Disord. 2017, 47, 1595–1604. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rommel, D.; Di Maio, D.; Tinga, T. Calculating loads and life-time reduction of wind turbine gearbox and generator bearings due to shaft misalignment. Wind Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
- Meghoe, A.; Loendersloot, R.; Tinga, T. Rail wear and remaining life prediction using meta-models. Int. J. Rail Transp. 2020, 8, 1–26. [Google Scholar] [CrossRef]
- Woldman, M.; Tinga, T.; van der Heide, E.; Masen, M. Abrasive wear based predictive maintenance for systems operating in sandy conditions. Wear 2015, 338–339, 316–324. [Google Scholar] [CrossRef]
- Ruijters, E.; Guck, D.; Drolenga, P.; Peters, M.; Stoelinga, M. Maintenance analysis and optimization via statistical model checking: Evaluating a train pneumatic compressor. In Proceedings of the QEST 2016: 13th International Conference on Quantitative Evaluation of SysTems, Québec City, QC, Canada, 23–25 August 2016; Agha, G., Van Houdt, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 331–347. [Google Scholar]
- Tinga, T. Application of physical failure models to enable usage and load based maintenance. Reliab. Eng. Syst. Saf. 2010, 95, 1061–1075. [Google Scholar] [CrossRef]
- Tiddens, W.W.; Braaksma, A.J.J.; Tinga, T. Towards Informed Maintenance Decision Making: Guiding the Application of Advanced Maintenance Analyses. In Optimum Decision Making in Asset Management; IGI Global: Hershey, PA, USA, 2016; Chapter 13; pp. 288–309. [Google Scholar] [CrossRef]
- ten Zeldam, S.; de Jong, A.; Loendersloot, R.; Tinga, T. Automated Failure Diagnosis in Aviation Maintenance Using eXplainable Artificial Intelligence (XAI). In Proceedings of the European Conference of the PHM Society, 4th European Conference of the Prognostics and Health Management Society, PHME 2018—Muntgebouw Utrecht, Utrecht, The Netherlands, 3–6 July 2018; Volume 4. [Google Scholar]
- Barlow, R.; Hunter, L. Optimum preventive maintenance policies. Oper. Res. 1960, 8, 90–100. [Google Scholar] [CrossRef]
- Olde Keizer, M.C.; Flapper, S.D.P.; Teunter, R.H. Condition-based maintenance policies for systems with multiple dependent components: A review. Eur. J. Oper. Res. 2017, 261, 405–420. [Google Scholar] [CrossRef]
- Zhu, Q. Maintenance Optimization for Multi-Component Systems under Condition Monitoring. Ph.D. Thesis, Eindhoven University of Technology, Eindhoven, The Netherlands, 2015. [Google Scholar]
- Arts, J.; Basten, R. Design of multi-component periodic maintenance programs with single-component models. IISE Trans. 2018, 50, 606–615. [Google Scholar] [CrossRef] [Green Version]
- Van Horenbeek, A.; Buré, J.; Cattrysse, D.; Pintelon, L.; Vansteenwegen, P. Joint maintenance and inventory optimization systems: A review. Int. J. Prod. Econ. 2013, 143, 499–508. [Google Scholar] [CrossRef]
- Basten, R.; Ryan, J. The value of maintenance delay flexibility for improved spare parts inventory management. Eur. J. Oper. Res. 2019, 278, 646–657. [Google Scholar] [CrossRef]
- uit het Broek, M.A.; Teunter, R.H.; de Jonge, B.; Veldman, J.; Van Foreest, N.D. Condition-based production planning: Adjusting production rates to balance output and failure risk. Manuf. Serv. Oper. Manag. 2019, 22, 645–867. [Google Scholar] [CrossRef] [Green Version]
- Karabağ, O.; Eruguz, A.S.; Basten, R. Integrated optimization of maintenance interventions and spare part selection for a partially observable multi-component system. Reliab. Eng. Syst. Saf. 2020, 200, 106955. [Google Scholar] [CrossRef]
- Carr, S.; Jansen, N.; Wimmer, R.; Serban, A.C.; Becker, B.; Topcu, U. Counterexample-Guided Strategy Improvement for POMDPs Using Recurrent Neural Networks. arXiv 2019, arXiv:1903.08428. [Google Scholar]
- Ravdeep, K.; Adithya, T.; Sarbjeet, S.; Martinetti, A. Big Data Analytics for Maintaining Transportation Systems. In Transportation Systems; Springer: Berlin/Heidelberg, Germany, 2004; Chapter 6; pp. 85-1–85-11. [Google Scholar] [CrossRef]
- van de Kerkhof, R. It’s about Time: Managing Implementation Dynamics of Condition-Based Maintenance. Ph.D. Thesis, University of Tilburg, Tilburg, The Netherlands, 2020. [Google Scholar]
- Garg, A.; Deshmukh, S.G. Maintenance management: Literature review and directions. J. Qual. Maint. Eng. 2006, 12, 205–238. [Google Scholar] [CrossRef]
- van de Kerkhof, R.; Akkermans, H.A. Noorderhaven, N. Knowledge Lost in Data: Organizational Impediments to Condition-Based Maintenance in the Process Industry. In Logistics and Supply Chain Innovation; Springer: Berline/Heidelberg, Germany, 2015; p. 19. [Google Scholar]
- Veldman, J.; Wortmann, H.; Klingenberg, W. Typology of condition based maintenance. J. Qual. Maint. Eng. 2011, 17, 183–202. [Google Scholar] [CrossRef]
- Tiddens, W.W.; Braaksma, A.J.J.; Tinga, T. Selecting Suitable Candidates for Predictive Maintenance. Int. J. Progn. Health Manag. 2018, 9, 20. [Google Scholar]
- Ruitenburg, R.J.; Braaksma, A.J.J. Mitigating change in the goals and context of capital assets: Design of the Lifetime Impact Identification Analysis. CIRP J. Manuf. Sci. Technol. 2017, 17, 50–59. [Google Scholar] [CrossRef]
- Koochaki, J. CBM in Multi-Component Systems. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2012. Available online: https://www.rug.nl/ (accessed on 31 July 2020).
- Martinetti, A.; Moerman, J.J.; van Dongen, L.A. Storytelling as a strategy in managing complex systems: Using antifragility for handling an uncertain future in reliability. Saf. Reliab. 2017, 37, 233–247. [Google Scholar] [CrossRef] [Green Version]
- van Aken, J.E.; Chandrasekaran, A.; Halman, J. Conducting and publishing design science research: Inaugural essay of the design science department of the Journal of Operations Management. J. Oper. Manag. 2016, 47–48, 1–8. [Google Scholar] [CrossRef]
- Wieringa, R.J. Design science methodology: For information systems and software engineering. In Design Science Methodology: For Information Systems and Software Engineering; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–332. [Google Scholar] [CrossRef] [Green Version]
- Bendoly, E.; Donohue, K.; Schultz, K.L. Behavior in operations management: Assessing recent findings and revisiting old assumptions. J. Oper. Manag. 2006, 24, 737–752. [Google Scholar] [CrossRef]
- Gino, F.; Pisano, G. Toward a Theory of Behavioral Operations. Manuf. Serv. Oper. Manag. 2008, 10, 676–691. [Google Scholar] [CrossRef]
- von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior. J. Philos. 1945, 42, 550. [Google Scholar] [CrossRef]
- Donohue, K.; Özer, Ö.; Zheng, Y. Behavioral Operations: Past, Present, and Future. Manuf. Serv. Oper. Manag. 2020, 22, 191–202. [Google Scholar] [CrossRef] [Green Version]
- Dietvorst, B.J.; Simmons, J.P.; Massey, C. Algorithm aversion: People erroneously avoid algorithms after seeing them err. J. Exp. Psychol. Gen. 2015, 144, 114–126. [Google Scholar] [CrossRef] [Green Version]
- Efendić, E.; Van de Calseyde, P.P.; Evans, A.M. Slow response times undermine trust in algorithmic (but not human) predictions. Organ. Behav. Hum. Decis. Process. 2020, 157, 103–114. [Google Scholar] [CrossRef] [Green Version]
- Manyika, J.; Chui, M.; Bisson, P.; Woetzel, J.; Dobbs, R.; Bughin, J.; Aharon, D. The Internet of Things: Mapping the Value beyond the Hype; Technical Report; McKinsey Global Institute: New York, NY, USA, 2015. [Google Scholar]
- Haarman, M.; Mulders, M.; Vassiliadis, C. Predictive Maintenance 4.0: Predict the Unpredictable; Technical Report; PwC Netherlands and Mainnovation: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Bokrantz, J.; Skoogh, A.; Berlin, C.; Stahre, J. Maintenance in digitalised manufacturing: Delphi-based scenarios for 2030. Int. J. Prod. Econ. 2017, 191, 154–169. [Google Scholar] [CrossRef]
- Heng, A.; Zhang, S.; Tan, A.C.; Mathew, J. Rotating machinery prognostics: State of the art, challenges and opportunities. Mech. Syst. Signal Process. 2009, 23, 724–739. [Google Scholar] [CrossRef]
- Kipper, L.M.; Furstenau, L.B.; Hoppe, D.; Frozza, R.; Iepsen, S. Scopus scientific mapping production in industry 4.0 (2011–2018): A bibliometric analysis. Int. J. Prod. Res. 2020, 58, 1605–1627. [Google Scholar] [CrossRef]
- Sun, B.; Zeng, S.; Kang, R.; Pecht, M.G. Benefits and Challenges of System Prognostics. IEEE Trans. Reliab. 2012, 61, 323–335. [Google Scholar] [CrossRef]
- Jardine, A.K.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Javed, K.; Gouriveau, R.; Zerhouni, N.; Nectoux, P. Enabling Health Monitoring Approach Based on Vibration Data for Accurate Prognostics. IEEE Trans. Ind. Electron. 2015, 62, 647–656. [Google Scholar] [CrossRef] [Green Version]
- Vachtsevanos, G.; Goebel, K. Introduction to Prognostics. 2015. Available online: https://www.phmsociety.org/sites/phmsociety.org/files/PROGNOSTICS_TUTORIAL.pdf (accessed on 23 November 2020).
- Vachtsevanos, G.J.; Valavanis, K.P. A Novel Approach to Integrated Vehicle Health Management; Technical Report; NATO STO: Brussels, Belgium, 2018. [Google Scholar] [CrossRef]
- Benedettini, O.; Baines, T.S.; Lightfoot, H.W.; Greenough, R.M. State-of-the-art in integrated vehicle health management. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2009, 223, 157–170. [Google Scholar] [CrossRef] [Green Version]
- Ran, Y.; Zhou, X.; Lin, P.; Wen, Y.; Deng, R. A Survey of Predictive Maintenance: Systems, Purposes and Approaches. arXiv 2019, arXiv:eess.SP/1912.07383. [Google Scholar]
- Lee, J.; Jin, C.; Liu, Z.; Davari Ardakani, H. Introduction to Data-Driven Methodologies for Prognostics and Health Management. In Probabilistic Prognostics and Health Management of Energy Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 9–32. [Google Scholar] [CrossRef]
- Jin, X.; Siegel, D.; Weiss, B.A.; Gamel, E.; Wang, W.; Lee, J.; Ni, J. The present status and future growth of maintenance in US manufacturing: Results from a pilot survey. Manuf. Rev. 2016, 3, 10. [Google Scholar] [CrossRef] [Green Version]
- Hevner, A.; March, S.T.; Park, J.; Ram, S. Design Science in Information Systems Research. MIS Q. 2004, 28, 75. [Google Scholar] [CrossRef] [Green Version]
- Peffers, K.; Tuunanen, T.; Rothenberger, M.A.; Chatterjee, S. A Design Science Research Methodology for Information Systems Research. J. Manag. Inf. Syst. 2007, 24, 45–77. [Google Scholar] [CrossRef]
- Asset Management—Overview, Principles and Terminology; Standard, International Organization for Standardization: Geneva, Switzerland, 2014.
- Tiddens, W.W.; Braaksma, J.; Tinga, T. Exploring predictive maintenance applications in industry. J. Qual. Maint. Eng. 2020. [Google Scholar] [CrossRef]
- Gupta, V.; Sharma, M.; Thakur, N. Optimization Criteria for Optimal Placement of Piezoelectric Sensors and Actuators on a Smart Structure: A Technical Review. J. Intell. Mater. Syst. Struct. 2010, 21, 1227–1243. [Google Scholar] [CrossRef]
- Ribeiro, F. Machinery Fault Database. 2017. Available online: http://www02.smt.ufrj.br/~offshore/mfs/index.html (accessed on 11 September 2020).
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Sankararaman, S.; Goebel, K. Uncertainty in prognostics and systems health management. Int. J. Progn. Health Manag. 2015, 6. [Google Scholar]
- Liu, D.; Luo, Y.; Peng, Y. Uncertainty processing in prognostics and health management: An overview. In Proceedings of the IEEE 2012 Prognostics and System Health Management Conference (PHM-2012 Beijing), Beijing, China, 23–25 May 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Ng, K.C.; Abramson, B. Uncertainty management in expert systems. IEEE Expert 1990, 5, 29–48. [Google Scholar] [CrossRef]
- van der Hofstad, R. Random Graphs and Complex Networks; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar] [CrossRef] [Green Version]
- Imbens, G.W.; Rubin, D.B. Causal Inference for Statistics, Social, and Biomedical Sciences; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar] [CrossRef]
- Kenett, R.S. On generating high InfoQ with Bayesian networks. Qual. Technol. Quant. Manag. 2016, 13, 309–332. [Google Scholar] [CrossRef]
- Nielsen, T.D.; Jensen, F.V. Bayesian Networks and Decision Graphs; Springer: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Ding, M.; Chen, Y.; Bressler, S.L. Granger Causality: Basic Theory and Application to Neuroscience. In Handbook of Time Series Analysis; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2006; Chapter 17; pp. 437–460. [Google Scholar] [CrossRef] [Green Version]
- Duan, P.; Yang, F.; Chen, T.; Shah, S.L. Direct Causality Detection via the Transfer Entropy Approach. IEEE Trans. Control Syst. Technol. 2013, 21, 2052–2066. [Google Scholar] [CrossRef]
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Schwabacher, M.; Goebel, K. A Survey of Artificial Intelligence for Prognostics; Aritficial Intelligence for Prognostics; The AAAI Press: Menlo Park, CA, USA, 2007; pp. 108–115. [Google Scholar]
- Tinga, T. Principles of Loads and Failure Mechanisms; Springer: London, UK, 2013. [Google Scholar] [CrossRef]
- Ruijters, E.; Guck, D.; Drolenga, P.; Stoelinga, M. Fault maintenance trees: Reliability centered maintenance via statistical model checking. In Proceedings of the 2016 Annual Reliability and Maintainability Symposium (RAMS), Tucson, AZ, USA, 25–28 January 2016; pp. 1–6. [Google Scholar]
- Nauta, M.; Bucur, D.; Stoelinga, M. LIFT: Learning Fault Trees from Observational Data. In Proceedings of the 15th International Conference on Quantitative Evaluation of Systems; Lecture Notes in Computer Science; McIver, A., Horváth, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11024, pp. 306–322. [Google Scholar] [CrossRef] [Green Version]
- Linard, A.; Bucur, D.; Stoelinga, M. Fault Trees from Data: Efficient Learning with an Evolutionary Algorithm. In Proceedings of the 5th International Symposium on Dependable Software Engineering: Theories, Tools, and Applications SETTA; Lecture Notes in Computer Science; Guan, N., Katoen, J., Sun, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11951, pp. 19–37. [Google Scholar] [CrossRef] [Green Version]
- Yamada, S.; Osaki, S. Software Reliability Growth Modeling: Models and Applications. IEEE Trans. Softw. Eng. 1985, SE-11, 1431–1437. [Google Scholar] [CrossRef]
- Jatain, A.; Mehta, Y. Metrics and models for Software Reliability: A systematic review. In Proceedings of the International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT), Ghaziabad, India, 7–8 February 2014; pp. 210–214. [Google Scholar] [CrossRef]
- Tian, L.; Noore, A. Evolutionary neural network modeling for software cumulative failure time prediction. Reliab. Eng. Syst. Saf. 2005, 87, 45–51. [Google Scholar] [CrossRef]
- Li, Z. Using Data Mining Techniques to Improve Software Reliability. Ph.D. Thesis, University of Illinois, Champaign, IL, USA, 2006. [Google Scholar]
- Heijblom, R.; Postma, W.; Natarajan, V.; Stoelinga, M. DFT Analysis Incorporating Spare Parts in Fault Trees. In Proceedings of the 2018 Annual Reliability and Maintainability Symposium (RAMS), Reno, NV, USA, 22–25 January 2018; pp. 1–7. [Google Scholar]
- Basten, R.J.I.; van Houtum, G.J. System-oriented inventory models for spare parts. Surv. Oper. Res. Manag. Sci. 2014, 19, 34–55. [Google Scholar] [CrossRef] [Green Version]
- Häkkinen, L.; Hilmola, O. Life after ERP implementation: Long-term development of user perceptions of system success in an after-sales environment. J. Enterp. Inf. Manag. 2008, 21, 285–310. [Google Scholar] [CrossRef]
- Venkatesh, V.; Bala, H. Technology Acceptance Model 3 and a Research Agenda on Interventions. Decis. Sci. 2008, 39, 273–315. [Google Scholar] [CrossRef] [Green Version]
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. User Acceptance of Information Technology: Toward a Unified View. Manag. Inf. Syst. Q. 2003, 27. [Google Scholar] [CrossRef] [Green Version]
- Wiers, V. The relationship between shop floor autonomy and APS implementation success: Evidence from two cases. Prod. Plan. Control 2009, 20, 576–585. [Google Scholar] [CrossRef]
- Fildes, R.; Goodwin, P.; Lawrence, M.; Nikolopoulos, K. Effective forecasting and judgmental adjustments: An empirical evaluation and strategies for improvement in supply-chain planning. Int. J. Forecast. 2009, 25, 3–23. [Google Scholar] [CrossRef]
- Stringer, E. Action Research, 4th ed.; SAGE Publications, Inc.: Los Angeles, CA, USA, 2013. [Google Scholar]
- Ebert, C.; Gallardo, G.; Hernantes, J.; Serrano, N. DevOps. IEEE Softw. 2016, 33, 94–100. [Google Scholar] [CrossRef]
- Boettiger, C. An Introduction to Docker for Reproducible Research. SIGOPS Oper. Syst. Rev. 2015, 49, 71–79. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).

 ,
, {kind=link}
